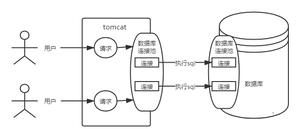
InnoDBBufferPool

Buffer Pool本质上是InnoDB向操作系统申请的一段连续的内存空间,可以通过innodb_buffer_pool_size来调整它的大小。
Buffer Pool内部组成:Buffer Pool向操作系统申请的连续内存由控制块和缓存页组成,每个控制块和缓存页都是一一对应的,在填充足够多的控制块和缓存页的组合后,Buffer Pool剩余的空间可能产生不够填充一组控制块和缓存页,这部分空间不能被使用,也被称为碎片。InnoDB使用了许多链表来管理Buffer Pool。
Free链表:free链表中每一个节点都代表一个空闲的缓存页,在将磁盘中的页加载到Buffer Pool时,会从free链表中寻找空闲的缓存页。
链表基节点:MySQL通过基节点管理free链表,MySQL为基节点单独申请了40字节的空间,不包含在Buffer Pool内
缓存页查询与定位:为了快速定位某个页是否被加载到Buffer Pool,使用表空间号 + 页号作为key,缓存页作为value,建立哈希表。
Flush链表:在Buffer Pool中被修改的页称为脏页,脏页并不是立即刷新到磁盘上,而是被加入到flush链表中,待之后的某个时刻同步到磁盘上。
LRU链表:通过最近最少使用原则淘汰缓存页,释放缓存空间,使用到某个缓存页,就把该缓存页调整到LRU链表头部,尾部为最近最少使用缓存页。
InnoDB预读机制:
- 线性预读,顺序访问某个区的页面超过了系统变量的值,就会触发一次异步读取下一区中全部页面到Buffer Pool的请求。
- 随机预读:随机缓存了某个区的13个连续页面,会触发异步读取本区所有页面到Buffer Pool的请求。
- 预读可能造成的问题:预读的无用页都加载到了Buffer Pool,导致有用的页被挤到链表尾部淘汰掉了。还有一种可能就是全表扫描,表中记录很多,占用的页很多,导致这些页也加载到Buffer Pool,挤掉有用的缓存页。
- 应对方法:LRU链表分为(young区域 | 热数据:使用频率非常高的缓存页)和(old区域 | 冷数据:使用频率不高的缓存页),可以通过innodb_old_bloc ks_pct来调节old区域所占的比例。首次从磁盘上加载到Buffer Pool的页会被放到old区域的头部,在innodb_old_blocks_time间隔时间内访问该页不会把它移动到young区域头部。在Buffer Pool没有可用的空闲缓存页时,会首先淘汰掉old区域的一些页。
- 为了减少young链表频繁移动的开销,只有访问的缓存页位于young区域的后四分之三位置才能提升性能。
其他的一些链表:
- unzip LRU链表:管理解压页
- zip clean链表:管理未解压页
- zip free数组:每个元素都代表一个链表
数据库后台专门线程负责将LRU链表尾部的部分脏页和Flush链表中的脏页刷新到磁盘。
Buffer Pool特别大且多线程并发访问量高,单一的Buffer Pool可能会影响请求的处理速度,因此当Buffer Pool特别大的时候,可以把它们拆分成若干小的Buffer Pool,可以通过指定innodb_buffer_pool_instances来控制Buffer Pool实例的个数,每个Buffer Pool实例中都有各自独立的链表,互不干扰。
自MySQL 5.7.5版本之后,可以在服务器运行过程中调整Buffer Pool大小。每个Buffer Pool实例由若干个chunk组成,每个chunk的大小可以在服务器启动时通过启动参数调整。由于基节点的原因,实际空间比chunk要大5%。
innodb_buffer_pool_size必须是innodb_buffer_pool_chunk_size × innodb_ buffer_pool_instances的倍数,且MySQL会根据一定的逻辑自动调节大小
查看Buffer Pool的状态信息:SHOW ENGINE INNODB STATUSG
以上是 InnoDBBufferPool 的全部内容, 来源链接: utcz.com/z/533833.html