数据库学习之八:mysql基础优化索引管理

八、mysql 基础优化-索引管理
1、课程大纲
索引介绍
索引管理
2、执行计划获取及分析
mysql数据库中索引的类型介绍BTREE:B+树索引 (主要)
HASH:HASH索引
FULLTEXT:全文索引
RTREE:R树索引
------
索引管理:
索引建立的在表的列上(字段)的。
在where后面的列建立索引才会加快查询速度。
索引分类:
- 主键索引
- 普通索引****
- 唯一索引
添加索引
alter table test add index index_name(name);
create index index_name on test(name);
查询表是否有索引信息:
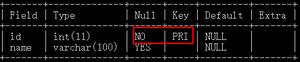
DESC stu;看他的key列值
mysql> explain select * from stu;
mysql> explain select * from stu where stu_name="zhangsan";
查看到的type不同。
----------------------------------------------------------
索引及执行计划
索引基本管理:
创建和删除:
alter table stu add index idx_name(stu_name);
alter table stu drop index idx_name;
或者
create index inx_name on stu(stu_name);
drop index inx_name on stu;
查询索引设置
desc stu;
主键索引: 唯一、非空
走主键索引的查询效率是最高的,我们尽量每个表有一个主键,并且将来查询的时候计量以主键为条件查询
CREATE TABLE `test` (
`id` int(4) NOT NULL AUTO_INCREMENT,
`name` char(20) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=UTF8;
CREATE TABLE `test1` (
`id` int(4) NOT NULL,
`name` char(20) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=UTF8;
增加自增主键
alter table test1 change id id int(4) primary key not null auto_increment;
前缀索引:
create index index_name on stu(stu_id(8));
联合索引:
where a女生 and b身高165 and c身材好
index(a,b,c)
特点:前缀生效特性。
a,ab,abc,ac 可以走索引。
b bc c 不走索引。
原则:把最常用来作为条件查询的列放在前面。
走索引:
select * from people where a="nv" and b>=165 and tizhong<=120;
select * from people where a="nv" and b>=165;
select * from people where a="nv";
select * from people where a="nv" and tizhong<=120;
alter table stu add index minx(gender,age);
唯一性索引:
create unique index index_name on test(name);
3、explain 调取语句的执行计划
主要是判断语句是否走索引explain select stu_name,gender,age from stu where gender="F" and age <20;
mysql> explain select name,gender,age from test where gender="F" and age <20;
+----+-------------+-------+-------+---------------+----------+---------+------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+----------+---------+------+------+-----------------------+
| 1 | SIMPLE | test | range | inx_test | inx_test | 7 | NULL | 1 | Using index condition |
type : 表示MySQL在表中找到所需行的方式,又称“访问类型”,
常见类型如下:
ALL,index, range, ref, eq_ref, const, system, NULL
从左到右,性能从最差到最好
ALL:
Full Table Scan, MySQL将遍历全表以找到匹配的行
如果显示ALL,说明:
查询没有走索引:
1、语句本身的问题
2、索引的问题,没建立索引
index:Full Index Scan,index与ALL区别为index类型只遍历索引树
例子:
explain select count(*) from stu ;
range:索引范围扫描,对索引的扫描开始于某一点,返回匹配值域的行。
显而易见的索引范围扫描是带有between或者where子句里带有<,>查询。
where 条件中有范围查询或模糊查询时
> < >= <= between and in () or
like "xx%"
当mysql使用索引去查找一系列值时,例如IN()和OR列表,也会显示range(范围扫描),当然性能上面是有差异的。
ref:使用非唯一索引扫描或者唯一索引的前缀扫描,返回匹配某个单独值的记录行
where stu_name="xiaoming"
explain select * from stu where stu_name="aa";
eq_ref:类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,简单来说,
就是多表连接中使用primary key或者 unique key作为关联条件
join条件使用的是primary key或者 unique key
const、system:当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。
如将主键置于where列表中,MySQL就能将该查询转换为一个常量
explain select * from city where id=1;
NULL:MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,
例如从一个索引列里选取最小值可以通过单独索引查找完成。
mysql> explain select name,population from city;
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
| 1 | SIMPLE | city | ALL | NULL | NULL | NULL | NULL | 4188 | NULL |
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
Extra:
Using temporary
Using filesort
Using join buffer
排序 order by ,group by ,distinct,排序条件上没有索引
explain select * from city where countrycode="CHN" order by population;
在join 的条件列上没有建立索引
4、数据库索引的设计原则:
一、数据库索引的设计原则: 为了使索引的使用效率更高,在创建索引时,必须考虑在哪些字段上创建索引和创建什么类型的索引。
那么索引设计原则又是怎样的?(尽量使用主键索引和唯一性索引。)
1.选择唯一性索引
唯一性索引的值是唯一的,可以更快速的通过该索引来确定某条记录。
例如,学生表中学号是具有唯一性的字段。为该字段建立唯一性索引可以很快的确定某个学生的信息。
如果使用姓名的话,可能存在同名现象,从而降低查询速度。
主键索引和唯一键索引,在查询中使用是效率最高的。
2.为经常需要排序、分组和联合操作的字段建立索引
经常需要ORDER BY、GROUP BY、DISTINCT和UNION等操作的字段,排序操作会浪费很多时间。
如果为其建立索引,可以有效地避免排序操作。
3.为常作为查询条件的字段建立索引
如果某个字段经常用来做查询条件,那么该字段的查询速度会影响整个表的查询速度。因此,
为这样的字段建立索引,可以提高整个表的查询速度。
select count(DISTINCT population ) from city;
select count(*) from city;
4.尽量使用前缀来索引
如果索引字段的值很长,最好使用值的前缀来索引。例如,TEXT和BLOG类型的字段,进行全文检索
会很浪费时间。如果只检索字段的前面的若干个字符,这样可以提高检索速度。
------------------------以上的是重点关注的,以下是能保证则保证的--------------------
5.限制索引的数目
索引的数目不是越多越好。每个索引都需要占用磁盘空间,索引越多,需要的磁盘空间就越大。
修改表时,对索引的重构和更新很麻烦。越多的索引,会使更新表变得很浪费时间。
6.尽量使用数据量少的索引
如果索引的值很长,那么查询的速度会受到影响。例如,对一个CHAR(100)类型的字段进行全文
检索需要的时间肯定要比对CHAR(10)类型的字段需要的时间要多。
7.删除不再使用或者很少使用的索引
表中的数据被大量更新,或者数据的使用方式被改变后,原有的一些索引可能不再需要。数据库管理
员应当定期找出这些索引,将它们删除,从而减少索引对更新操作的影响。
5、索引的开发规范
不走索引的情况:重点关注:
1) 没有查询条件,或者查询条件没有建立索引
select * from tab; 全表扫描。
select * from tab where 1=1;
在业务数据库中,特别是数据量比较大的表。
是没有全表扫描这种需求。
1、对用户查看是非常痛苦的。
2、对服务器来讲毁灭性的。
(1)select * from tab;
SQL改写成以下语句:
selec * from tab order by price limit 10 需要在price列上建立索引
(2)
select * from tab where name="zhangsan" name列没有索引
改:
1、换成有索引的列作为查询条件
2、将name列建立索引
2) 查询结果集是原表中的大部分数据,应该是30%以上。
查询的结果集,超过了总数行数30%,优化器觉得就没有必要走索引了。
假如:tab表 id,name id:1-100w ,id列有索引
select * from tab where id>500000;
如果业务允许,可以使用limit控制。
怎么改写 ?
结合业务判断,有没有更好的方式。如果没有更好的改写方案
尽量不要在mysql存放这个数据了。放到redis里面。
3) 索引本身失效,统计数据不真实
索引有自我维护的能力。
对于表内容变化比较频繁的情况下,有可能会出现索引失效。
4) 查询条件使用函数在索引列上,或者对索引列进行运算,运算包括(+,-,*,/,! 等)
例子:
错误的例子:select * from test where id-1=9;
正确的例子:select * from test where id=10;
5)隐式转换导致索引失效.这一点应当引起重视.也是开发中经常会犯的错误.
由于表的字段tu_mdn定义为varchar2(20),但在查询时把该字段作为number类型以where条件传给数据库,
这样会导致索引失效. 错误的例子:select * from test where tu_mdn=13333333333;
正确的例子:select * from test where tu_mdn="13333333333";
------------------------
mysql> alter table tab add index inx_tel(telnum);
Query OK, 0 rows affected (0.03 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> desc tab;
+--------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(20) | YES | | NULL | |
| telnum | varchar(20) | YES | MUL | NULL | |
+--------+-------------+------+-----+---------+-------+
3 rows in set (0.01 sec)
mysql> select * from tab where telnum="1333333";
+------+------+---------+
| id | name | telnum |
+------+------+---------+
| 1 | a | 1333333 |
+------+------+---------+
1 row in set (0.00 sec)
mysql> select * from tab where telnum=1333333;
+------+------+---------+
| id | name | telnum |
+------+------+---------+
| 1 | a | 1333333 |
+------+------+---------+
1 row in set (0.00 sec)
mysql> explain select * from tab where telnum="1333333";
+----+-------------+-------+------+---------------+---------+---------+-------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+---------+---------+-------+------+-----------------------+
| 1 | SIMPLE | tab | ref | inx_tel | inx_tel | 63 | const | 1 | Using index condition |
+----+-------------+-------+------+---------------+---------+---------+-------+------+-----------------------+
1 row in set (0.00 sec)
mysql> explain select * from tab where telnum=1333333;
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | tab | ALL | inx_tel | NULL | NULL | NULL | 2 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.00 sec)
mysql> explain select * from tab where telnum=1555555;
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
| 1 | SIMPLE | tab | ALL | inx_tel | NULL | NULL | NULL | 2 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+------+-------------+
1 row in set (0.00 sec)
mysql> explain select * from tab where telnum="1555555";
+----+-------------+-------+------+---------------+---------+---------+-------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+---------+---------+-------+------+-----------------------+
| 1 | SIMPLE | tab | ref | inx_tel | inx_tel | 63 | const | 1 | Using index condition |
+----+-------------+-------+------+---------------+---------+---------+-------+------+-----------------------+
1 row in set (0.00 sec)
mysql>
------------------------
6)
<> ,not in 不走索引
EXPLAIN SELECT * FROM teltab WHERE telnum <> "110";
EXPLAIN SELECT * FROM teltab WHERE telnum NOT IN ("110","119");
------------
mysql> select * from tab where telnum <> "1555555";
+------+------+---------+
| id | name | telnum |
+------+------+---------+
| 1 | a | 1333333 |
+------+------+---------+
1 row in set (0.00 sec)
mysql> explain select * from tab where telnum <> "1555555";
-----
单独的>,<,in 有可能走,也有可能不走,和结果集有关,尽量结合业务添加limit
or或in 尽量改成union
EXPLAIN SELECT * FROM teltab WHERE telnum IN ("110","119");
改写成:
EXPLAIN SELECT * FROM teltab WHERE telnum="110"
UNION ALL
SELECT * FROM teltab WHERE telnum="119"
-----------------------------------
7) like "%_" 百分号在最前面不走
EXPLAIN SELECT * FROM teltab WHERE telnum LIKE "31%" 走range索引扫描
EXPLAIN SELECT * FROM teltab WHERE telnum LIKE "%110" 不走索引
%linux%类的搜索需求,可以使用elasticsearch
%linux培训%
8) 单独引用复合索引里非第一位置的索引列.
列子:
复合索引:
DROP TABLE t1
CREATE TABLE t1 (id INT,NAME VARCHAR(20),age INT ,sex ENUM("m","f"),money INT);
ALTER TABLE t1 ADD INDEX t1_idx(money,age,sex);
DESC t1
SHOW INDEX FROM t1
走索引的情况测试:
EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE money=30 AND age=30 AND sex="m";
EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE money=30 AND age=30 ;
EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE money=30 AND sex="m"; ----->部分走索引
不走索引的:
EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE age=20
EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE age=30 AND sex="m";
EXPLAIN SELECT NAME,age,sex,money FROM t1 WHERE sex="m";
以上是 数据库学习之八:mysql基础优化索引管理 的全部内容, 来源链接: utcz.com/z/533531.html