redis基础知识点汇总

本文涉及的内容参考下面的大纲,另外版本的问题一般都会指出来。
正文
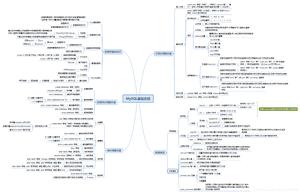
1. 思维导图
简单了做了一个思维导图,详细内容往后看。
2. 详解
下面针对思维导图列出的大纲,展开说明。
2.1 常用的 5 种数据类型
Redis 是基于 C 语言开发的, 不同的数据类型都对应有不同的数据结构, 因为本人对 Java 比较熟悉,
如果用 Java 中的数据结构描述这下面这些数据类型,会是如下这样:
- string
字符串 string 是最简单的数据结构, 内部表示就是一个 字符数组
另外, redis 的字符串是动态字符串,有点类似 Java 的 ArrayList, 感兴趣的可以详细了解下。
- list
Redis 的 list 类似于 Java 中的 LinkedList, 因此 list 的插入和删除操作相对很快, 根据索引查询很慢。
- hash
Redis 的 hash 相当于 Java 中的 HashMap, 是一个无需字典, 内部存储为多个键值对。
- set
Redis 的 set 相当于 Java 中的 HashSet, 因此它的值是无序的,唯一的
- sortedset
sortedset 一方面保证了集合中元素的唯一性,另一方面通过给每个元素设置一个 score(作为排序的依据),实现了排序功能,
上面采用了类比的方式, 描述了 redis 的五种数据类型, 具体用 C 语言如何表示, 可以去下载源码了解一下。
2.2 常用的命令
2.2.1 数据的存储操作
下面是 5 种常用数据类型的部分常用操作指令,查询全部命令,请参考 redis 官网
string
key 为 用户 id, value 为用户具体信息(用 json 串表示)
- 保存或更新一个键值对:
SET user_id user_info(json字符串) - 取出 key 对应的值:
GET user_id - 删除一条数据:
DEL user_id
- 保存或更新一个键值对:
list
存储一个用户列表, 列表元素为用户姓名
- 将一个或多个值插入到列表头部
LPUSH user_list zhangsan lisi wangwu - 移出并获取列表的第一个元素
LPOP name
- 将一个或多个值插入到列表头部
hash
存储用户购物车内容, 大 key 为 用户id, 小 key 为商品 id, value 为商品数量
- 保存一个键-值对
HSET 用户id 商品id 商品数量 - 删除一个哈希表字段
HDEL 用户id 商品id
- 保存一个键-值对
set
存储用户信息, 存储内容为用户姓名, 用户姓名不能重复
- 向集合添加一个成员
SADD name zhangsan - 移除并返回集合中的一个随机元素
SPOP name
- 向集合添加一个成员
sortedset
存储内容同 set 集合一样, 但是增加一个条件,按照年龄排序,
- 向有序集合添加一个或者更新已存在成员分数
ZADD name 22 zhangsang - 返回有序集中,成员的分数值
ZSCORE name zhangsan
- 向有序集合添加一个或者更新已存在成员分数
上面提到的应用示例只是举例, 是否合理自行判断。
2.2.2 其他运维命令
- keys
一次性查询满足条件的所有key
- scan
redis 2.8 版本加入的指令,可以通过游标分步查询,不会阻塞线程
- info
查看内存
- select db-index
选择对应的库, redis 默认 database 为 16, 因此 db-index 为 0-15
- flushdb
清空数据库
2.3 数据持久化方式
所谓持久化就是把数据保存到磁盘上,redis 数据持久化方式有两种 rdb 和 aof。
详情请参考之前的两篇文章:
Redis 数据持久化 - RDB 和 AOF 简单介绍
Redis 持久化方式 - RDB 和 AOF 配置及 rewrite 机制
2.4 缓存淘汰策略
上面的思维导图中列出的 redis 的缓存淘汰策略有 6 种,redis 4.0 增加两种。
详情请参考前面的文章:
redis 的 maxmemory 配置以及 缓存淘汰策略
2.5 redis 高性能的原因
1、纯内存操作
Redis 将数据放在内存中,内存中的数据存取更快
2、非阻塞I/O
Redis 使用 epoll 作为 I/O 多路复用技术的实现,在加上Redis自身的事件处理模型将epoll中的链接、读写、关闭都转换为事件,不在网络I/O上浪费过多的时间;
3、单线程
避免了线程切换和锁产生的消耗。
2.6 redis 事务
类似关系型数据库 mysql 那样, 具有事务操作 begin, commit, rollback 指令操作, redis 也有类似的事务操作指令, 分别是 multi, exec, discard,
- multi 表示事务的开始
- exec 表示事务的执行
- discard 表示丢弃事务
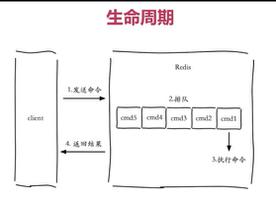
在执行 exec指令之前,执行的所有的指令都会缓存在一个事务队列中, 一旦执行了 exec指令后,才会开始执行整个事务队列的所有指令,最后返回所有指令的运行结果。
> multiOK
> incr num
QUEUED
> incr num
QUEUED
> exec
(integer)1
(integer)2
另外,redis 事务在遇到指令执行失败时,不会影响后面的指令执行,但是 redis 提供了一个 discard指令, 用于 丢弃 事务缓存队列中 剩余的所有指令。
2.7 redis 部署方式
Redis 主从复制-sentinel 部署参考之前的一篇文章
redis 主从 + 哨兵模式集群部署(3台机器)
另外还有一种 redis-cluster .
这几种方式各有各的优缺点, 具体根据自己的业务需求去选择。
2.8 其他
- 缓存穿透
当用户想要查询一个数据,redis 缓存没有命中,于是向持久层数据库(比如 mysql)查询,发现也没有,结果查询失败。当查询次数很多的时,就会给持久层数据库造成很大的压力,这时候就相当于出现了缓存穿透。
- 缓存击穿
指一个热点 key,被大量并发集中访问,当这个 key 在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞
- 缓存雪崩
当系统的 cache 层因为某种问题不能正常工作了。就导致所有的请求都会达到持久层,此时持久层的调用量会暴增,造成持久层挂掉的情况。
总结
上面对 redis 的基本知识点做了简单的梳理,详情还需要有针对性地去了解, 因为每个知识点如果展开讲,都能占用大量篇幅。
另附 redis 参考书籍:
《redis 实战》
《redis 深度探险》
《redis 设计与实现》
以上是 redis基础知识点汇总 的全部内容, 来源链接: utcz.com/z/533095.html