MySQL优化(3):索引

MySQL优化中,最重要的优化手段就是索引,也是最常用的优化手段
索引简介:
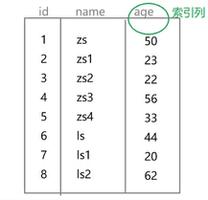
索引:关键字与数据位置之间的映射关系
关键字:从数据中提取,用于标识,检索数据的特定内容
目的:加快检索
索引检索为什么快:
(1)关键字相对于数据本身,量较小
(2)关键字都是排序好的
MySQL中索引的类型:
普通索引,唯一索引,主键索引,全文索引
不同的类型只是对关键字的限制不同
普通索引:多索引关键字没限制,有长度限制
唯一索引:要求记录提供的关键字不能重复
主键索引:要求关键字不能重复而且不能为NULL
全文索引:不支持中文,后续细讲
索引的语法:
查看索引:
SHOW CREATETABLE[table-name];
比如查到PRIMARY KEY(‘id’),就是一个主键索引
创建索引:需要修改表结构和创建表时候完成,基于不同的类型,方式也不同
同时创建四个索引,由于使用到了全文索引,这里使用MYISAM引擎
CREATETABLEUSER(ID
INT AUTO_INCREMENT PRIMARYKEY,FIRST_NAME
VARCHAR(16),LAST_NAME
VARCHAR(16),SN
VARCHAR(16),INFORMATION
TEXT,KEY(FIRST_NAME,LAST_NAME),UNIQUEKEY(SN),FULLTEXT
KEY(INFORMATION))ENGINE
=MYISAM;
索引可以命名,比如KEY NAME (FIRST_NAME,LAST_NAME)
这句话创建了一个基于FIRST_NAME和LAST_NAME的复合普通索引
UNIQUE KEY(SN) 创建了基于SN的唯一索引,默认以字段名命名索引
最后一个全文索引很鸡肋,基本不会用
在修改表结构的时候创建索引:
ALTERTABLEUSER(ADDKEY(FIRST_NAME,LAST_NAME),ADDUNIQUEKEY(SN),ADD FULLTEXT KEY(INFORMATION))
删除索引:
ALTERTABLE[table-name]DROPPRIMARYKEY;ALTERTABLE[table-name]DROPKEY[key-name];
一般不简易删除主键索引,记录是按照主键来排序的,设计主键要注意一定与业务逻辑无关
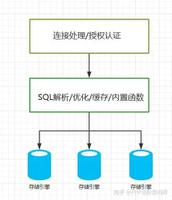
执行计划:
执行计划:当MySQL执行SQL语句时,会分析、优化、形成执行计划后按照执行计划来执行
在执行计划中可以清楚的看到当前的查询是否需要用到索引:
EXPLAIN SELECT*FROM[table-name]WHERE ID<20;
结果中有一样:KEY:PRIMARY,代表该查询语句会用到主键索引
索引使用的场景:
如果两张表,学生和班级表,多对一的关系,导入较多的记录来测试
(1)WHERE查询
EXPLAIN SELECT*FROM STUDENT WHERE ID=123456
和上面的例子一样,可以看到使用到了主键索引
EXPLAIN SELECT*FROM STUDENT WHERE USERNAME="XXX"
这句话执行后会发现:KEY:NULL,没有索引
我们给它加上索引:(这里的INDEX和上文的KEY都可以)
ALTERTABLE STUDENT ADDINDEX (USERNAME);
查看执行计划后可以发现:KEY:USERNAME,说明使用到了新建的索引
(2)ORDER BY排序
我们有可能会遇到以下的情况:
SELECT*FROM STUDENT ORDERBY USERNAME;
查看执行计划后可以发现没有使用到任何索引,并且看到了Extra:Using Filesort,使用到了外部文件排序,性能更低,需要先将数据读取到内存,分段读取合并排序
提高效率的方式是增加索引:
ALTERTABLE STUDENT ADDINDEX (USERNAME);
现在查看执行计划后,可以发现使用到了USERNAME索引,并且没有使用外部文件排序,性能会有明显提升
(3)JOIN 连接
使用到这条语句:
SELECT C.*COUNT(S.ID) FROM CLASS C JOIN STUDENT S ON C.ID=S.CLASS_ID GROUPBY C.ID;
当数据量巨大的时候,这句话要执行5S以上
查看执行计划后,发现其中一张表没有索引,且使用到了外部文件排序
解决:
ALTERTABLE STUDENT ADDINDEX (CLASS_ID);
执行后发现速度明显提升,并且两张表都使用到了索引,没有外部文件排序
(4)索引覆盖
前三条很重要,是必须做的优化,这条只是一个现象
比如我们使用这条语句:建立一个复合索引
ALTERTABLE STUDENT ADDINDEX (FIRSTNAME,LASTNAME);
然后再执行:这句话没有使用到以上三种情况
SELECT FIRSTNAME,LASTNAME FROM STUDENT;
但是查看计划后,发现还是使用到了索引,并且Extra:Using index,说明这句话只使用了索引来完成
如果执行这句话
SELECT FIRSTNAME,LASTNAME,USERFROM STUDENT;
再查看计划后发现没有使用到了索引,并且进行了全表扫描
两次的差异只是多了一个USER字段,而复合索引没有包含该字段
总结:MySQL的查询优先使用了索引,由于索引覆盖,建议SELECT后面只写有必要的字段,被覆盖的可能性就会提升,尽可能地优化
语法注意细节:
(1)字段需要独立出现
SELECT*FROM STUDENT WHERE ID+1=20;
这句话是能执行成功的,ID是主键,查看计划后却没有使用到主键索引
字段没有独立出现,不能触发该字段上的索引,避免这种情况
(2)LIKE查询不能以通配符开头
SELECT*FROM STUDENT WHERE USERNAME LIKE"%A%";
这句话无法使用到索引,如果是以下的情况,那么会用到索引
SELECT*FROM STUDENT WHERE USERNAME LIKE"A%";
字符串比较中,不能使用包含的逻辑,比如查询包含Java的字符串,不能写"%Java%",效率过低
解决办法:全文索引,但是MySQL全文索引很鸡肋,应该使用第三方的比如ES,Solr
(3)复合索引的右侧字段不能独立使用索引
已有INDEX NAME(FIRSTNAME,LASTNAME);
使用语句,这句话使用到了索引
SELECT*FROM STUDENT WHERE FIRSTNAME="XXX";
而下面这句话没有使用到索引
SELECT*FROM STUDENT WHERE LASTNAME="XXX";
原因:复合索引是按照左侧字段排序的,如果左侧字段相同再用右侧字段排序,总体上来看,右侧字段是未排序的
既然这样为什么还要建复合索引呢?以下这种情况
SELECT*FROM STUDENT WHERE FIRSTNAME LIKE"XX%"AND LASTNAME LIKE"XX%";
这句话如果建立两个索引,那么计算两个索引的交集会更慢,所以需要复合索引
如果遇到上面的情况,再给LASTNAME建立一个索引即可
(4)早期版本NULL值无法使用索引
SELECT*FROM STUDENT WHERE FIRSTNAME=NULL;
新版本无需关心这一条
(5)OR语法保证两边的条件都有索引可用
SELECT*FROM STUDENT WHERE FIRSTNAME LIKE"XX%"ORUSERLIKE"XX%";
如果USER没有索引,那么还是会全表查询
(6)状态值不容易使用到索引
GENDER 0,1,2表示男,女,未知
即使在字段上增加了索引,通常也不会起作用
SELECT*FROM STUDENT WHERE GENDER IN (0,1);
原因:状态值往往导致一个状态值匹配大量记录,查询大量记录的时候,MYSQL认为使用索引开销比全表扫描都要大
如何创建索引:
(1)WHERE,ORDER BY,JOIN字段上建立索引
(2)组合索引的建立:基于业务逻辑
(3)如果条件经常出现在一起,多字段索引可以升级为复合索引
(4)如果通过增加个别字段,就可以出现索引覆盖,那么增加个别字段
(5)不会用到的索引应该删掉
(6)常规情况下我们建立的数据库系统本身性能就不差了
(7)有些字段是否只使用前缀就能完成,使用前缀索引
前缀索引:INDEX(FIELD(10))
使用字段field的前10个字符建立索引,默认是使用字段全部内容建立索引
使用:GIT的COMMIT_ID;密码字段
索引的存储结构:
BTREE索引,HASH索引,聚簇索引
以上概念指的是索引的存储结构,数据结构上的概念,实际使用无需关心,了解即可
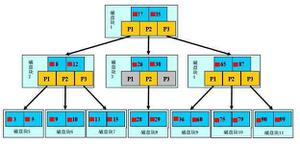
BTREE索引:
索引存储在磁盘上所用的基础的通用的存储结构
特征:磁盘上的数据结构,不是二叉树,一定要一个中文,那就是多路平衡查找树
特点:一个BTREE节点,存储多个索引关键字,多少由节点大小和关键字来确定的,
节点大小是固定的,由计算机文件系统来确定,一次性磁盘读取内存量,就是一个节点大小
由于一个节点的大小是固定的,一个节点无法容纳大量关键字,所以分散在多个节点来存储关键字
这时候如何进行排序呢?通过上层节点的子节点指针指向下层节点,用来关联所有的节点,子节点指针位于关键字之间
例如每个节点存储1000个关键字,深度为2的两层BTREE大概可以存储1000000(1000*1000)个关键字
查找一个关键字,需要读取几个节点的内容呢?从根开始,确定下级节点,仅仅两次的磁盘读取就可以做到
Btree的意义在于可以遍历大量关键字,减少磁盘读取量的开销
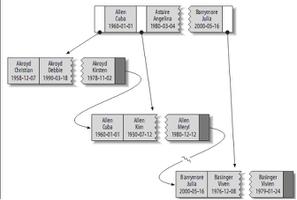
聚簇索引:
关键字和记录在一起进行存储
是升级后的Btree,数据结构上的B+Tree
MySQL中只有Innodb的主键索引是聚簇结构
HASH索引:
当索引被载入到内存后采用的存储结构,采用哈希结构存储了,类似Java的Map,Key-Value
以上是 MySQL优化(3):索引 的全部内容, 来源链接: utcz.com/z/532599.html