Zookeeper分布式协调即分布式锁机制

主要用到的Zookeeper机制:
临时+有序节点,节点watch机制
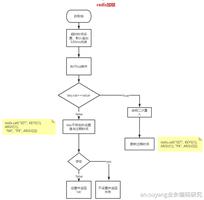
过程:
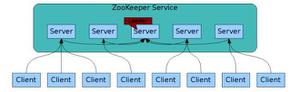
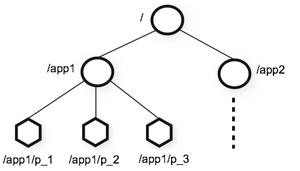
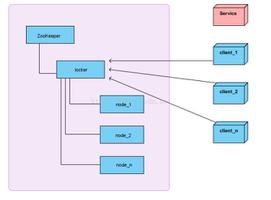
- 每个客户端服务都到zookeeper的同一父节点下建立自己的临时+有序子节点,子节点名返回,各客户端保存在本地。
- 所有客户端服务都拉去父节点下的子节点列表,通过对列表排序,将自己本地存储的节点名与列表中的节点名比较:
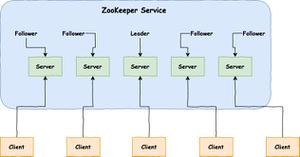
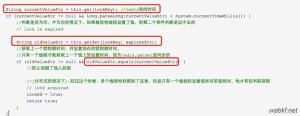
- 若本地节点与列表中最小的节点相同则表示拿到了锁,此服务得到执行后续逻辑的机会。
- 若本地节点不是列表中最小的,则表明拿锁失败,转而监听比自己小1位的节点在zookeeper中的实际节点,其余节点亦然,从而完成了整体的监听与排队等待。
- 成功得锁的服务执行完毕后就断开与zookeeper的session,zookeeper中与之对应的节点自动删除,此时触发监听。
- 删除节点的事件被下一个服务监听到,又触发它拉取一次列表,做同样的比较,发现自己是最小的节点,此时它拿到了锁,获得执行权限,以此类推各服务互斥的逐个得到执行。
以上是 Zookeeper分布式协调即分布式锁机制 的全部内容, 来源链接: utcz.com/z/532314.html