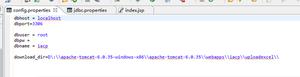
大数据HDFS集群搭建的配置文件

1.HDFS简单版集群搭建相关配置文件
1.core-site.xml文件
1 <property>2 <name>fs.defaultFS</name>
3 <value>hdfs://hadoop2:9000</value>
4 </property>
5
6 <property>
7 <name>hadoop.tmp.dir</name>
8 <value>/usr/hadoop-2.9.2/data</value>
9 </property>
2.ZK搭建高可用HDFS集群搭建相关配置文件
1.zkdata1/zoo.cfg文件
1 tickTime=20002 initLimit=10
3 syncLimit=5
4 dataDir=/root/zkdata
5 clientPort=30016 server.1=主机名:3002:3003
7 server.2=主机名:4002:4003
8 server.3=主机名:5002:5003
2.hadoop的core-site.xml文件
1 <!--hdfs主要入口不再是一个具体机器而是一个虚拟的名称 --> 2 <property>
3 <name>fs.defaultFS</name>
4 <value>hdfs://ns</value>
5 </property>
6
7 <property>
8 <name>hadoop.tmp.dir</name>
9 <value>/usr/hadoop-2.9.2/data</value>
10 </property>
11
12 <property>
13 <name>ha.zookeeper.quorum</name>
14 <value>hadoop1:3001,hadoop1:4001,hadoop1:5001</value>
15 </property>
3.hadoop 配置hdfs-site.xml文件
1 <!--指定hdfs的nameservice为ns,需要和core-site.xml中的保持一致 --> 2 <property>
3 <name>dfs.nameservices</name>
4 <value>ns</value>
5 </property>
6 <!-- ns下面有两个NameNode,分别是nn1,nn2 -->
7 <property>
8 <name>dfs.ha.namenodes.ns</name>
9 <value>nn1,nn2</value>
10 </property>
11 <!-- nn1的RPC通信地址 -->
12 <property>
13 <name>dfs.namenode.rpc-address.ns.nn1</name>
14 <value>hadoop2:9000</value>
15 </property>
16 <!-- nn1的http通信地址 -->
17 <property>
18 <name>dfs.namenode.http-address.ns.nn1</name>
19 <value>hadoop2:50070</value>
20 </property>
21 <!-- nn2的RPC通信地址 -->
22 <property>
23 <name>dfs.namenode.rpc-address.ns.nn2</name>
24 <value>hadoop3:9000</value>
25 </property>
26 <!-- nn2的http通信地址 -->
27 <property>
28 <name>dfs.namenode.http-address.ns.nn2</name>
29 <value>hadoop3:50070</value>
30 </property>
31
32 <!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
33 <property>
34 <name>dfs.namenode.shared.edits.dir</name>
35 <value>qjournal://hadoop2:8485;hadoop3:8485;hadoop4:8485/ns</value>
36 </property>
37 <!-- 指定JournalNode在本地磁盘存放数据的位置 -->
38 <property>
39 <name>dfs.journalnode.edits.dir</name>
40 <value>/root/journal</value>
41 </property>
42 <!-- 开启NameNode故障时自动切换 -->
43 <property>
44 <name>dfs.ha.automatic-failover.enabled</name>
45 <value>true</value>
46 </property>
47 <!-- 配置失败自动切换实现方式 -->
48 <property>
49 <name>dfs.client.failover.proxy.provider.ns</name>
50 <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
51 </property>
52 <!-- 配置隔离机制,如果ssh是默认22端口,value直接写sshfence即可 -->
53 <property>
54 <name>dfs.ha.fencing.methods</name>
55 <value>sshfence</value>
56 </property>
57 <!-- 使用隔离机制时需要ssh免登陆 -->
58 <property>
59 <name>dfs.ha.fencing.ssh.private-key-files</name>
60 <value>/root/.ssh/id_rsa</value>
61 </property>
3.搭建yarn集群
1.mapred-site.xml
注意:默认/etc/中没有这个配置文件 需要拷贝mapred-site.xml.template 配置文件
改名为mapred-site.xml
1 <property>2 <name>mapreduce.framework.name</name>
3 <value>yarn</value>
4 </property>
2.yarn.site.xml文件
1 <property>2 <name>yarn.nodemanager.aux-services</name>
3 <value>mapreduce_shuffle</value>
4 </property>
5 <property>
6 <name>yarn.resourcemanager.hostname</name>
7 <value>Hadoop</value>
8 </property>
4.HA的hadoop集群搭建的配置文件(最终版)
1.core-site.xml文件
1 <!--hdfs主要入口不再是一个具体机器而是一个虚拟的名称 --> 2 <property>
3 <name>fs.defaultFS</name>
4 <value>hdfs://ns</value>
5 </property>
6 <!-- hadoop临时目录位置 -->
7 <property>
8 <name>hadoop.tmp.dir</name>
9 <value>/root/hadoop-2.9.2/data</value>
10 </property>
11 <!--zk集群的所有节点-->
12 <property>
13 <name>ha.zookeeper.quorum</name>
14 <value>zk:3001,zk:4001,zk:5001</value>
15 </property>
2.hdfs-site.xml文件
1 <!--指定hdfs的nameservice为ns,需要和core-site.xml中的保持一致 --> 2 <property>
3 <name>dfs.nameservices</name>
4 <value>ns</value>
5 </property>
6 <!-- ns下面有两个NameNode,分别是nn1,nn2 -->
7 <property>
8 <name>dfs.ha.namenodes.ns</name>
9 <value>nn1,nn2</value>
10 </property>
11 <!-- nn1的RPC通信地址 -->
12 <property>
13 <name>dfs.namenode.rpc-address.ns.nn1</name>
14 <value>hadoop22:9000</value>
15 </property>
16 <!-- nn1的http通信地址 -->
17 <property>
18 <name>dfs.namenode.http-address.ns.nn1</name>
19 <value>hadoop22:50070</value>
20 </property>
21 <!-- nn2的RPC通信地址 -->
22 <property>
23 <name>dfs.namenode.rpc-address.ns.nn2</name>
24 <value>hadoop23:9000</value>
25 </property>
26 <!-- nn2的http通信地址 -->
27 <property>
28 <name>dfs.namenode.http-address.ns.nn2</name>
29 <value>hadoop23:50070</value>
30 </property>
31
32 <!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
33 <property>
34 <name>dfs.namenode.shared.edits.dir</name>
35 <value>qjournal://hadoop26:8485;hadoop27:8485;hadoop28:8485/ns</value>
36 </property>
37 <!-- 指定JournalNode在本地磁盘存放数据的位置 -->
38 <property>
39 <name>dfs.journalnode.edits.dir</name>
40 <value>/root/journal</value>
41 </property>
42 <!-- 开启NameNode故障时自动切换 -->
43 <property>
44 <name>dfs.ha.automatic-failover.enabled</name>
45 <value>true</value>
46 </property>
47 <!-- 配置失败自动切换实现方式 -->
48 <property>
49 <name>dfs.client.failover.proxy.provider.ns</name>
50 <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
51 </property>
52 <!-- 配置隔离机制,如果ssh是默认22端口,value直接写sshfence即可 -->
53 <property>
54 <name>dfs.ha.fencing.methods</name>
55 <value>sshfence</value>
56 </property>
57 <!-- 使用隔离机制时需要ssh免登陆 -->
58 <property>
59 <name>dfs.ha.fencing.ssh.private-key-files</name>
60 <value>/root/.ssh/id_rsa</value>
61 </property>
3.yarn-site.xml文件
1 <!-- 开启RM高可用 --> 2 <property>
3 <name>yarn.resourcemanager.ha.enabled</name>
4 <value>true</value>
5 </property>
6 <!-- 指定RM的cluster id -->
7 <property>
8 <name>yarn.resourcemanager.cluster-id</name>
9 <value>yrc</value>
10 </property>
11 <!-- 指定RM的名字 -->
12 <property>
13 <name>yarn.resourcemanager.ha.rm-ids</name>
14 <value>rm1,rm2</value>
15 </property>
16 <!-- 分别指定RM的地址 -->
17 <property>
18 <name>yarn.resourcemanager.hostname.rm1</name>
19 <value>hadoop24</value>
20 </property>
21 <property>
22 <name>yarn.resourcemanager.hostname.rm2</name>
23 <value>hadoop25</value>
24 </property>
25 <property>
26 <name>yarn.resourcemanager.webapp.address.rm1</name>
27 <value>hadoop24:8088</value>
28 </property>
29 <property>
30 <name>yarn.resourcemanager.webapp.address.rm2</name>
31 <value>hadoop25:8088</value>
32 </property>
33 <!-- 指定zk集群地址 -->
34 <property>
35 <name>yarn.resourcemanager.zk-address</name>
36 <value>zk:3001,zk:4001,zk:5001</value>
37 </property>
38 <property>
39 <name>yarn.nodemanager.aux-services</name>
40 <value>mapreduce_shuffle</value>
41 </property>
4.mapred-site.xml 默认不存在需要复制
1 <!-- 指定mr框架为yarn方式 -->2 <property>
3 <name>mapreduce.framework.name</name>
4 <value>yarn</value>
5 </property>
以上是 大数据HDFS集群搭建的配置文件 的全部内容, 来源链接: utcz.com/z/531978.html