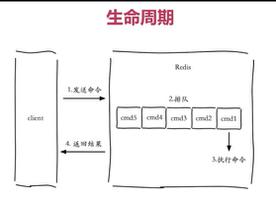
学习之Redis(一)

一、redis简介
一般学习,最好先去官网,之所以建议看官网,是因为这是一手的学习资料,其他资料都最多只能算二手,一手资料意味着最权威,准确性最高。https://redis.io/topics/introduction。如果像我一样,英语不好的童鞋,不要紧,咋们用Chrome浏览器,翻译成中文。Eumm。。。来看看官网给的解释:“redis is an open source (BSD licensed), in-memory data structure store, used as a database, cache and message broker.” ,第一句就告诉我们,redis是什么:redis是一个开源的,基于内存的数据结构存储,可用作于数据库、缓存、消息中间件。
1.1、为什么使用redis?
由官网可知:redis是基于内存,常用于缓存的一种技术,并redis存储方式是以 Key-value 的形式。等等?Key-value??这个不就是Java中Map容器的特性吗?那为什么还用redis呢?
- Java实现的Map是本地缓存,只能存在创建他的程序中。最主要的特点是轻量以及快速。而且实例多的情况下,每个实例都需要各自保存一份缓存,缓存不具有一致性。
- redis实现的是分布式缓存,如果有多个实例机器,每个实例共享一份缓存,缓存具有一致性。
- Java中Map不是专业做缓存的,JVM内存太大容易挂掉,所以一般用来做容器存储临时数据,缓存随着JVM销毁而结束。
- redis是专门做缓存的,缓存可以持久化,可以将缓存的数据保存在硬盘中,redis重启之后就可以恢复。但是Map是内存对象,程序重启数据就没有了。
- redis可以处理每秒百万级的并发,Map只是一个普通的对象。
1.2、为什么要用缓存
如果我们的网站出现了性能问题(访问时间慢),一般是由于数据库扛不住了。因为一般的数据库的读写都是经过磁盘的,磁盘的读写相当于内存来说非常慢了。参考资料:让CPU告诉你硬盘和网络到底有多慢:https://cizixs.com/2017/01/03/how-slow-is-disk-and-network/。用过Mybatis和Hibernate的同学都知道,他们有一级缓存、二级缓存这样的功能(实质就是本地缓存),目的就是为了不用每次读取数据的时候,都去数据库查询。
二、redis的对象和数据结构
注:本篇博文不讲述redis命令的使用方式,具体的使用请查看API.(redis命令参考:http://doc.redisfans.com/)
【对象】
redis使用对象来表示数据库中的键和值,每次在redis中新建一个键值对的时候,至少会创建出两个对象。一个对象用作键值对的键(键对象),一个对象用作键值对的(值对象)。redis中的每种对象都由对象结构(redisObject) 与对应编码的 数据结构 组合而成,redis支持5种对象类型,分别是字符串(string)、列表(list)、哈希(hash)、集合(set)、有序集合(zset),而每种对象类型至少对应两种编码方式,不同的编码方式所对应的底层数据结构是不同的。
每个对象会用到的编码以及对应的数据结构详见下表:
每种对象对应两至三种编码,除skiplist编码需要用到两种数据结构(字典+跳跃表)外,其余编码均用到一种底层的数据结构。同一个对象类型,在不同的场景下用到的编码(数据结构)不同,redis支持8种编码以及8种底层的数据结构。这种方式更加灵活,可以帮助redis获得更高的性能以及尽量占用更少的内存。比如如果字符串对象中要存储的字符串内容所占字节较小,会用embstr编码的格式,如果要存储的内容所占字节较大,会用raw编码的格式,具体细节后文会详细说明。
上面说过,redis中的键和值都是由对象组成的,而对象是由对象结构和数据结构共同组成的。redis中的键,都是用字符串来存储的,即对于redis数据库中的键值对来说,键总是一个字符串对象,而值可以是字符串对象、列表对象、哈希对象、集合对象或者有序集合对象中的其中一种。
键、值的整体大致结构可以如下图所示
【对象结构】
对象结构(redisObject)共有5个属性,分别是type属性、encoding属性、ptr属性、refcount属性、lru属性。
其中type属性、encoding属性、ptr属性和保存数据有关
type属性:表示该对象的类型是什么
encoding属性:表示这个对象使用的底层数据结构是什么
ptr属性:是一个指向底层数据结构的指针
refcount属性是一个引用计数属性,可以用于内存回收和对象共享
lru属性,记录了对象最后一次被命令程序访问的时间,可以计算出某个键的空转时长
对象结构的逻辑图如下所示:
【内存回收--refcount属性】
在对象结构中,有refcount这个属性,该属性用于记录对象的引用计数信息,redis利用引用计数(reference counting)技术实现内存回收机制,通过这一机制,程序可以通过跟踪对象的引用计数信息,在适当的时候自动释放对象并进行内存回收。
具体策略:
在创建一个新对象时,引用计数的值会被初始化为1
当对象被一个新程序使用时,它的引用计数值会被增一
当对象不再被一个程序使用时,它的引用计数值会被减一
当对象的引用计数值变为0时,对象所占用的内存会被释放
【对象共享--refcount属性】
redis会在初始化服务器时,服务器会创建一万个字符串对象,这些对象包含了从0到9999的所有整数值,当服务器、新创建的键需要用到值为0到9999的字符串对象时,服务器就会使用这些共享对象,而不是新创建对象。
对象结构中,refcount是引用指针属性,如果有N个键共享一个值,refcount对应的值就为N。创建共享字符串对象的数量可以通过redis.h/redis_shared_intengers常量来修改。object refcount命令可以查看某个键对应的值被引用了多少次。
让多个键共享一个值,需要执行以下两个步骤:
将键的值指针,指向被共享的值对象
被共享的值对象的引用计数器加一,即refcount属性的值加一,引用数为2的共享对象结构图如下图所示:
【进一步说明】
当服务器考虑将一个键的值引用共享对象时,键的值作为目标对象,程序需要先检查共享对象和目标对象的类型是否完全相同,只有在完全相同的情况下,共享对象才会被引用。而一个共享对象保存的值越复杂,验证共享对象与目标对象所需的复杂度就会越高,消耗的CPU时间也会越多。
所以共享对象的优点是被其它键引用时,可以节省内存空间,缺点是被引用时需要进行判断,这个过程需要消耗CPU,如果共享对象简单,消耗很小的CPU并节省内存空间是值得的。但如果对象很复杂,进行判断就需要消耗大量CPU,消耗大量CPU去节省内存空间是不值得的,因为redis本身的内存空间还是很大的。
redis支持5种对象,包括字符串对象、列表对象、哈希对象、集合对象以及有序集合对象。而字符串对象是redis中的一个基础对象,其它对象均可以在底层的数据结构内部嵌套字符串对象。
对象共享:
1、只有字符串对象才能被创建为共享对象,被其它字符串键使用;
2、用字符串对象创建的共享对象,不单单只有字符串键可以使用,那些在数据结构中嵌套了字符串对象的对象(linkedlist编码的列表对象、hashtable编码的哈希对象、hashtable编码的集合对象,以及skiplist编码的有序集合对象)都可以使用这些字符串共享对象。
【对象的空转时长--lru属性】
对象结构的lru属性,记录了对象最后一次被命令程序访问的时间
空转时长:当前时间减去键的值对象的lru时间,就是该键的空转时长。Object idletime命令可以打印出给定键的空转时长
如果服务器打开了maxmemory选项,并且服务器用于回收内存的算法为volatile-lru或者allkeys-lru,那么当服务器占用的内存数超过了maxmemory选项所设置的上限值时,空转时长较高的那部分键会优先被服务器释放,从而回收内存。
2.1、字符串对象
2.11、字符串对象介绍
字符串对象可以存储整数、浮点数、字符串,具体策略是:
当存储整数时,用到的编码是int,底层的数据结构可以用来存储long类型的整数
当存储字符串时,如果字符串的长度小于等于32字节,那么将用编码为embstr的格式来存储;如果字符串的长度大于32字节,将用编码为raw的SDS格式来存储
当存储浮点数时会先将浮点数转换为字符串,如果转换后的字符串长度小于32字节就用编码为embstr的格式来存储,否则用编码为raw的SDS格式来存储
下图是以raw编码的字符串对象结构图,最左侧是对象结构,中间跟右侧合起来是raw编码的SDS数据结构(sdshdr),示例图:
2.12、raw编码,简单动态字符串(simple dynamic string-SDS)
虽然redis由C语言编写,但是redis用的并不是C语言传统的字符串,而是自己构建了简单动态字符串(simple dynamic string,SDS)。当redis打印日志信息或输出报错信息,这些输出的字符串是不会被修改的字符串字面量(sting literal),此时用的是C语言传统的字符串来存储这些信息的。当redis需要存储的是可以被修改的字符串时,就会使用SDS结构。除了用来保存数据库中的字符串值之外,SDS还被用作缓冲区(buffer):AOF模块中的AOF缓冲区,以及客户端状态中的输入缓冲区,都是由SDS实现的。
redis使用sdshdr结构来表示一个SDS的值,SDS结构示意图如下:
sdshdr是该数据结构的名称即SDS,其中:
buf属性,是一个字节数组,用来保存字符串,后面箭头对应的就是实际保存的字符串内容,最后以’’空字符串结尾
len属性,记录的是buf数组中实际已使用的字节数量,等于SDS所保存字符串的长度
free属性,记录的是buf数组中未存储内容的空余大小,单位字节
2.1.3、使用SDS的好处
一、可以用O(1)的复杂度获取到字符串长度
SDS的len属性记录了字符串的长度,而传统C字符串要想知道长度需要遍历整个字符串。相比于传统C字符串,redis获取字符串长度所需的复杂度从O(N)降低到了O(1)。
即使对非常长的字符串反复执行STRLEN命令(获取字符串长度),也不会造成过多的性能消耗。
二、杜绝缓冲区溢出
在传统的C字符串中,如果要修改字符串的内容,但修改后字符串的长度超过原先的长度就会发生溢出现象。详见下图:
在SDS中,当需要对buf字节数组中存储的内容进行修改(增添或删除)时,API会先通过free和len属性检查SDS的空间是否足够,如果不够的话,SDS会自动扩展空间再对内容进行修改。关于自动扩展空间的策略见下方“空间预分配”的内容。
三、减少修改字符串长度时所需的内存重分配次数
对于传统C字符串:
如果执行的是增长字符串的操作,如拼接操作(append),那么在执行命令之前,程序需要先通过内存重分配来扩展底层数据的空间大小——否则会产生缓冲区溢出。
如果执行的是缩短字符串的操作,如截断操作(trim),那么在执行这个操作之后,程序需要通过内存重分配来释放字符串不再使用的空间——否则会产生内存泄漏。
对于redis中的SDS结构:
内存重分配设计复杂的算法,是一个比较耗时的操作,redis作为速度要求严苛、数据会被频繁执行的数据库,如果每次修改字符串都需要进行一次内存重分配,会严重影响性能。
使用SDS,buf数组里可以包含未使用的字节,这些字节的数量由free属性记录,可以减少修改字符串长度时所需的内存重分配次数。
【空间预分配和惰性空间释放】
通过SDS中free属性定义的未使用空间,SDS可以实现空间预分配和惰性空间释放两种优化策略:
1、空间预分配策略——可以降低字符串增长操作引起的内存重分配
当需要修改SDS的内容,且需要进行空间扩展的时候,程序不仅会为SDS分配修改所需的必须空间,还会为SDS分配额外的未使用空间。
其中,额外分配的未使用空间数量由以下公式决定:
如果对SDS进行修改之后,SDS的长度(即len属性的值)将小于1MB,那么程序将分配和len属性同样大小的未使用空间,这时SDS len属性的值将和free属性的值相同。
如果对SDS进行修改后,SDS的长度将大于等于1MB,那么程序会分配1MB的未使用空间。
【进一步说明】
如果对一个字符串的末尾持续追加内容,当字符串整体大小大于1MB时,即使只追加一字节的字符,程序也会额外分配1MB的空间,当再次追加一字节的字符时,程序不会再额外分配1MB的空间,而是使用已有的空闲空间。
即在扩展空间之前,会先检查未使用的空间是否足够,如果足够,是不会额外再扩展的
通过空间预分配策略,SDS将连续增长N次字符串所需的内存重分配次数从必定N次降低为最多N次。
2、惰性空间释放策略——可以降低字符串缩短操作引起的内存重分配
当SDS中的字符串长度被缩短时,程序并不会立即使用内存重分配来回收缩短后多出来的字节空间,而是使用free属性将这些字节的数量记录起来,以备将来使用。
当然,redis提供了相应的命令来真正释放这些未使用空间,避免不必要的内存浪费。
四、二进制安全
C字符串中的字符必须符合某种编码(比如ASCII),并且除了字符串的末尾之外,字符串里面不能包含空字符,如果字符串除末尾外还有其它空字符,那么最先被程序读入的空字符将被误认为是字符串结尾,这些限制使得C字符串只能保存文本数据,而不能保存图片、音频、视频、压缩文件这样的二进制数据。
为了确保redis可以适用于各种不同的使用场景,SDS的API都是二进制安全的(binary-safe),所有SDS API都会以处理二进制的方式来处理SDS存放buf数组里的数据,程序不会对其中的数据做任何限制、过滤或者假设,数据在写入时是什么样的,它被读取时就是什么样。
这也是SDS的buf属性被称为字节数组的原因——redis不是用这个数组来保存字符,而是用它来保存一系列二进制数据。
五、兼容部分C字符串函数
SDS遵循空字符串结尾这一惯例,好处是可以直接重用C字符串函数库里的函数,从而避免了不必要的代码重复
【embstr编码】
如果字符串对象保存的是长度小于等于32字节的字符串,那么将会使用embstr编码,embstr编码是专门用来保存短字符串的一种优化编码方式。embstr编码与raw编码对应的字符串对象,都是由对象结构(redisObject)和数据结构(sdshdr)组成的。
区别在于用raw编码的字符串对象会调用两次内存分配函数来分别创建redisObject结构和sdshdr结构,而embstr编码则通过调用一次内存分配函数来分配一块连续的空间,空间中一次包含redisObject和sdshr两个结构,embstr编码的字符串对象结构图如下所示:
两者的区别
embstr编码的字符串对象在执行命令时,产生的效果和raw编码的字符串对象执行命令时产生的效果是相同的,但使用embstr编码的字符串对象来保存短字符串值有以下好处:
1、embstr编码将创建字符串对象所需的内存分配次数从raw编码的两次降低为一次
2、释放embstr编码的字符串对象只需要调用一次内存释放函数,而释放raw编码的字符串对象需要调用两次内存释放函数
3、embstr编码的字符串对象的所有数据都保存在一块连续的内存里,结构更加紧凑,而raw编码是分散开的,redisObject对象结构和sdshdr数据结构彼此间是用指针相关联的,embstr编码的对象比raw编码的对象能够更好的利用缓存带来的优势。
【编码的转换】
int编码的字符串对象和embstr编码的字符串对象在条件满足的情况下,会被转换成raw编码的字符串对象。encoding命令可以查看键对应的值,底层用的是什么编码。
int转换为raw:
对于int编码的字符串对象来说,如果我们向对象执行了一些命令,使得这个对象保存的不再是整数值,而是一个字符串值,那么字符串对象的编码将从int变为raw
127.0.0.1:6379> set a 100OK
127.0.0.1:6379> object encoding a"int"127.0.0.1:6379> append a "a"
(integer) 4
127.0.0.1:6379> get a
"100a"
127.0.0.1:6379> object encoding a
"raw"
int编码的字符串,存储的是long类型的整数,范围是2^63-1(2的63次方减一) ~ -2^63(2的63次方),当存储的整数在该范围内时,编码为int,当值超过该范围,编码将转换为embstr
127.0.0.1:6379> set number1 9223372036854775807OK
127.0.0.1:6379> object encoding number1"int"127.0.0.1:6379> set number1 9223372036854775808
OK
127.0.0.1:6379> object encoding number1
"embstr"
127.0.0.1:6379> set number -9223372036854775808
OK
127.0.0.1:6379> object encoding number
"int"
127.0.0.1:6379> set number -9223372036854775809
OK
127.0.0.1:6379> object encoding number
"embstr"
embstr转换为raw:
embstr编码的字符串对象无法被修改(redis没有为embstr编码的字符串对象编写任何响应的修改程序),只有int、raw编码的字符串对象可以被修改,所以embstr编码的字符串实际上是只读的。
当对embstr编码的字符串对象执行任何修改命令时,程序都会先将对象的编码从embstr转换为raw,然后再执行修改命令。所以一旦embstr编码的字符串被修改,它的数据结构就会变成raw编码的格式。
127.0.0.1:6379> set a "ab"OK
127.0.0.1:6379> object encoding a"embstr"127.0.0.1:6379> append a "c"
(integer) 3
127.0.0.1:6379> get a
"abc"
127.0.0.1:6379> object encoding a
"raw"
以上是 学习之Redis(一) 的全部内容, 来源链接: utcz.com/z/531767.html