分库分表

分库分表前的问题
任何问题都是太大或者太小的问题,我们这里面对的数据量太大的问题。
用户请求量太大
因为单服务器TPS,内存,IO都是有限的。 解决方法:分散请求到多个服务器上; 其实用户请求和执行一个sql查询是本质是一样的,都是请求一个资源,只是用户请求还会经过网关,路由,http服务器等。
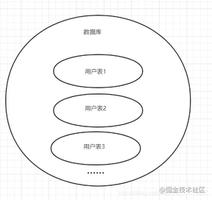
单库太大
单个数据库处理能力有限;单库所在服务器上磁盘空间不足;单库上操作的IO瓶颈 解决方法:切分成更多更小的库
单表太大
CRUD都成问题;索引膨胀,查询超时 解决方法:切分成多个数据集更小的表。
分库分表方法
分库分表有两个维度的分法:垂直拆分,水平拆分。
垂直拆分
垂直拆分是按列拆分,例如表有:a,b,c,d,e五列,垂直拆分时a,b,c拆成一个新表,d,e拆成一个新表。
垂直拆分分为:垂直分表和垂直分库。
在实践中通常按照下面两点拆分:
- 按照主要数据和扩展数据拆分。
- 按照功能或业务拆分。例如:把表中的User数据拆成一个新表,Product拆成一个新表。
水平拆分
水平拆分分为:水平分表和水平分库。
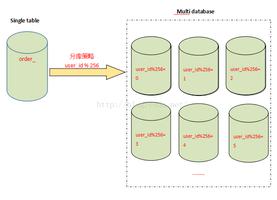
水平分库分表切分规则
- RANGE:从0到10000一个表,10001到20000一个表;
- HASH取模:一个商场系统,一般都是将用户,订单作为主表,然后将和它们相关的作为附表,这样不会造成跨库事务之类的问题。 取用户id,然后hash取模,分配到不同的数据库上。
- 地理区域:比如按照华东,华南,华北这样来区分业务,七牛云应该就是如此。
- 时间:按照时间切分,就是将6个月前,甚至一年前的数据切出去放到另外的一张表,因为随着时间流逝,这些表的数据 被查询的概率变小,所以没必要和“热数据”放在一起,这个也是“冷热数据分离”。
分库分表后面临的问题
事务支持
分库分表后,就成了分布式事务了。如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价; 如果由应用程序去协助控制,形成程序逻辑上的事务,又会造成编程方面的负担。
多库结果集合并(group by,order by)
跨库join
分库分表后表之间的关联操作将受到限制,我们无法join位于不同分库的表,也无法join分表粒度不同的表, 结果原本一次查询能够完成的业务,可能需要多次查询才能完成。
解决方法:
- 同类数据放到一张表中,必要时允许字段冗余,这样可以减少JOIN使用的情况
- 如果需要根据外键查多个表,那么查多次
主键
- 设置自增偏移和步长
## 假设总共有 10 个分表## 级别可选: SESSION(会话级), GLOBAL(全局)
SET @@SESSION.auto_increment_offset = 1; ## 起始值, 分别取值为 1~10
SET @@SESSION.auto_increment_increment = 10; ## 步长增量
- 全局ID映射表:在全局 Redis 中为每张数据表创建一个 ID 的键,记录该表当前最大 ID,每次申请 ID 时,都自增 1 并返回给应用。Redis 要定期持久至全局数据库。
- UUID(128位):优点:简单,全球唯一。缺点:存储和传输空间大,无序,性能欠佳。
- COMB(组合):参考资料:The Cost of GUIDs as Primary Keys 。组合 GUID(10字节) 和时间(6字节),达到有序的效果,提高索引性能。
- Snowflake(雪花) 算法:参考资料:twitter/snowflake,Snowflake 算法详解 。Snowflake 是 Twitter 开源的分布式 ID 生成算法,其结果为 long(64bit) 的数值。其特性是各节点无需协调、按时间大致有序、且整个集群各节点单不重复。
分库分表方案产品
目前市面上的分库分表中间件相对较多,其中基于代理方式的有MySQL Proxy和Amoeba, 基于Hibernate框架的是Hibernate Shards,基于jdbc的有当当sharding-jdbc, 基于mybatis的类似maven插件式的有蘑菇街的蘑菇街TSharding, 通过重写spring的ibatis template类的Cobar Client。
还有一些大公司的开源产品:
以上是 分库分表 的全部内容, 来源链接: utcz.com/z/531721.html