redis怎么做集群

Redis Sharding集群
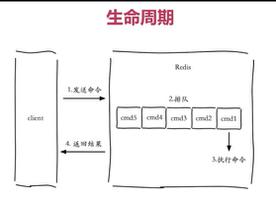
Redis 3正式推出了官方集群技术,解决了多Redis实例协同服务问题。Redis Cluster可以说是服务端Sharding分片技术的体现,即将键值按照一定算法合理分配到各个实例分片上,同时各个实例节点协调沟通,共同对外承担一致服务。 (推荐学习:Redis视频教程)
多Redis实例服务,比单Redis实例要复杂的多,这涉及到定位、协同、容错、扩容等技术难题。这里,我们介绍一种轻量级的客户端Redis Sharding技术。
Redis Sharding可以说是Redis Cluster出来之前,业界普遍使用的多Redis实例集群方法。其主要思想是采用哈希算法将Redis数据的key进行散列,通过hash函数,特定的key会映射到特定的Redis节点上。这样,客户端就知道该向哪个Redis节点操作数据。
庆幸的是,java redis客户端驱动jedis,已支持Redis Sharding功能,即ShardedJedis以及结合缓存池的ShardedJedisPool。
Jedis的Redis Sharding实现具有如下特点:
采用一致性哈希算法(consistent hashing),将key和节点name同时hashing,然后进行映射匹配,采用的算法是MURMUR_HASH。
采用一致性哈希而不是采用简单类似哈希求模映射的主要原因是当增加或减少节点时,不会产生由于重新匹配造成的rehashing。一致性哈希只影响相邻节点key分配,影响量小。
为了避免一致性哈希只影响相邻节点造成节点分配压力,ShardedJedis会对每个Redis节点根据名字(没有,Jedis会赋予缺省名字)会虚拟化出160个虚拟节点进行散列。
根据权重weight,也可虚拟化出160倍数的虚拟节点。用虚拟节点做映射匹配,可以在增加或减少Redis节点时,key在各Redis节点移动再分配更均匀,而不是只有相邻节点受影响。
ShardedJedis支持keyTagPattern模式,即抽取key的一部分keyTag做sharding,这样通过合理命名key,可以将一组相关联的key放入同一个Redis节点,这在避免跨节点访问相关数据时很重要。
以上是 redis怎么做集群 的全部内容, 来源链接: utcz.com/z/531469.html