教你使用python生成器重构提取数据方法,来优化你的爬虫代码

前言
在刚开始学习python的时候,有看到过迭代器和生成器的相关内容,不过当时并未深入了解,更谈不上使用了,其实是可以用生成器来改造一下的,所以本次就使用生成器来优化一下爬虫代码
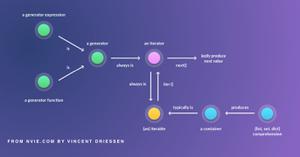
- 生成器函数与普通函数的区别是,生成器用关键字 yield 来返回值,而普通函数用 return 一次性返回值;
- 当你调用生成器函数的时候,函数内部的代码并不立马执行 ,这个函数只是返回一个生成器对象;
- 一般使用for循环迭代生成器对象来获取具体的返回值
什么时候可以使用生成器呢?
一般爬虫经常会通过for循环来迭代处理数据,例如我之前爬取20页数据时,会先把获得的数据存储到一个列表或字典中,然后再把整个列表或字典 return 出去,然后保存数据至本地又会再调用这个列表获取数据(其实做了2步:先把页面的数据提取出来存到列表,后面用的时候再迭代列表);
类似这种直接使用列表或字典来存储数据,其实是先存储到了内存中,如果数据量过大的话,则会占用大量内存,这样显然是不合适的;
此时就可以使用生成器,我们每提取一条数据,就把该条数据通过 yield 返回出去,好处是不需要提前把所有数据加载到一个列表中,而是有需要的时候才给它生成值返回,没调用这个生成器的时候,它就处于休眠状态等待下一次调用
优化爬虫代码
首先看一下未使用生成器的代码
# -*- coding:utf-8 -*-import requests
from requests.exceptions import RequestException
import os, time
from lxml import etree
def get_html(url):
"""获取页面内容"""
response = requests.get(url, timeout=15)
# print(response.status_code)
try:
if response.status_code == 200:
# print(response.text)
return response.text
else:
return None
except RequestException:
print("请求失败")
# return None
def parse_html(html_text):
"""解析一个结果页的内容,提取图片url"""
html = etree.HTML(html_text)
if len(html) > 0:
img_src = html.xpath("//img[@class="photothumb lazy"]/@data-original") # 提取图片url,通过xpath提取会生成一个列表
# print(img_src)
return img_src # 将提取出来的图片url列表返回出去
else:
print("解析页面元素失败")
def get_all_image_url(depth):
"""
提取所有页面的所有图片url
:param depth: 爬取页码
:return:
"""
base_url = "https://imgbin.com/free-png/naruto/" # 定义初始url
image_urls = []
for i in range(1, depth):
url = base_url + str(i) # 根据页码遍历请求url
html = get_html(url) # 解析每个页面的内容
# print(html)
if html:
list_data = parse_html(html) # 提取页面中的图片url
for img in list_data:
image_urls.append(img)
return image_urls
def get_image_content(url):
"""请求图片url,返回二进制内容"""
try:
r = requests.get(url, timeout=15)
if r.status_code == 200:
return r.content
return None
except RequestException:
return None
def main(depth=None):
"""
主函数,下载图片
:param depth: 爬取页码
:return:
"""
j = 1
img_urls = get_all_image_url(depth) # 提取页面中的图片url
root_dir = os.path.dirname(os.path.abspath("."))
save_path = root_dir + "/pics/" # 定义保存路径
# print(img_urls)
# print(next(img_urls))
# print(next(img_urls))
for img_url in img_urls: # 遍历每个图片url
try:
file_path = "{0}{1}.{2}".format(save_path, str(j), "jpg")
if not os.path.exists(file_path): # 判断是否存在文件,不存在则爬取
with open(file_path, "wb") as f:
f.write(get_image_content(img_url))
f.close()
print("第{}个文件保存成功".format(j))
else:
print("第{}个文件已存在".format(j))
j = j + 1
except FileNotFoundError as e:
print("遇到错误:", e)
continue
except TypeError as f:
print("遇到错误:", f)
continue
if __name__ == "__main__":
start = time.time()
main(2)
end = time.time()
print(end-start)
parse_html()函数:它的作用解析一个结果页的内容,提取一页的所有图片url(通过xpath提取,所以数据时存储在一个列表中),可以把它改造为生成器;
get_all_image_url()函数:调用parse_html()函数,通过控制爬取页码,提取所有页面的所有图片url,然后存到一个列表中返回出去,可以改造为生成器;
main()函数:调用get_all_image_url()函数得到所有图片url的列表,然后迭代这个列表,来得到每一个图片url来下载图片
接下来要做的就是改造 parse_html()函数 和 get_all_image_url()函数
这个其实也比较简单,只需要把原本要追加到列表中的东西通过 yield 关键字返回出去就行了
parse_html()函数:
"""遇到问题没人解答?小编创建了一个Python学习交流群:778463939
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
"""
def parse_html(html_text):
"""解析一个结果页的内容,提取图片url"""
html = etree.HTML(html_text)
if len(html) > 0:
img_src = html.xpath("//img[@class="photothumb lazy"]/@data-original")
# print(img_src)
for item in img_src:
yield item
get_all_image_url()函数
def get_all_image_url(depth): """
提取所有页面的所有图片url
:param depth: 爬取页码
:return:
"""
base_url = "https://imgbin.com/free-png/naruto/" # 定义初始url
for i in range(1, depth):
url = base_url + str(i) # 根据页码遍历请求url
html = get_html(url) # 解析每个页面的内容
# print(html)
if html:
list_data = parse_html(html) # 提取页面中的图片url
for img in list_data:
yield img # 通过yield关键字返回每个图片的url地址
然后上面代码中有个地方需要注意
for i in range(1, depth): 这个for循环,是迭代爬取页码
list_data = parse_html(html):调用parse_html()函数,获取每一页内容的生成器对象
for img in list_data: 迭代 list_data,然后通过yield img 把值返回出去
get_all_image_url()函数 还可以用以下方式返回结果
def get_all_image_url(depth): """
提取所有页面的所有图片url
:param depth: 爬取页码
:return:
"""
base_url = "https://imgbin.com/free-png/naruto/" # 定义初始url
for i in range(1, depth):
url = base_url + str(i) # 根据页码遍历请求url
html = get_html(url) # 解析每个页面的内容
# print(html)
if html:
list_data = parse_html(html) # 提取页面中的图片url
yield from list_data
使用关键字 yield from 替代了之前的内层for循环,可以达到相同的效果(具体含义可以查看 Python yield from 用法详解、yield from)
main()函数 不需要作改动,因为我们在调用生成器对象时,也是通过for循环来提取里面的值的,所以这部分代码和之前一样
OK,本次代码优化到此结束,python有太多东西要学啦,感觉自己懂得还是太少,要保持学习的心态,加油~
以上是 教你使用python生成器重构提取数据方法,来优化你的爬虫代码 的全部内容, 来源链接: utcz.com/z/530702.html