字符集和字符编码

字符集
· 创建文本文件默认使用ANSI,就是系统默认编码方式,中文window系统默认使用GBK编码方式
1. 字节
· 这是最基本的概念,字节是计算存储容量的一种计量单位,我们知道计算机只能识别1和0组成的二进制位,一个数就是1位(bit),为了方便计算,我们规定8位就是一个字节
2. 字符
· 字符和字节不太一样,任何一个文字或符号都是一个字符,但所占字节不一定,不同的编码导致一个字符所占的内存不同
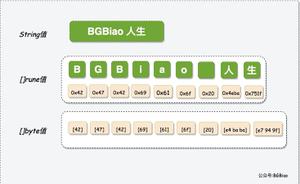
· 例如:标点符号+是一个字符,汉字我们是两个字符,在GBK编码中一个汉字占2个字节,在UTF-8编码中一个汉字占3个字节
3. 编码规范
·
所谓字符集其实是一套编码规范中的子概念,为了显示字符,国际组织就制定了编码规范,希望使用不同的二进制数来表示代表不同的字符,这样电脑就可以根据二进制数来显示其对应的字符。我们通常就称呼其为XX编码,XX字符集。
·
·
例如:GBK 编码规范,根据这套编码规范,计算机就可以在中文字符和二进制数之间相互转换。而使用GBK编码就可以使计算机显示中文字符
·
·
编码规范中的3个子概念
·
o
a. 字库表
a. 字库表存储了编码规范中能显示的所有字符,计算机就是根据二进制数从字库表中找到字符然后显示给用户,相当于一个存储字符的数据库。
b. 例如:几乎所有汉字都保存在GBK 编码规范的字库表中。所以可以显示汉字,但法语,俄语并不在其字库表中,所以GBK不能显示法语,俄语等不包含在其中的字符。
b. 编码字符集(字符集)
a. 在一个字库表中,每一个字符都有一个对应的二进制地址,而编码字符集就是这些地址的集合。
b. 在ASCII码的编码字符集中,字母A的序号(地址)是65,65的二进制就是01000001。我们可以说编码字符集就是用来存储这些二进制数的。而这个二进制数就是编码字符集中的一个元素,同时它也是字库表中字母A的地址。我们根据这个地址就可以显示出字母A
c. 结论:字符集和字库表一一对应,相互转换,这是电脑识别字符的关键
c. 字符编码(编码方式)
a. 程序员制定了一套算法来节省空间,而每种不同的算法都被称作一种编码方式
b. 例如:UTF-8就是一种编码方式,Unicode是一种编码规范。此外,Unicode还有UTF-16,UTF-32这两种编码方式。不同的编码方式节约的空间不同
c. 一个较短的二进制数,通过一种编码方式,转换成编码字符集中正常的地址,然后在字库表中找到一个对应的字符,最终显示给用户
常见的编码规范
1. ASCII码
· 计算机内部, 所有信息最终都是一个二进制值, 每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte),也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,从00000000到11111111
· 上世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定,这被称为ASCII码,一直沿用至今。
· ASCII码一共规定了28个字符的编码,这128个符号(包括32个不能打印处理的控制符号),只占用了一个字节的后面7位,最前面的一位统一规定为0
2. 非ASCII编码
· 英语用128个符号编码就够了,但是用例表示其他语言,128个符号时不够的。
· 一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号,这样一来,这些欧洲国家使用的编码体系,可以表示最多256个符号
· 但是,不同的国家有不同的字母,因此,哪怕他们都使用256个符号的编码方式,代表的字符却不一样。但是不管怎样,所有这些编码方式中,0-127表示的符号是一样的,不一样的只是12-255的这一段
· 至于亚洲国家的文字,使用的符号就更多了,一个字节只能表示256种符号,肯定是不够的,就必须使用多个字节表示一个汉字,比如,简体中文常见的编码方式是GB2312,使用俩个字节表示一个汉字。
3. Unicode
· Unicode将世界上所有的符号都纳入其中,每一个符号都给予一个独一无二的编码,这就是Unicode,就像它的名字表示的,这是一种所有符号的编码
· Unicode当然是一个很大的集合,现在的规模可以容纳100多万个符号
4. Unicode的问题
· Unicode只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储
· 一个符号的表示至少需要2个字节,表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多
· 就出现了两个严重的问题,如何才能区别Unicode和ASCII?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号?
· 第二个问题是,英文字母只用一个字节表示就够了,如果Unicode统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储起来是极其浪费
· 于是出现了Unicode的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示Unicode
· Unicode在很长一段时间内无法推广,直到互联网的出现
5. UTF-8
· 互联网的普及,强烈要求出现一种统一的编码方式。
· UTF-8就是在互联网上使用最广的一种Unicode的实现方式,其他实现方式还包括UTF-16(字符用两个字节或四个字节表示)和UTF-32(字符用四个字节表示)
· UTF-8是Unicode的实现方式之一
· UTF-8最大的特点,就是它是一种变长的编码方式,它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度
· UTF-8的编码规则:
o
a. 对于单字节的符号,字节的第一位设为0.后面7位为这个符号的Unicode码,因此对于英语字母,UTF-8编码和HSCII码是相同的
b. 对于n字节的符号(n>1),第一个字节的前n位都设位1,第n+1位设为0,后面字节的前两位一律设为10,剩下的没有提及的二进制位,全部为这个符号的Unicode码
以上是 字符集和字符编码 的全部内容, 来源链接: utcz.com/z/530569.html