Python爬取素材网站3000多条音频素材文件

前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
python免费学习资料以及群交流解答点击即可加入
基本环境配置
- python 3.6
- pycharm
- requests
- parsel
相关模块pip安装即可
主要是前几天
目标网页
请求网页
import requestsurl = "https://www.tukuppt.com/peiyue/zonghe_0_0_0_0_0_0_1.html"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36",
}
response = requests.get(url=url, headers=headers)
解析网页,提取数据
import parselselector = parsel.Selector(response.text)
urls = selector.css("#audio850995 source::attr(src)").getall()
titles = selector.css(".b-box .info .title::text").getall()
data = zip(urls, titles)
for i in data:
mp3_url = "https:" + i[0]
title = i[1]
保存数据
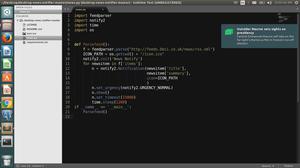
def download(url, title): response = requests.get(url=url, headers=headers)
path = "D:pythondemo熊猫办公素材背景音乐" + title + ".mp3"
with open(path, mode="wb") as f:
f.write(response.content)
以上是 Python爬取素材网站3000多条音频素材文件 的全部内容, 来源链接: utcz.com/z/530551.html