Day3:函数与函数式编程

定义(关键字def):
编程语言中函数定义:函数是逻辑结构化和过程化的一种编程方法(函数是指将一组语句的集合通过一个名字(函数名)封装起来,要想执行这个函数,只需调用其函数名即可)
函数特性:
1.减少重复代码
2.使程序变得可扩展
3.使程序变得易维护
格式:
1def func1(): # 函数名func12"""这里是注释"""
3 代码块
4return 值
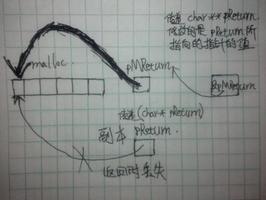
注:过程是缺少返回值的函数(在python中,过程实际是返回值为None的函数);想要查看返回值,可以将调用函数的结果赋给一个变量
1import time 23
4def logger():
5"""追加内容至文档a中,并标识时间"""
6 time_format = "%Y-%m-%d %X"
7 time_current = time.strftime(time_format)
8 with open("a.txt", "a+", encoding="utf-8") as f:
9 f.write(f"{time_current} Yesterday once more-昨日重现
")
10 f.close()
11def test1():
12print("In the test1")
13 logger()
14def test2():
15print("In the test2")
16 logger()
17def test3():
18print("In the test3")
19 logger()
20 test1() # 调用函数test1
21 test2() # 调用函数test2
22 test3() # 调用函数test3
函数特性实例
可以返回的值:
1.什么都不写:返回None
2.return 0:返回0
3.return 1,’hello’,[‘sjc’,’wk’],{‘name’:’sjc’}:返回元组(1,’hello’,[‘sjc’,’wk’],{‘name’:’sjc’})
为什么要有返回值:后续其他逻辑可能会根据返回值的不同进行不一样的操作
def test1():print("in the test1")def test2():print("in the test2")return 0def test3():print("in the test3")return 1, "hello", ["sjc", "wk"], {"name": "sjc"}x
= test1()y
= test2()z
= test3()print(x, "", y, "", z, sep="")
return
1in the test12in the test23in the test34None506 (1, "hello", ["sjc", "wk"], {"name": "sjc"})
output
形参与实参:
形参:变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量
实参:可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。因此应预先用赋值,输入等办法使参数获得确定值
注意:传参时实参与形参是一一对应的(位置参数),若想不按顺序传入,需要用 传参=实参(关键字参数)的方式,但是,关键字参数必须位于位置参数后方
默认参数:
调用函数的时候,默认参数非必须传递,不传递时则取默认值,传递则取传递值
参数组:
形参以*开始+一个变量名,一般为*args(规范,尽量别改),会把所有传入参数放入一个元组,只接收位置参数
想传入字典呢?试试**kwargs且用关键字参数传参(或者用**+字典的方式传参)
再试试参数组与参数组、形参、默认参数结合
注意:参数组尽量往后放
1def test(x, y): 2print(x) 3print(y) 45
6 test(1, 2)
7 test(y="关键参数y", x="关键参数x")
8
9
10def test2(x, y="我是默认参数"):
11print(x)
12print(y)
13
14
15 test2(1)
16 test2(y="赋值后默认参数会改", x=4)
17
18
19def test3(*args):
20print(args)
21
22
23 test3(1, 2, 4, 8, 9)
24
25
26# 传入参数个数不固定时
27# *args:把N个位置参数转换成元组的方式
28def test4(x, *args):
29print(x)
30print(args)
31
32
33 test4(5, 6, "参数不固定", 8, 10)
34 test4(*[5, 6, "参数不固定", 8, 10]) # args = tuple([5, 6, "参数不固定", 8, 10])
35
36
37# 把N个关键字参数转换成字典的方式
38def test5(**kwargs):
39print(kwargs)
40print(kwargs["name"]) # 取字典中key为name的value(key不存在会报错)
41
42
43 test5(name="sjc", age=18)
44 test5(**{"name": "sjc", "age": 18, "size": "unknown"})
45
46
47def test6(name, age=18, *args, **kwargs):
48print(name)
49print(age)
50print(args)
51print(kwargs)
52
53
54 test6("SJC", 12, 5, hobby="game")
parameters
12
关键参数x
关键参数y
1
我是默认参数
4
赋值后默认参数会改
(1, 2, 4, 8, 9)
5
(6, "参数不固定", 8, 10)
5
(6, "参数不固定", 8, 10)
{"name": "sjc", "age": 18}
sjc
{"name": "sjc", "age": 18, "size": "unknown"}
sjc
SJC
12
(5,)
{"hobby": "game"}
Process finished with exit code 0
output
局部变量:
只在函数中生效(在函数内部代码块位置定义的变量)/可用global将局部变量改为全局变量(尽量别用)
全局变量:
在整个代码顶层定义的变量
当全局变量与局部变量同名时:在局部变量内修改变量值,当变量是字符串或整型时,调用函数是修改后的值,但调用结束后全局变量是不变的(在定义局部变量的子程序内,局部变量起作用;在其它地方全局变量起作用);当变量是列表等类型时,使用局部变量修改列表内某些值,调用函数结束后全局变量也随之改变。
1# def change_name(name):2# print("before change", name)
3# name = "SJC" # 这个函数就是这个变量的作用域
4# print("after change", name)
5#
6# name = "sjc"
7# change_name(name)
8# print(name)
9
10 name = "SJC"
11 name1 = [1, 2, 3]
12
13
14def change_name():
15 name = "sjc"
16 name1[0] = 8
17print(name, name1)
18
19
20print(name, name1)
21change_name()
22print(name, name1)
variable
1 SJC [1, 2, 3]2 sjc [8, 2, 3]3 SJC [8, 2, 3]
output
递归:
在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。
递归特性:
1.必须有一个明确的结束条件
2.每次进入更深一层递归时,问题规模相比上次递归都应有所减少
3.递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
1def calc(n):2if n/2 > 0:3print(n)4return calc(int(n/2))5print(n)67
8 calc(10)
recursion
1 102 5
3 2
4 1
5 0
output
函数式编程:知乎“什么是函数式编程思维?”
高阶函数:
变量可以指向函数,函数的参数能接收变量,那么一个函数就可以接收另一个函数作为参数,这种函数就称之为高阶函数。
1def add(a, b, f):2return f(a)+f(b)34
5 res = add(3, -6, abs)
6print(res)
higher-order
上例输出为 9
以上是 Day3:函数与函数式编程 的全部内容, 来源链接: utcz.com/z/529957.html