再谈HashMap,如何使用map优化代码

我并没有和HashMap杠上,想着重新开始写点技术的东西,就拿HashMap开头了。最近开始重新学习数据结构和算法,其中有些东西学完之后,对于HashMap的理解和运用又有新的认识。虽然之前运用HashMap也有这样用过,但是知道了方法论,才发现这样使用的好处。
上一期我写过HashMap,写的是JDK8之前的Hash,现在都JDK15了,大家有兴趣可以去看一下源计划之从HashMap认识数据结构
JDK8的HashMap
现在大家基本上使用的JDK版本都是8以上,所以JDK8的HashMap更有实用价值,那么JDK8之后,针对HashMap做了哪些优化呢?
hash方法变化
JDK8之后的Hash算法:
static final int hash(Object key) { int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
JDK7的hash算法:
static int hash(int h) {h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
可以发现,JDK8之后使用了三元运算符,计算了2次,一次右移运算,一次异或运算。
而JDK7中的进行了4次右移运算,进行了四次扰动,JDK在Hash算法上提高了性能。
存储数据结构的变化
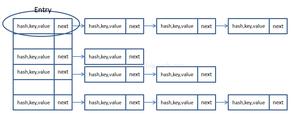
JDK8之前,发生了Hash碰撞之后,同一个node节点,将存储在链表中。
JDK8之后发生的变化
当同一个node节点存储数据大小达到8之后,存储结构会将链表变成红黑树。
那么node节点存储数据大小一开始达到了8,后来map数据减少,该node数据大小小于8,node节点的存储结构是否还是红黑树?
- 答案:node有可能是红黑树,也有可能会退化到链表结构,因为退化阈值并不是8,而是6。
下面的HashMap源码可以发现,当node节点数据大小小于6的时候,才会将红黑树转化为链表结构。
static final int TREEIFY_THRESHOLD = 8;static final int UNTREEIFY_THRESHOLD = 6;
if (loHead != null) {
if (lc <= UNTREEIFY_THRESHOLD)
tab[index] = loHead.untreeify(map);
else {
tab[index] = loHead;
if (hiHead != null) // (else is already treeified)
loHead.treeify(tab);
}
}
退化阀值为什么会是6,而不是8?
- 答案: 虽然在查询效率上,链表结构的时间复杂度是$$O(n)$$红黑树时间复杂度是$$O(logn)$$,但是红黑树就是一种特殊的二叉树,红黑树在极端的情况下,其实是会变成像链表一样,数据量小的情况下,也最容易发生这种情况,在这种情况下,红黑树的查询时间复杂度和链表是一样的,趋近于O(n),但是红黑树的树节点比普通节点内存大2倍,在空间上是不如链表的,而以后阀值为6,而不和转化为红黑树的阀值一样,是为了避免反复转化。(这些源码是有参考意义的,在我们的业务代码中也可以用这种方式来避免反复的转换)
HashMap扩容时,将头插法改为了尾插法
为什么会出现这种变化呢?在JDK8之前的版本中,多线程操作下,HashMap会出现死循环的问题,而这种问题的导致原因就是因为,HashMap在扩容的时候,头插法,在链表头部插入,导致原有数据的链表位置发生的改变,就会出现下面的情况,形成环形链表,导致死循环。
JDK8以后改成了尾插法,原有数据的链表位置不发生改变,就不会出现上述情况。
但是即便是这样,HashMap也不是线程安全的,HashMap还是无法保证上一秒put的值,下一秒get的时候还是原值,因为put和get方法并没有加锁。
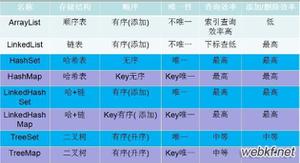
正确使用HashMap
在项目中我们经常用HashMap来缓存数据,但是阿里开发手册规范写明,创建HashMap时候,要指定HashMap的容量,最好是2的幂。
为什么是2的幂
- 答案: 这样是为了保证位运算方便,这样可以减少hash碰撞,数据分配均匀。
利用HashMap缓存数据
这个是经常使用到的优化,这里面要关注的是多线程情况下,HashMap的线程安全问题,在多线程情况下,更推荐使用CurrentHashMap
利用HashMap减少for循环
我们来看一个算法题:
输入数组 a = [1,2,3,4,5,5,6 ] 中,查找出现次数最多的数值。
第一种解法:
public void s1() { int a[] = { 1, 2, 3, 4, 5, 5, 6 };
int val_max = -1;
int time_max = 0;
int time_tmp = 0;
for (int i = 0; i < a.length; i++) {
time_tmp = 0;
for (int j = 0; j < a.length; j++) {
if (a[i] == a[j]) {
time_tmp += 1;
}
if (time_tmp > time_max) {
time_max = time_tmp;
val_max = a[i];
}
}
}
System.out.println(val_max);
}
可以发现,这是一种常见的思维,用了双重循环,遍历了两次,时间复杂度是$$O(n^2)$$
那么还要什么更优的解法嘛,可以引入HashMap,记录下每个元素出现的次数,解法如下:
public void s2() { int a[] = { 1, 2, 3, 4, 5, 5, 6 };
Map<Integer, Integer> d = new HashMap<>();
for (int i = 0; i < a.length; i++) {
if (d.containsKey(a[i])) {
d.put(a[i], d.get(a[i]) + 1);
} else {
d.put(a[i], 1);
}
}
int val_max = -1;
int time_max = 0;
for (Integer key : d.keySet()) {
if (d.get(key) > time_max) {
time_max = d.get(key);
val_max = key;
}
}
System.out.println(val_max);
}
上述解法,也用了两层for循环,但是不是嵌套的,所以时间复杂度是O(2n),由于时间复杂度和系数无关,所以上述解法的时间复杂度为$$O(n)$$
在大多数业务场景下去除嵌套循环,都可以采用上述方式,可以减少时间复杂度,但也是有前提条件的,前提条件就是外层或者内层循环的遍历次数是已知数据量较小, 过大的数据量,可能会导致内存溢出,而且过多的数据,HashMap也会发生Hash碰撞,存储结构会变成数组+链表,甚至+红黑树,这个时候的HashMap查询复杂度就会变成O(n)或者O(logn)。
HashMap需要我们进行正确的使用他,但是不能滥用,我之前在的一家公司,就见过有人把10万条数据读取到HashMap上存储,每条数据所在内存还比较大,然后进行转换,到4万条数据的时候,就内存溢出了。
HashMap是存储在内存上的,使用的时候,一定要尽量避免内存溢出情况。
HashMap扩容
HashMap的扩容是没有太多变化的。
其实本文没有去讲JDK8的扩容机制,主要去讲了JDK8HashMap的优化点,以及如何使用HashMap去优化我们的代码。
其实扩容机制还有一个问题:为什么HashMap的负载因子是0.75?
- 答案:假设负载因子为1的情况,那么一个默认容量为16的HashMap,只有当table数据结构16个位置都被占满了,才会发生扩容,那么出现Hash冲突的情况会增加,底层的红黑树变得异常复杂,牺牲了时间,保住了空间。反之过小的负载因子,会过早的进行扩容,Hash冲突减小了,可是牺牲了空间,0.75是一个中庸的选择。
最后
下次,我们看看CurrentHashMap是如何保证线程安全的,以及其他的Map;以及谷歌的开源项目Guava中那些比较特殊的Map。
题外话:因为年前自己也搭了个人博客,想着不写点什么,可惜了,所以现在开始,后续保证一周两篇的输出,也督促自己不断加强学习。
本文由博客群发一文多发等运营工具平台 OpenWrite 发布
以上是 再谈HashMap,如何使用map优化代码 的全部内容, 来源链接: utcz.com/z/519557.html