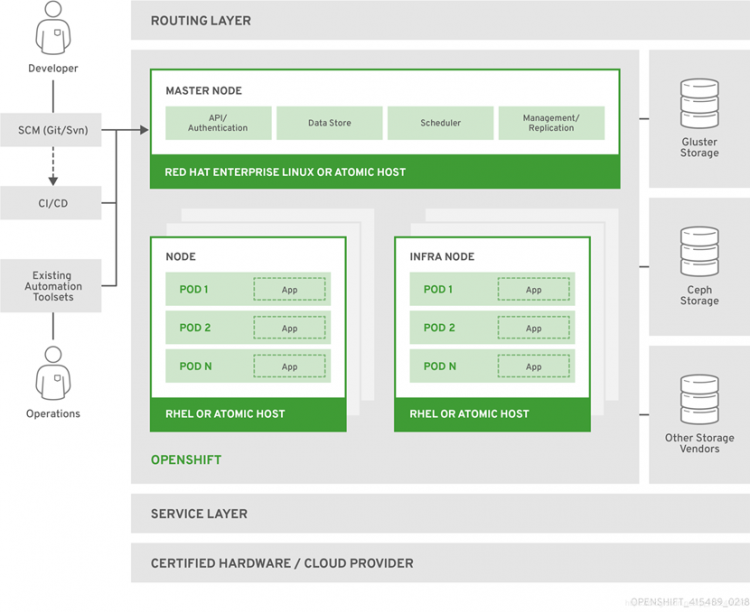
附001.Nginxlocation语法规则

一 location规则1.1 location语法
基本语法: location [=|~|~*|^~]/uri/{...}修饰符释义: 1 = #表示精确严格匹配,只有请求的url路径与后面的字符串完全相等时,才会命中。同时若这个查询匹配,将停止搜索并立即处理此请求。 2 ~ #表示该规则是使用正则定义的,且区分大小写;
3 ^~ #表示uri以某个常规字符串开头,匹配 URI 路径。且nginx不对url做编码,如请求为/static/20%/aa,可以被规则^~ /static/ /aa匹配到(注意是空格);
4 ~* #表示该规则是使用正则定义的,且不区分大小写;
5 / #用户所使用的代理(一般为浏览器);
1 $http_x_forwarded_for #通过代理服务器来记录客户端的ip地址; 2 $http_referer #记录用户是从哪个链接访问过来的。
1.2 location匹配过程
对请求的url序列化。例如,对%xx等字符进行解码,去除url中多个相连的/,解析url中的.,..等。这一步是匹配的前置工作。location有两种表示形式,一种是使用前缀字符,一种是使用带~或~*修饰符的正则。其相应的匹配过程如下:- 如果找到了精确匹配的location,也就是使用了=修饰符的location,结束查找,使用它的配置。
- 所有剩下的常规字符串,采用最长匹配;
- 继续判断正则表达式的解析结果,按配置里的正则表达式顺序为准,由上至下开始匹配,一旦匹配成功1个,立即返回结果,并结束解析过程。
- 如果第3条规则产生匹配的话,结果被使用。否则,使用第2条规则的结果。
注意:普通命中顺序无所谓,是因为按命中的长短来确定。正则命中,顺序有所谓,因为是从前入往后命中的。
基于以上的匹配过程,我们可以得到以下两点启示:- 使用正则定义的location在配置文件中出现的顺序很重要。因为找到第一个匹配的正则后,查找就停止了,后续定义的匹配(不管精度如何)都不再进行查找。
- 使用精确匹配可以提高查找的速度。例如经常请求/的话,可以使用=来定义location。
1.3 location匹配优先级
由location匹配规则可知,其匹配优先级为:(location =) > (location 完整路径) > (location ^~ 路径) > (location ~,~* 正则顺序) > (location 部分起始路径) > (/) 。
二 location规则示例2.1 环境预设
1 [root@nginx01 ~]# vi /etc/nginx/conf.d/location.conf 2 server {
3 listen 80;
4 server_name location.linuxds.com;
5 access_log /var/log/nginx/location.access.log main;
6 error_log /var/log/nginx/location.error.log warn;
7 location = / {
8 add_header Content-Type text/plain;
9return 200 "A";
10# 精确匹配 / ,主机名后面不能带任何字符串
11 }
12 location = /login {
13 add_header Content-Type text/plain;
14return 200 "B";
15 }
16 location ^~ /static/ {
17 add_header Content-Type text/plain;
18return 200 "C";
19# 匹配任何以 /static/ 开头的地址,匹配以后,不在往下检索正则,立即采用这一条。
20 }
21 location ^~ /static/files {
22 add_header Content-Type text/plain;
23return 200 "D";
24# 匹配任何以 /static/files 开头的地址,匹配以后,不在往下检索正则,立即采用这一条。
25 }
26 location ~ .(gif|jpg|png|js|css|txt) {
27 add_header Content-Type text/plain;
28return 200 "E";
29 }
30 location ~* .txt$ {
31 add_header Content-Type text/plain;
32return 200 "F";
33# 匹配所有以 txt 结尾的请求
34# 然而,所有请求 /static/ 下的txt会被 规则 C 处理,因为 ^~ 到达不了这一条正则。
35 }
36 location /image {
37 add_header Content-Type text/plain;
38return 200 "G";
39# 匹配任何以 /image/ 开头的地址,匹配符合以后,还要继续往下搜索;
40# 只有后面的正则表达式没有匹配到时,这一条才会采用这一条。
41 }
42 location / {
43 add_header Content-Type text/plain;
44return 200 "H";
45# 因为所有的地址都以 / 开头,所以这条规则将匹配到所有请求。
46# 但是正则和最长字符串会优先匹配。
47 }
48 }
1 [root@nginx ~]# nginx -t -c /etc/nginx/nginx.conf #检查配置文件 2 [root@nginx ~]# nginx -s reload #重载配置文件
2.2 匹配测试
访问:http://location.linuxds.com/,将匹配规则A:访问:http://location.linuxds.com/login,将匹配规则B:访问:http://location.linuxds.com/static/test.html,将匹配规则C:访问:http://location.linuxds.com/static/files/test.txt,将匹配规则D:解释:虽然也符合规则C,但基于最大匹配原则,因此优先选择规则D。访问:http://location.linuxds.com/test.txt,将匹配规则E:解释:虽然也符合规则F,但正则中基于顺序优先,因此优先选择规则E。访问:http://location.linuxds.com/static/test.txt,将匹配规则C:解释:虽然也符合规则F,但基于匹配优先级^~ > ~,~*,因此优先选择规则C。访问:http://location.linuxds.com/test.TXT,将匹配规则G:解释:规则E区分大小写,规则F不区分大小写,因此优先选择规则F。访问:http://location.linuxds.com/image/test.txt,将匹配规则E:解释:虽然也符合规则Y,但基于正则匹配优先,因此优选选择规则E。访问:http://location.linuxds.com/image/test.tiff,将匹配规则G:解释:没有更高优先级的其他规则(正则或=),因此匹配规则G。访问:http://location.linuxds.com/work/1234,将匹配规则I:解释:如上除H之外所有规则都不匹配,所有的地址都以 / 开头,所以这条规则将作为最后匹配规则。参考:http://www.zzvips.com/article/33760.htmlhttps://juejin.im/post/5ce5e1f65188254159084141http://www.zzvips.com/article/33760.htmlhttps://www.nginx.cn/doc/standard/httpcore.html #官方参考三 正则与判断参考:https://blog.csdn.net/weixin_33726943/article/details/86007331
2 ~ #表示该规则是使用正则定义的,且区分大小写;
3 ^~ #表示uri以某个常规字符串开头,匹配 URI 路径。且nginx不对url做编码,如请求为/static/20%/aa,可以被规则^~ /static/ /aa匹配到(注意是空格);
4 ~* #表示该规则是使用正则定义的,且不区分大小写;
5 / #用户所使用的代理(一般为浏览器);
2 $http_referer #记录用户是从哪个链接访问过来的。
2.1 环境预设
1 [root@nginx01 ~]# vi /etc/nginx/conf.d/location.conf2 server {
3 listen 80;
4 server_name location.linuxds.com;
5 access_log /var/log/nginx/location.access.log main;
6 error_log /var/log/nginx/location.error.log warn;
7 location = / {
8 add_header Content-Type text/plain;
9return 200 "A";
10# 精确匹配 / ,主机名后面不能带任何字符串
11 }
12 location = /login {
13 add_header Content-Type text/plain;
14return 200 "B";
15 }
16 location ^~ /static/ {
17 add_header Content-Type text/plain;
18return 200 "C";
19# 匹配任何以 /static/ 开头的地址,匹配以后,不在往下检索正则,立即采用这一条。
20 }
21 location ^~ /static/files {
22 add_header Content-Type text/plain;
23return 200 "D";
24# 匹配任何以 /static/files 开头的地址,匹配以后,不在往下检索正则,立即采用这一条。
25 }
26 location ~ .(gif|jpg|png|js|css|txt) {
27 add_header Content-Type text/plain;
28return 200 "E";
29 }
30 location ~* .txt$ {
31 add_header Content-Type text/plain;
32return 200 "F";
33# 匹配所有以 txt 结尾的请求
34# 然而,所有请求 /static/ 下的txt会被 规则 C 处理,因为 ^~ 到达不了这一条正则。
35 }
36 location /image {
37 add_header Content-Type text/plain;
38return 200 "G";
39# 匹配任何以 /image/ 开头的地址,匹配符合以后,还要继续往下搜索;
40# 只有后面的正则表达式没有匹配到时,这一条才会采用这一条。
41 }
42 location / {
43 add_header Content-Type text/plain;
44return 200 "H";
45# 因为所有的地址都以 / 开头,所以这条规则将匹配到所有请求。
46# 但是正则和最长字符串会优先匹配。
47 }
48 }
1 [root@nginx ~]# nginx -t -c /etc/nginx/nginx.conf #检查配置文件2 [root@nginx ~]# nginx -s reload #重载配置文件
2.2 匹配测试
访问:http://location.linuxds.com/,将匹配规则A:访问:http://location.linuxds.com/login,将匹配规则B:访问:http://location.linuxds.com/static/test.html,将匹配规则C:访问:http://location.linuxds.com/static/files/test.txt,将匹配规则D:解释:虽然也符合规则C,但基于最大匹配原则,因此优先选择规则D。访问:http://location.linuxds.com/test.txt,将匹配规则E:解释:虽然也符合规则F,但正则中基于顺序优先,因此优先选择规则E。访问:http://location.linuxds.com/static/test.txt,将匹配规则C:解释:虽然也符合规则F,但基于匹配优先级^~ > ~,~*,因此优先选择规则C。访问:http://location.linuxds.com/test.TXT,将匹配规则G:解释:规则E区分大小写,规则F不区分大小写,因此优先选择规则F。访问:http://location.linuxds.com/image/test.txt,将匹配规则E:解释:虽然也符合规则Y,但基于正则匹配优先,因此优选选择规则E。访问:http://location.linuxds.com/image/test.tiff,将匹配规则G:解释:没有更高优先级的其他规则(正则或=),因此匹配规则G。访问:http://location.linuxds.com/work/1234,将匹配规则I:解释:如上除H之外所有规则都不匹配,所有的地址都以 / 开头,所以这条规则将作为最后匹配规则。参考:http://www.zzvips.com/article/33760.htmlhttps://juejin.im/post/5ce5e1f65188254159084141http://www.zzvips.com/article/33760.htmlhttps://www.nginx.cn/doc/standard/httpcore.html #官方参考三 正则与判断参考:https://blog.csdn.net/weixin_33726943/article/details/86007331
原文链接:https://www.cnblogs.com/itzgr/archive/2020/07/22/13359249.html
以上是 附001.Nginxlocation语法规则 的全部内容, 来源链接: utcz.com/z/518582.html