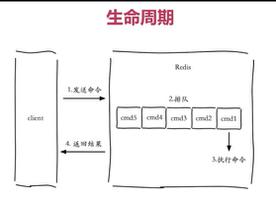
redis核心特性

Redis 概念
redis 基于内存存储的数据库,具有内存数据缓存和消息队列等功能,数据类如下:String 存储常用的数据类型
set key value ex 5s
set key value px 5000ms
get key
批量操作
mset key value key1 values1 ...
mget key key1
incr key --整形自增
incr key value --按照value 自增
decr key --整形自减
incrbyfloat --float自增
append --追加字符串
getrange key start end --范围查找
setrange key index value --设置指定位置值
strlen key --字符串长度
hash 散列存储数据
HSET key fields value
HGET key fields...
HGETALL key
HKEYS key --所有的属性fields
HVALS key --所有的属性值
HSETNX key fields value --不存在则设置
HEXISTS key fields --是否存在属性
HINCRBY key fields value --对属性进行自增
HLEN key --有多少属性
list 双端队列,不利遍历查找,可进行头尾访问操作
lpush key values ... --从左边放入
LRANGE key 0 -1 --获取左边的数据
rpush key values ... --从右边放入
lpop key --从左弹出
rpop key --从右弹出
BLPOP key1 key2 --阻塞队里拿
llen key --取数量
lren key 次数 value --移除指定value 几次
ltrim key start stop --留下指定start到stop位置的元素
linsert key before value value2 --在value之前插入value2
lset key index 3 value --设置指定位置的元素为value
lindex key index --查询指定位置的元素
set 不重复集合,可方便进行交并集的运算操作
sadd key value1 value2 ...--添加元素到集合
SMEMBERS key --取集合数据
spop key index --弹出指定位置的元素
SRANDMEMBER key count --随机返回指定count的元素
SREM key value --移除指定value
Sinter key1 key2 --取集合的交集
sinterStore key key1 key2 --将集合key1和key2 的交集存储到key集合中
sunion key1 key2 --取并集
sunionStore key key1 key2 --将集合key1和key2 的并集存储到key集合中
sdiff key1 key2 -- 从集合key1中去掉key2中的重复元素
scard key --获取集合中元素数量
sorted set 有序集合,放入的时候已进行排序
zadd key score1 value1 score2 value2 ...--添加元素
ZRANGE key start end withscores -- 获取指定下标的元素,默认按照score 升序
zcard key --获取集合的数量
zscore key value --获取指定value的排名分数
zrank key value --获取value对应的排名位次
zcount key (min (max -- 获取score分数在min到max区间的数量
zrangebyscore key score1 score2 --获取score1 到score2 分数之间元素
zrevrange key 0 5 --score倒序返回元素
Redis 核心功能
- 持久化策略
RDB 内存快照,异步保存的方式,fork子线程完成写入,不影响redis主线程,是基于Copy-on-Writer机制实现;
适合于灾难恢复,fork子线程来进行日志写入,不影响主线程,大量数据恢复速度比AOF方式快
AOF 执行命令加入的文件,会重写文件和压缩存储
AOF文件写入时候如果宕机,会造成文件出错,redis重启则不会加载AOF文件,可用redis-check-aof 程序修复;
丢失数据少,几乎实时写入,大量数据的情况下,AOF恢复比RDB要慢许多;
混合日志
集成了RDB和AOF的优点
aof-use-rdb-preamble yes
注意:对于内存数据可靠性要求高的话,需要写定期脚本备份数据;
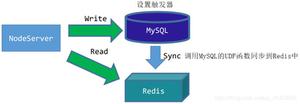
- 内置复制
集群和分布式具有的基本特性;有利于多读少写的应用性能
并发过高的情况下,要考虑master-slaver,提高读写性能,
从节点会主动发送sync命令获取数据快照,主节点采用异步的方式,基于copy-on-wirter,接受RDB快照数据;
从节点会丢弃自己已有数据,加载主服务器的数据快照;
- 事务
原子操作,提交多个操作命令,决定同成功或者同失败
原子性,隔离性,redis不支持回滚,例子如下:
MULTI命令操作1;命令操作2......
EXEC
redis-check-aof 程序可修复,由于事务不完整造成的错误数据,导致redis服务不能启动;
- Lua脚本
支持Lua脚本,批量操作Redis命令集
- Pipeline
管道操作,批量发送多个命令,提高访问性能,减少网络的消耗;
- 缓存策略
LRU 最久没有使用
LFU 最近使用频率最少的键
TTL 最少剩余时间的key先删掉
清理方式:消极删除 和 主动定期清除
- Cluster模式
将数据切分到多个节点,提高并发访问能力,部分节点失效,不会导致集群服务的不可用
哈希槽 16384个槽位,每个槽位不能缺少,否则整个集群不可用
Cluster 集群
Sentinel哨兵模式
提供监控、提醒、自动故障转移,保障redis高可用
客户端连接后,通过sentinel集群通信,获取集群的信息,sentinel和master直接访问
大致流程如下图:
Redis 常用业务场景
业务热点数据,不让频繁访问DB
统计数量,实时更新或者定时更新统计
时效信息 基于时间要求的数据,到时自动清除
关注功能 可以用redis set集合取交并集
Redis 常见问题
缓存击穿--并发访问,击穿了缓存
缓存穿透--查询不存在的数据,可以缓存null数据
缓存雪崩--缓存集体时效,服务大面积打点到节点,导致服务瘫痪
以上是 redis核心特性 的全部内容, 来源链接: utcz.com/z/518436.html