手写一个HashMap

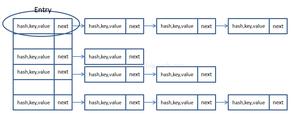
大家都知道JDK7前HashMap底层是数组+链表,JDK8以后当链表长度>8的时候会自动变为红黑树。本文基于数+链表实现一个简化版的HashMap,有助于理解HashMap的底层原理。在此之前,结合下图,先了解一下相关的基础知识
Put的过程
对key的hashCode()做hash运算,计算元素存放在数组的位置;
如果该位置没有元素,则放在该位置; 如果已存在元素,即发生Hash碰撞,以链表的形式存在于该元素后,当然若key已经存在就替换旧值(保证key的唯一性);如果碰撞导致链表过长(>=8),就把链表转换成红黑树(JDK1.8中的改动);
如果元素的个数太多(条件后面再说),需要扩容
get的过程
对key的hashCode()做hash运算,计算位置; 如果在数组里的第一个节点里直接命中,则直接返回; 如果有冲突,则遍历链表去寻找;
何时扩容?
当hashmap中的元素个数超过数组大小*loadFactor时,就会进行数组扩容。loadFactor默认0.75,hashmap默认长度16,也就是说第一次扩容发生在16*0.75=12的时候,将扩容一倍,也就是说32
因为红黑树需要进行左旋,右旋,变色这些操作来保持平衡,而单链表不需要。 当元素小于8个当时候,此时做查询操作,链表结构已经能保证查询性能。当元素大于8个的时候,此时需要红黑树来加快查询速度,但是新增节点的效率变慢了。
当链表转为红黑树后,什么时候退化为链表?
为6的时候退转为链表。中间有个差值7可以防止链表和树之间频繁的转换。假设一下,如果设计成链表个数超过8则链表转换成树结构,链表个数小于8则树结构转换成链表,如果一个HashMap不停的插入、删除元素,链表个数在8左右徘徊,就会频繁的发生树转链表、链表转树,效率会很低。
当两个对象的hashcode相同会发生什么?
因为hashcode相同,所以它们的bucket位置相同,‘碰撞’会发生。因为HashMap使用链表存储对象,这个Entry(包含有键值对的Map.Entry对象)会存储在链表中。
直接上代码
/**
* @author HeyS1
* @date 2020/6/4
* @description
*/
public class MyHashMap<K, V> {
@Data
static class Entry<K, V> {
private Entry<K, V> next;
private K key;
private V value;
Entry(Entry<K, V> next, K key, V value) {
this.next = next;
this.key = key;
this.value = value;
}
}
//数组默认长度
private static final int DEFAULT_INITIAL_CAPACITY = 16;
//默认阈值比例
private static final float DEFAULT_LOAD_FACTOR = 0.75f;
//数组长度
private int arraySize;
//阈值比例
private float loadFactor;
//一共存储了多少个entry
private int entryUseSize;
//存储数组
private Entry<K, V>[] table;
public MyHashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
public MyHashMap(int arraySize, float loadFactor) {
this.arraySize = arraySize;
this.loadFactor = loadFactor;
table = new Entry[this.arraySize];
}
public void put(K k, V v) {
//获取entry在数组中存放的位置
int index = getIndex(k);
Entry<K, V> t = table[index];
if (t == null) {
//如果该位置不存在元素,则放入即可
table[index] = createEntry(k, v);
}
//若已存在元素
else {
if (keyEquals(t, k)) {
//若该位置的元素key与放入元素的key是一致的,则替换value
t.value = v;
} else {
//遍历链表
while (t != null) {
if (t.next == null) {
t.next = createEntry(k, v);
break;
}
if (keyEquals(t.next, k)) {
t.next.value = v;
break;
}
t = t.next;
}
}
}
//若entry数量 >= 数组长度 * 阈值,则进行扩容
if (entryUseSize >= arraySize * loadFactor) {
resize(2 * entryUseSize);
}
}
public V get(K k) {
int index = getIndex(k);
Entry<K, V> t = table[index];
if (keyEquals(t, k)) {
return t.value;
}
//遍历链表寻找元素
while (t.next != null) {
if (keyEquals(t.next, k)) {
return t.next.value;
}
t = t.next;
}
return null;
}
/**
* 扩容 (即将所有元素重新hash放入一个更大的数组)
*
* @param i
*/
private void resize(int i) {
arraySize = i;//重置数组长度为i
entryUseSize = 0;//重置记录元素长度为0
//将所有元素都放入List
List<Entry<K, V>> list = new ArrayList<>();
for (int j = 0; j < table.length; j++) {
if (table[j] == null) {
continue;
}
list.add(table[j]);
while (table[j].next != null) {
list.add(table[j].next);
table[j] = table[j].next;
}
}
//新建一个容量更大的数组并且将所有元素put进去
table = new Entry[i];
for (Entry<K, V> kvEntry : list) {
put(kvEntry.getKey(), kvEntry.getValue());
}
}
private Entry<K, V> createEntry(K k, V v) {
entryUseSize++;//记录元素数量,每次创建一个Entry数量都要自增1,用于计算是否需要扩容
return new Entry<>(null, k, v);
}
/**
* 判断Key是否一致
*
* @param entry 某元素
* @param key key
* @return
*/
private boolean keyEquals(Entry entry, K key) {
return entry.getKey() == key || (entry.getKey() != null && entry.getKey().equals(key));
}
/**
* 根据hash获取元素在数组的位置
*
* @param k
* @return
*/
private int getIndex(K k) {
return hash(k) & (arraySize - 1);
}
/**
* 获取Key 的hash
*
* @param key
* @return
*/
private int hash(K key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
public void getInfo() {
System.out.println("当前数组长度:" + arraySize);
System.out.println("当前元素个数:" + entryUseSize);
}
}
测试:
public class Test {public static void main(String[] args) {
MyHashMap<Integer, String> myMap = new MyHashMap<>();
for (int i = 0; i < 500; i++) {
myMap.put(i, i + "");
System.out.println(myMap.get(i));
}
//重复添加
for (int i = 0; i < 500; i++) {
myMap.put(i, i + "-覆盖");
System.out.println(myMap.get(i));
}
myMap.getInfo();
}
}
以上是 手写一个HashMap 的全部内容, 来源链接: utcz.com/z/517735.html