docker学习笔记之入门,redis主从配置2理论

全量复制
用于初次复制或其它无法进行部分复制的情况,将主节点中的所有数据都发送给从节点,是一个非常重型的操作,当数据量较大时,会对主从节点和网络造成很大的开销
部分复制
用于处理在主从复制中因网络闪断等原因造成的数据丢失场景,当从节点再次连上主节点后,如果(条件允许),主节点会补发丢失数据给从节点。因为补发的数据远远小于全量数据,可以有效避免全量复制的过高开销,需要注意的是,如果网络中断时间过长,造成主节点没有能够完整地保存中断期间执行的写命令,则无法进行部分复制,仍使用全量复制
复制偏移量
参与复制的主从节点都会维护自身复制偏移量。主节点(master)在处理完写入命令后,会把命令的字节长度做累加记录,统计信息在 info relication 中的master_repl_offset 指标中:
127.0.0.1:6379> info replication
从节点(slave)每秒钟上报自身的复制偏移量给主节点,因此主节点也会保存从节点的复制偏移量,统计指标如下:
从节点在接收到主节点发送的命令后,也会累加记录自身的偏移量。统计信息在 info relication 中的 slave_repl_offset 中
复制积压缓冲区
复制积压缓冲区是保存在主节点上的一个固定长度的队列,默认大小为1MB,当主节点有连接的从节点(slave)时被创建,这时主节点(master)响应写命令时,不但会把命令发送给从节点,还会写入复制积压缓冲区。
在命令传播阶段,主节点除了将写命令发送给从节点,还会发送一份给复制积压缓冲区,作为写命令的备份;除了存储写命令,复制积压缓冲区中还存储了其中的每个字节对应的复制偏移量(offset) 。由于复制积压缓冲区定长且先进先出,所以它保存的是主节点最近执行的写命令;时间较早的写命令会被挤出缓冲区。
如图所示:
1、Redis 内部会发出一个同步命令,刚开始是 Psync 命令,Psync ? -1表示要求 master 主机同步数据
2、主机会向从机发送 runid 和 offset,因为 slave 并没有对应的 offset,所以是全量复制
3、从机 slave 会保存 主机master 的基本信息 save masterInfo
4、主节点收到全量复制的命令后,执行bgsave(异步执行),在后台生成RDB文件(快照)(在教新的版本里可以不生成快照无磁盘化传输),并使用一个缓冲区(称为复制缓冲区)记录从现在开始执行的所有写命令
5、主机send RDB 发送 RDB 文件给从机
6、发送缓冲区数据
7、刷新旧的数据,从节点在载入主节点的数据之前要先将老数据清除
8、加载 RDB 文件将数据库状态更新至主节点执行bgsave时的数据库状态然后再缓冲区数据的加载。
全量复制开销,主要有以下几项。
bgsave 时间
RDB 文件网络传输时间
从节点清空数据的时间
从节点加载 RDB 的时间
部分复制
部分复制是 Redis 2.8 以后出现的,之所以要加入部分复制,是因为全量复制会产生很多问题,比如像上面的时间开销大、无法隔离等问题, Redis 希望能够在master 出现抖动(相当于断开连接)的时候,可以有一些机制将复制的损失降低到最低
1、如果网络抖动(连接断开 connection lost)
2、主机master 还是会写 replbackbuffer(复制缓冲区)
3、从机slave 会继续尝试连接主机
4、从机slave 会把自己当前 runid 和偏移量传输给主机 master,并且执行 pysnc 命令同步
5、如果 master 发现你的偏移量是在缓冲区的范围内,就会返回 continue 命令
6、同步了 offset 的部分数据,所以部分复制的基础就是偏移量 offset。
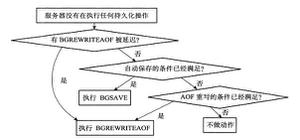
正常情况下redis是如何决定是全量复制还是部分复制
从节点将offset发送给主节点后,主节点根据offset和缓冲区大小决定能否执行部分复制:
如果offset偏移量之后的数据,仍然都在复制积压缓冲区里,则执行部分复制;
如果offset偏移量之后的数据已不在复制积压缓冲区中(数据已被挤出),则执行全量复制。
缓冲区大小调节:
由于缓冲区长度固定且有限,因此可以备份的写命令也有限,当主从节点offset的差距过大超过缓冲区长度时,将无法执行部分复制,只能执行全量复制。反过来说,为了提高网络中断时部分复制执行的概率,可以根据需要增大复制积压缓冲区的大小(通过配置repl-backlog-size)来设置;
例如 如果网络中断的平均时间是60s,而主节点平均每秒产生的写命令(特定协议格式)所占的字节数为100KB,则复制积压缓冲区的平均需求为6MB,保险见,可以设置为12MB,来保证绝大多数断线情况都可以使用部分复制。
服务器运行ID(runid)
每个Redis节点(无论主从),在启动时都会自动生成一个随机ID(每次启动都不一样),由40个随机的十六进制字符组成;runid用来唯一识别一个Redis节点。 通过info server命令,可以查看节点的runid:
主从节点初次复制时,主节点将自己的runid发送给从节点,从节点将这个runid保存起来;当断线重连时,从节点会将这个runid发送给主节点;主节点根据runid判断能否进行部分复制:
如果从节点保存的runid与主节点现在的runid相同,说明主从节点之前同步过,主节点会继续尝试使用部分复制(到底能不能部分复制还要看offset和复制积压缓冲区的情况)
如果从节点保存的runid与主节点现在的runid不同,说明从节点在断线前同步的Redis节点并不是当前的主节点,只能进行全量复制。
主从复制的常用相关配置
从数据库配置
1) slaveof <masterip> <masterport> #slave实例需要配置该项,指向master的(ip, port)。 启动后自动设置主从
2) masterauth <master-password> #主节点密码 如果master实例启用了密码保护,则该配置项需填master的启动密码;若master未启用密码,该配置项需要注释掉
3) slave-serve-stale-data #指定 slave 与 master 连接中断时的动作。默认为yes,表明slave会继续应答来自client的请求,但这些数据可能已经过期(因为连接中断导致无法从 master同步)。若配置为no,则slave除正常应答"INFO"和"SLAVEOF"命令外,其余来自客户端的请求命令均会得到" SYNC with master in progress "的应答,直到该 slave 与master 的连接重建成功或该 slave 被提升为 master 。
4) slave-read-only #指定slave是否只读,默认为yes。若配置为no,这表示slave是可写的,但写的内容在主从同步完成后会被删掉。
5) repl-disable-tcp-nodelay #指定向slave同步数据时,是否禁用 socket 的 NO_DELAY 选项。若配置为yes,则禁用 NO_DELAY ,则TCP协议栈会合并小包统一发送,这样可以减少主从节点间的包数量并节省带宽,但会增加数据同步到slave的时间。若配置为no,表明启用 NO_DELAY ,则TCP协议栈不会延迟小包的发送时机,这样数据同步的延时会减少,但需要更大的带宽。通常情况下,应该配置为no以降低同步延时,但在主从节点间网络负载已经很高的情况下,可以配置为yes。
6) slave-priorit #指定 slave 的优先级。在不只1个 slave 存在的部署环境下,当 master 宕机时, Redis Sentinel 会将priority值最小的slave提升为master。需要注意的是,若该配置项为0,则对应的slave永远不会被 Redis Sentinel 自动提升为 master 。
主从配置参数参考
###########从库###############设置该数据库为其他数据库的从数据库(如果用到哨兵就不建议使用这种)
slaveof <masterip> <masterport>
#主从复制中,设置连接master服务器的密码(前提master启用了认证)
masterauth <master-password>
slave-serve-stale-data yes
# 当从库同主库失去连接或者复制正在进行,从库有两种运行方式:
# 1) 如果slave-serve-stale-data设置为yes(默认设置),从库会继续相应客户端的请求
# 2) 如果slave-serve-stale-data设置为no,除了INFO和SLAVOF命令之外的任何请求都会返回一个错误"SYNC with master in progress"
#当主库发生宕机时候,哨兵会选择优先级最高的一个称为主库,从库优先级配置默认100,数值越小优先级越高
slave-priority 100
#从节点是否只读;默认yes只读,为了保持数据一致性,应保持默认
slave-read-only yes
########主库配置##############
#在slave和master同步后(发送psync/sync),后续的同步是否设置成TCP_NODELAY假如设置成yes,则redis会合并小的TCP包从而节省带宽,但会增加同步延迟(40ms),造成master与slave数据不一致假如设置成no,则redis master会立即发送同步数据,没有延迟
#前者关注性能,后者关注一致性
repl-disable-tcp-nodelay no
#从库会按照一个时间间隔向主库发送PING命令来判断主服务器是否在线,默认是10秒
repl-ping-slave-period 10
#复制积压缓冲区大小设置
repl-backlog-size 1mb
#master没有slave一段时间会释放复制缓冲区的内存,repl-backlog-ttl用来设置该时间长度。单位为秒。
repl-backlog-ttl 3600
#redis提供了可以让master停止写入的方式,如果配置了min-slaves-to-write,健康的slave的个数小于N,mater就禁止写入。master最少得有多少个
健康的slave存活才能执行写命令。这个配置虽然不能保证N个slave都一定能接收到master的写操作,但是能避免没有足够健康的slave的时候,master不
能写入来避免数据丢失。设置为0是关闭该功能。
min-slaves-to-write 3
min-slaves-max-lag 10
docker run --privileged -itd -v /usr/docker/redis/slave2:/usr/src/redis -p 6382:6379 --name redis-slave2 --network=redis-network --ip=192.168.1.4 redis
#--privileged 给容器网络操作的权限
主从复制进阶常见问题解决
1、读写分离
2、数据延迟
3、主从配置不一致
4、规避全量复制
5、规避复制风暴
读写分离
读流量分摊到从节点。这是个非常好的特性,如果一个业务只需要读数据,那么我们只需要连一台 slave 从机读数据。
虽然读写有优势,能够让读这部分分配给各个 slave 从机,如果不够,直接加 slave 机器就好了。但是也会出现以下问题。
复制数据延迟
可能会出现 slave 延迟导致读写不一致等问题,当然你也可以使用监控偏移量 offset ,如果 offset 超出范围就切换到 master 上,逻辑切换,而具体延迟多少,可以通过 info replication 的 offset 指标进行排查。
对于无法容忍大量延迟场景,可以编写外部监控程序监听主从节点的复制偏移量,当延迟较大时触发报警或者通知客户端避免读取延迟过高的从节点同时从节点的 slave-serve-stale-data 参数也与此有关,它控制这种情况下从节点的表现 当从库同主机失去连接或者复制正在进行,从机库有两种运行方式:
1) 如果slave-serve-stale-data设置为yes(默认设置),从库会继续响应客户端的请求。
2) 如果slave-serve-stale-data设置为no,除去INFO和SLAVOF命令之外的任何请求都会返回一个错误”SYNC with master in progress”。
例子:模拟网络延迟
docker run --privileged -itd -v /usr/docker/redis/slave2:/usr/src/redis -p 6382:6379 --name redis-slave2 --network=redis-network --ip=192.168.1.4 redis
--privileged Docker 容器将拥有访问主机所有设备的权限
通过linux下的控流工具,模拟网络延迟,用代码模拟下,因为对于网络的操作属于特殊权限所以需要添加 --privileged 参数
centos:
yum install iproute
alpine:
apk add install iproute2
进入到容器之后配置延迟5s
tc qdisc add dev eth0 root netem delay 5000ms
tc qdisc del dev eth0 root netem delay 5000ms
异步复制导致数据丢失
因为master->slave的复制是异步,所以可能有部分还没来得及复制到slave就宕机了,此时这些部分数据就丢失了。
怎么解决?(请记住只能降低到可控范围,没办法做到100%不丢失)
#最少有多少台从机器才能写入
min-slaves-to-write 1
#从节点最大延迟时间,延迟小于min-slaves-max-lag秒的slave才认为是健康的slave
min-slaves-max-lag 10
要求至少有1个slave,数据复制和同步的延迟不能超过10秒,如果说一旦所有的slave,数据复制和同步的延迟都超过了10秒钟,那么这个时候,master就不会再接收任何请求了
有了min-slaves-max-lag这个配置,就可以确保说,一旦slave复制数据和ack延时太长,就认为可能master宕机后损失的数据太多了,那么就拒绝写请求,这样可以把master宕机时由于部分数据未同步到slave导致的数据丢失降低到可控范围内
如何选择,要不要读写分离?
没有最合适的方案,只有最合适的场景,读写分离需要业务可以容忍一定程度的数据不一致,适合读多写少的业务场景,读写分离,是为了什么,主要是因为要建立一主多从的架构,才能横向任意扩展 slave node 去支撑更大的读吞吐量。
从节点故障问题
对于从节点的故障问题,需要在客户端维护一个可用从节点可用列表,当从节 点故障时,立刻切换到其他从节点或主节点,之后讲解redis Cluster 时候可以解决这个问题
配置不一致
主机和从机不同,经常导致主机和从机的配置不同,并带来问题。
数据丢失: 主机和从机有时候会发生配置不一致的情况,例如 maxmemory 不一致,如果主机配置 maxmemory 为8G,从机 slave 设置为4G,这个时候是可以用的,而且还不会报错。但是如果要做高可用,让从节点变成主节点的时候,就会发现数据已经丢失了,而且无法挽回。
规避全量复制
全量复制指的是当 slave 从机断掉并重启后,runid 产生变化而导致需要在 master 主机里拷贝全部数据。这种拷贝全部数据的过程非常耗资源。全量复制是不可避免的,例如第一次的全量复制是不可避免的,这时我们需要选择小主节点,且 maxmemory 值不要过大,这样就会比较快。同时选择在低峰值的时候做全量复制。
造成全量复制的原因
1. 是主从机的运行 runid 不匹配。解释一下,主节点如果重启, runid 将会发生变化。如果从节点监控到 runid 不是同一个,它就会认为你的节点不安全。当发生故障转移的时候,如果主节点发生故障,那么从机就会变成主节点。
2. 复制缓冲区空间不足,比如默认值1M,可以部分复制。但如果缓存区不够大的话,首先需要网络中断,部分复制就无法满足。其次需要增大复制缓冲区配置(relbacklogsize),对网络的缓冲增强。
怎么解决?
在一些场景下,可能希望对主节点进行重启,例如主节点内存碎片率过高,或者希望调整一些只能在启动时调整的参数。如果使用普通的手段重启主节点,会使得runid发生变化,可能导致不必要的全量复制。为了解决这个问题,Redis提供了debug reload的重启方式:重启后,主节点的runid和offset都不受影响,避免了全量复制。
单机器的复制风暴
1、当一个主机下面挂了很多个 slave 从机的时候,主机 master 挂了,这时 master 主机重启后,因为 runid 发生了变化,所有的 slave 从机都要做一次全量复制。这将引起单节点和单机器的复制风暴,开销会非常大。
解决:
可以采用树状结构降低多个从节点对主节点的消耗
从节点采用树状树非常有用,网络开销交给位于中间层的从节点,而不必消耗顶层的主节点。但是这种树状结构也带来了运维的复杂性,增加了手动和自动处理故障转移的难度
2、由于 Redis 的单线程架构,通常单台机器会部署多个 Redis 实例。当一台机器(machine)上同时部署多个主节点 (master) 时,如果每个 master 主机只有一台 slave 从机,那么当机器宕机以后,会产生大量全量复制。这种情况是非常危险的情况,带宽马上会被占用,会导致不可用。
解决:
1、应该把主节点尽量分散在多台机器上,避免在单台机器上部署过多的主节点。
2、当主节点所在机器故障后提供故障转移机制,避免机器恢复后进行密集的全量复制
以上是 docker学习笔记之入门,redis主从配置2理论 的全部内容, 来源链接: utcz.com/z/517691.html