使用javaScriptEngine实现动态爬虫脚本

开发背景:Selenium是一个用于Web应用程序测试的工具,可以直接像真正的用户在操作浏览器。支持的浏览器包括IE,Mozilla Firefox,Safari,Google Chrome,Opera等。我们的项目中有很多基于selenium开发的小采集任务(一些网站使用js渲染,网站监控、网站定时截图等,必须使用selenium才能实现),而在ide开发工具中,每个网站都要写不同的采集规则,在开发工具中不断重启selenium,非常费时间,开发效率极低。为了提高效率,使用Java自带的ScriptEngine来实现Java动态执行代码方案,这个方案也方便内部非java开发人员也能写采集脚本。
目前在java 1.8中是使用Nashorn引擎来动态的JavaScript代码,可以使用javascript语法来调用整个java自带库和第三方库。
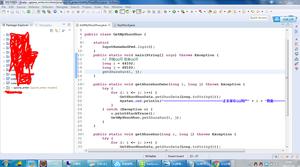
为方便脚本的编写,基于使用swing开发个简单的脚本编辑工具,GUI代码不介绍,执行动态脚本的实现代码
public void initRunOnceBtn(Container contentPane, int gridx, int gridy){runButton = new JButton("运行一次");
runButton.addActionListener(new ActionListener(){
public void actionPerformed(ActionEvent e){
String code = codeText.getText();
runButton.setEnabled(false);
new Thread(){
public void run(){
runcode(code);
runButton.setEnabled(true);
}
}.start();
}
});
contentPane.add(runButton, new GB(gridx,gridy,1,1).setInsets(10, 0,10,10));
}
public void runcode(String code){
ScriptEngineManager manager = new ScriptEngineManager();
ScriptEngine engine = manager.getEngineByName("JavaScript");
try{
engine.put("log", log);
engine.put("driver", driver);
engine.put("tool", com.test.WebCrawler.this);
// 执行这个脚本
engine.eval(code);
}
catch(Exception ex){
log.error("脚本执行出错======", ex);
}
}
测试1、使用文章标题在百度搜索中查看我博客文章被转载数据。
脚本代码
浏览器运行效果
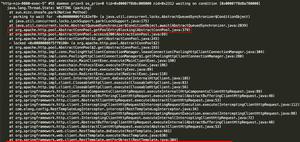
控制台输出:
测试2:采集天猫骤划算商品信息
脚本代码:
浏览器运行效果
控制台输出:
以上是 使用javaScriptEngine实现动态爬虫脚本 的全部内容, 来源链接: utcz.com/z/517354.html