SpringCloud升级之路Hoxton3.负载均衡从ribbon替换成springcloudloadbalancer

本系列示例与胶水代码地址: https://github.com/HashZhang/spring-cloud-scaffold
负载均衡Ribbon替换成Spring Cloud Load Balancer
Spring Cloud Load Balancer并不是一个独立的项目,而是spring-cloud-commons其中的一个模块。 项目中用了Eureka以及相关的 starter,想完全剔除Ribbon的相关依赖基本是不可能的,Spring 社区的人也是看到了这一点,通过配置去关闭Ribbon启用Spring-Cloud-LoadBalancer。
spring.cloud.loadbalancer.ribbon.enabled=false关闭ribbon之后,Spring Cloud LoadBalancer就会加载成为默认的负载均衡器。
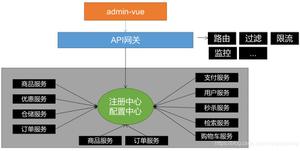
Spring Cloud LoadBalancer 结构如下所示:
其中:
- 全局只有一个
BlockingLoadBalancerClient,负责执行所有的负载均衡请求。 BlockingLoadBalancerClient从LoadBalancerClientFactory里面加载对应微服务的负载均衡配置。- 每个微服务下有独自的
LoadBalancer,LoadBalancer里面包含负载均衡的算法,例如RoundRobin.根据算法,从ServiceInstanceListSupplier返回的实例列表中选择一个实例返回。
1. 实现zone隔离
要想实现zone隔离,应该从ServiceInstanceListSupplier里面做手脚。默认的实现里面有关于zone隔离的ServiceInstanceListSupplier -> org.springframework.cloud.loadbalancer.core.ZonePreferenceServiceInstanceListSupplier:
private List<ServiceInstance> filteredByZone(List<ServiceInstance> serviceInstances) { if (zone == null) {
zone = zoneConfig.getZone();
}
//如果zone不为null,并且该zone下有存活实例,则返回这个实例列表
//否则,返回所有的实例
if (zone != null) {
List<ServiceInstance> filteredInstances = new ArrayList<>();
for (ServiceInstance serviceInstance : serviceInstances) {
String instanceZone = getZone(serviceInstance);
if (zone.equalsIgnoreCase(instanceZone)) {
filteredInstances.add(serviceInstance);
}
}
if (filteredInstances.size() > 0) {
return filteredInstances;
}
}
// If the zone is not set or there are no zone-specific instances available,
// we return all instances retrieved for given service id.
return serviceInstances;
}
这里对于没指定zone或者该zone下没有存活实例的情况下,会返回所有查到的实例,不区分zone。这个不符合我们的要求,所以我们修改并实现下我们自己的com.github.hashjang.hoxton.service.consumer.config.SameZoneOnlyServiceInstanceListSupplier:
private List<ServiceInstance> filteredByZone(List<ServiceInstance> serviceInstances) { if (zone == null) {
zone = zoneConfig.getZone();
}
if (zone != null) {
List<ServiceInstance> filteredInstances = new ArrayList<>();
for (ServiceInstance serviceInstance : serviceInstances) {
String instanceZone = getZone(serviceInstance);
if (zone.equalsIgnoreCase(instanceZone)) {
filteredInstances.add(serviceInstance);
}
}
if (filteredInstances.size() > 0) {
return filteredInstances;
}
}
//如果没找到就返回空列表,绝不返回其他集群的实例
return List.of();
}
然后我们来看一下默认的 Spring Cloud LoadBalancer 提供的 LoadBalancer ,它是带缓存的:
org.springframework.cloud.loadbalancer.annotation.LoadBalancerClientConfiguration
@Bean@ConditionalOnBean(ReactiveDiscoveryClient.class)
@ConditionalOnMissingBean
public ServiceInstanceListSupplier discoveryClientServiceInstanceListSupplier(
ReactiveDiscoveryClient discoveryClient, Environment env,
ApplicationContext context) {
DiscoveryClientServiceInstanceListSupplier delegate = new DiscoveryClientServiceInstanceListSupplier(
discoveryClient, env);
ObjectProvider<LoadBalancerCacheManager> cacheManagerProvider = context
.getBeanProvider(LoadBalancerCacheManager.class);
if (cacheManagerProvider.getIfAvailable() != null) {
return new CachingServiceInstanceListSupplier(delegate,
cacheManagerProvider.getIfAvailable());
}
return delegate;
}
DiscoveryClientServiceInstanceListSupplier每次从Eureka上面拉取实例列表,CachingServiceInstanceListSupplier提供了缓存,这样不必每次从Eureka上面拉取。可以看出CachingServiceInstanceListSupplier是一种代理模式的实现,和SameZoneOnlyServiceInstanceListSupplier的模式是一样的。
我们来组装我们的ServiceInstanceListSupplier,由于我们是同步的环境,只用实现同步的ServiceInstanceListSupplier就行了。
public class CommonLoadBalancerConfig { /**
* 同步环境下的ServiceInstanceListSupplier
* SameZoneOnlyServiceInstanceListSupplier限制仅返回同一个zone下的实例(注意)
* CachingServiceInstanceListSupplier启用缓存,不每次访问eureka请求实例列表
*
* @param discoveryClient
* @param env
* @param zoneConfig
* @param context
* @return
*/
@Bean
@Order(Integer.MIN_VALUE)
public ServiceInstanceListSupplier discoveryClientServiceInstanceListSupplier(
DiscoveryClient discoveryClient, Environment env,
LoadBalancerZoneConfig zoneConfig,
ApplicationContext context) {
ServiceInstanceListSupplier delegate = new SameZoneOnlyServiceInstanceListSupplier(
new DiscoveryClientServiceInstanceListSupplier(discoveryClient, env),
zoneConfig
);
ObjectProvider<LoadBalancerCacheManager> cacheManagerProvider = context
.getBeanProvider(LoadBalancerCacheManager.class);
if (cacheManagerProvider.getIfAvailable() != null) {
return new CachingServiceInstanceListSupplier(
delegate,
cacheManagerProvider.getIfAvailable()
);
}
return delegate;
}
}
2. 实现下一次重试的时候,如果存在其他实例,则一定会重试与本次不同的其他实例
默认的RoundRobinLoadBalancer,其中的轮询position,是一个Atomic类型的,在某个微服务的调用请求下,所有线程,所有请求共用(调用其他的每个微服务会创建一个RoundRobinLoadBalancer)。在使用的时候,会有这样的一个问题:
- 假设某个微服务有两个实例,实例 A 和实例 B
- 某次请求 X 发往实例 A,position = position + 1
- 在请求没有返回时,请求 Y 到达,发往实例 B,position = position + 1
- 请求 A 失败,重试,重试的实例还是实例 A
这样在重试的情况下,某个请求的重试可能会发送到上一次的实例进行重试,这不是我们想要的。针对这个,我提了个Issue:Enhance RoundRoubinLoadBalancer position。我修改的思路是,我们需要一个单次请求隔离的position,这个position对于实例个数取余得出请求要发往的实例。那么如何进行请求隔离呢?
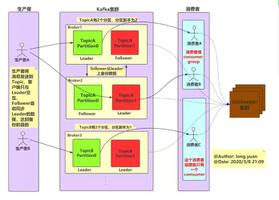
首先想到的是线程隔离,但是这个是不行的。Spring Cloud LoadBalancer 底层运用了 reactor 框架,导致实际承载选择实例的线程,不是业务线程,而是 reactor 里面的线程池,如图所示:
所以,不能用ThreadLocal的方式实现position。
由于我们用到了sleuth,一般请求的context会传递其中的traceId,我们根据这个traceId区分不同的请求,实现我们的 LoadBalancer:
RoundRobinBaseOnTraceIdLoadBalancer
//这个超时时间,需要设置的比你的请求的 connectTimeout + readTimeout 长private final LoadingCache<Long, AtomicInteger> positionCache = Caffeine.newBuilder().expireAfterWrite(3, TimeUnit.SECONDS).build(k -> new AtomicInteger(ThreadLocalRandom.current().nextInt(0, 1000)));
private Response<ServiceInstance> getInstanceResponse(List<ServiceInstance> serviceInstances) {
if (serviceInstances.isEmpty()) {
log.warn("No servers available for service: " + this.serviceId);
return new EmptyResponse();
}
//如果没有 traceId,就生成一个新的,但是最好检查下为啥会没有
//是不是 MQ 消费这种没有主动生成 traceId 的情况,最好主动生成下。
Span currentSpan = tracer.currentSpan();
if (currentSpan == null) {
currentSpan = tracer.newTrace();
}
long l = currentSpan.context().traceId();
int seed = positionCache.get(l).getAndIncrement();
return new DefaultResponse(serviceInstances.get(seed % serviceInstances.size()));
}
3. 替换默认的负载均衡相关 Bean 实现
我们要用上面的两个类替换默认的实现,先编写一个配置类:
public class CommonLoadBalancerConfig { private volatile boolean isValid = false;
/**
* 同步环境下的ServiceInstanceListSupplier
* SameZoneOnlyServiceInstanceListSupplier限制仅返回同一个zone下的实例(注意)
* CachingServiceInstanceListSupplier启用缓存,不每次访问eureka请求实例列表
*
* @param discoveryClient
* @param env
* @param zoneConfig
* @param context
* @return
*/
@Bean
@Order(Integer.MIN_VALUE)
public ServiceInstanceListSupplier discoveryClientServiceInstanceListSupplier(
DiscoveryClient discoveryClient, Environment env,
LoadBalancerZoneConfig zoneConfig,
ApplicationContext context) {
isValid = true;
ServiceInstanceListSupplier delegate = new SameZoneOnlyServiceInstanceListSupplier(
new DiscoveryClientServiceInstanceListSupplier(discoveryClient, env),
zoneConfig
);
ObjectProvider<LoadBalancerCacheManager> cacheManagerProvider = context
.getBeanProvider(LoadBalancerCacheManager.class);
if (cacheManagerProvider.getIfAvailable() != null) {
return new CachingServiceInstanceListSupplier(
delegate,
cacheManagerProvider.getIfAvailable()
);
}
return delegate;
}
@Bean
public ReactorLoadBalancer<ServiceInstance> reactorServiceInstanceLoadBalancer(
Environment environment,
ServiceInstanceListSupplier serviceInstanceListSupplier,
Tracer tracer) {
if (!isValid) {
throw new IllegalStateException("should use the ServiceInstanceListSupplier in this configuration, please check config");
}
String name = environment.getProperty(LoadBalancerClientFactory.PROPERTY_NAME);
return new RoundRobinBaseOnTraceIdLoadBalancer(
name,
serviceInstanceListSupplier,
tracer
);
}
}
然后,指定默认的负载均衡配置采取这个配置, 通过注解:
@LoadBalancerClients(defaultConfiguration = {CommonLoadBalancerConfig.class})以上是 SpringCloud升级之路Hoxton3.负载均衡从ribbon替换成springcloudloadbalancer 的全部内容, 来源链接: utcz.com/z/517121.html