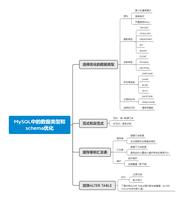
Pulsar2.5.0之Schema进阶

Pulsar 2.5.0 之 Schema 进阶
官网原文标题《Pulsar Schema》翻译时间:2020-02-15
官网原文地址:http://pulsar.apache.org/docs/en/schema-understand/
译者:了解schema 类型与应用场景、 schema版本管理、schema工作流程。
schema 基本概念
SchemaInfo
SchemaInfo 是定义schema一种数据结构.
SchemaInfo是基于每个主题存储和执行的,不能存储在命名空间或租户级别.
SchemaInfo包含以下字段:
name
Schema 名称(发现和topic名称相同)
type
Schema 类型,类型常用的JSON格式,其他详见官方文档
schema
Schema 数据是一个由 8 位无符号字节和模式类型特定组成的序列,这一属性可能是内部使用
schemaDefinition
具体业务数据结构
properties
存放用户自定义属性
示例:schemaInfo是一个JSON字符串
{"name":"test-string-schema",
"type":"STRING",
"schema":"",
"properties":{}
}
支持多种模式类型,主要分为两类
- 原始类型
- 复杂类型
Pulsar 支持的原始类型如下
BOOLEAN
A binary value
INT8
A 8-bit signed integer
INT16
A 16-bit signed integer
INT32
A 32-bit signed integer
INT64
A 64-bit signed integer
FLOAT
A single precision (32-bit) IEEE 754 floating-point number
DOUBLE
A double-precision (64-bit) IEEE 754 floating-point number
BYTES
A sequence of 8-bit unsigned bytes
STRING
A Unicode character sequence
TIMESTAMP (DATE, TIME)
A logic type represents a specific instant in time with millisecond precision. It stores the number of milliseconds since January 1, 1970, 00:00:00 GMT as an INT64 value
对于原始类型,Pulsar不在SchemaInfo中存储任何模式数据。SchemaInfo中的类型用于确定如何序列化和反序列化数据。
一些基本模式实现可以使用属性来存储特定于实现的可调设置。例如,字符串架构可以使用属性存储编码字符集以序列化和反序列化字符串。
Pulsar schema types 和语言特定原始类型之间的转换如下
BOOLEAN
boolean
bool
bool
INT8
byte
int8
INT16
short
int16
INT32
int
int32
INT64
long
int64
FLOAT
float
float
float32
DOUBLE
double
float
float64
BYTES
byte[], ByteBuffer, ByteBuf
bytes
[]byte
STRING
string
str
string
TIMESTAMP
java.sql.Timestamp
TIME
java.sql.Time
DATE
java.util.Date
此示例演示如何使用string schema。
使用string schema创建生产者并发送消息
Producer producer = client.newProducer(Schema.STRING).create();producer.newMessage().value("Hello Pulsar!").send();
使用string schema 创建消费者并接收消息
Consumer consumer = client.newConsumer(Schema.STRING).create();consumer.receive();
复杂类型
目前支持的复杂类型如下
keyvalue
表示键/值对的复杂类型
struct
表示 AVRO, JSON, and Protobuf.类型
key-value (键值对)
对于 SchemaInfo 中 keyvalue schema ,Pulsar将键模式的SchemaInfo和值模式的SchemaInfo存储在一起。
Pulsar提供了两种方法来编码消息中的键/值对
INLINE
键/值对将在消息有效负载中一起编码
SEPARATED键/将在消息键中编码,值将在消息有效负载中编码
用户可以在构造keyvalue schema时选择编码类型
示例
这个例子展示了如何构造一个键/值模式,然后使用它来生成和使用消息。
使用INLINE编码类型来构造 key/value schema
Schema<KeyValue<Integer,String>> kvSchema =Schema.KeyValue(Schema.INT32,
Schema.STRING,
KeyValueEncodingType.INLINE
);
使用SEPARATED编码类型来构造 key/value schema
Schema<KeyValue<Integer,String>> kvSchema =Schema.KeyValue(Schema.INT32,
Schema.STRING,
KeyValueEncodingType.SEPARATED
);
使用 key/value schema 发送消息
Schema<KeyValue<Integer,String>> kvSchema =Schema.KeyValue(Schema.INT32,
Schema.STRING,
KeyValueEncodingType.SEPARATED
);
Producer<KeyValue<Integer,String>> producer
= client.newProducer(kvSchema)
.topic(TOPIC)
.create();
finalint key =100;
finalString value ="value-100";
// send the key/value message
producer.newMessage()
.value(newKeyValue<>(key, value))
.send();
使用 key/value schema 接收消息
Schema<KeyValue<Integer,String>> kvSchema =Schema.KeyValue(Schema.INT32,
Schema.STRING,
KeyValueEncodingType.SEPARATED
);
Consumer<KeyValue<Integer,String>> consumer
= client.newConsumer(kvSchema)
...
.topic(TOPIC)
.subscriptionName(SubscriptionName).subscribe();
// receive key/value pair
Message<KeyValue<Integer,String>> msg = consumer.receive();
KeyValue<Integer,String> kv = msg.getValue();
struct
Pulsar使用Avro规范来定义的struct模式
- 使用相同的工具管理 schema 定义
- 使用不同的序列化/反序列化方法处理数据
struct schema 可以使用两种方法:
staticgeneric
static
预定义结构模式,它可以是Java中的POJO、Go中的struct或Avro或Protobuf工具生成的类。
示例
创建一个User类来定义发送到topic的消息
publicclassUser{String name;
int age;
}
使用 struct schema 创建一个生产者来发送消息
Producer producer = client.newProducer(Schema.AVRO(User.class)).create();
producer.newMessage().value(
User.builder().userName("pulsar-user").userId(1L)
.build()).send();
使用 struct schema 创建一个消费者来接收消息
Consumer consumer = client.newConsumer(Schema.AVRO(User.class)).create();
User user = consumer.receive();
generic
某些应用你无法预先定义数据结构,你可以用如下方法来定义 schema 和访问数据。可以使用GenericSchemaBuilder定义 struct schema ,使用GenericRecordBuilder生成泛型结构,并将消息使用到GenericRecord中。
使用 RecordSchemaBuilder 构建一个 schema
RecordSchemaBuilder recordSchemaBuilder =SchemaBuilder.record("schemaName");
recordSchemaBuilder.field("intField").type(SchemaType.INT32);
SchemaInfo schemaInfo
= recordSchemaBuilder.build(SchemaType.AVRO);
Producer producer
=client.newProducer(Schema.generic(schemaInfo))
.create();
使用 RecordBuilder 构建数据记录
producer.newMessage().value(schema.newRecordBuilder().set("intField",32)
.build()).send();
AUTO schema
如果您事先不知道Pulsar主题的模式类型,可以使用AUTO schema来生成
AUTO_PRODUCE
This is useful for transferring data from a producer to a Pulsar topic that has a schema.
AUTO_CONSUME
This is useful for transferring data from a Pulsar topic that has a schema to a consumer.
AUTO_PRODUCE
AUTO_PRODUCE schema 帮助生产者验证生产者发送的字节是否与主题的 schema 兼容
需求描述
- 你需要处理一个来自 Kafka topic k 消息
- 你有一个 Pulsar topic P, 但是你不清楚他的 schema type.
- 你的应用需要从kafka topic K 读取消息,然后 写入到Pulsar topic P
在这种情况下,可以使用AUTO_PRODUCE验证K生成的字节是否可以发送到P
Produce pulsarProducer= client.newProducer(Schema.AUTO_PRODUCE())
…
.create();
byte[] kafkaMessageBytes = … ;
pulsarProducer.produce(kafkaMessageBytes);
…
AUTO_CONSUME
AUTO_CONSUME schema 帮助Pulsar主题验证Pulsar主题发送的字节是否与使用者兼容,即Pulsar主题使用从代理端检索的SchemaInfo将消息反序列化为语言特定的对象。AUTO_CONSUME 仅支持AVRO和JSON模式。它将消息反序列化为GenericRecord.
需求描述
- 你有一个 Pulsar topic P.
- 你的消费端 (例如 MySQL) 需要从 topic P 读取消息
- 你的应用读取来自 P 的消息,然后将读取的消息写入到 MySQL.
在这种情况下,可以使用AUTO-CONSUME验证P生成的字节是否可以发送到MySQL
Consumer pulsarConsumer = client.newConsumer(Schema.AUTO_CONSUME())
…
.subscribe();
Message msg = consumer.receive();
GenericRecord record = msg.getValue();
…
schema version
chemaInfo存储在主题上都有一个版本。schema 版本管理主题中发生的schema更改。
使用给定SchemaInfo生成的消息被标记为schema版本,因此当Pulsar客户端使用消息时,Pulsar客户端可以使用schema版本检索相应的SchemaInfo,然后使用SchemaInfo反序列化数据。
schema的版本是连续的。schema存储发生在处理关联主题的代理中,以便可以进行版本分配。
一旦将一个版本分配/获取到/用于一个schema,该生产者生成的所有后续消息都将被标记为相应的版本。
我们通过一个例子,来讲解schema版本如何工作。 假设使用以下代码创建Pulsar Java 客户端,尝试连接到Pulsar,并开始发送消息:
PulsarClient client =PulsarClient.builder()
.serviceUrl("pulsar://localhost:6650")
.build();
Producer producer
= client.newProducer(JSONSchema.of(SensorReading.class))
.topic("sensor-data")
.sendTimeout(3,TimeUnit.SECONDS)
.create();
下表列出了尝试连接时可能出现的场景, 以及每种场景下发生了什么:
该Topic不存在schema
使用给定的schema创建了producer。 Schema传输到broker并被存储 (因为没有现成的schema与SensorReading schema "兼容")。 任何使用同样schema/topic的consumer可以消费sensor-datatopic中的消息。
Schema已经存在;producer使用已经被保存过的schema进行连接
Schema被传输到Pulsar broker。 Broker确认此schema是兼容的。 Broker尝试在BookKeeper存储schema,但是发现它已经存在了,所以用它来标记生产的消息。
Schema已经存在;producer使用兼容的新schema进行连接。
Producer传输schema到broker。broker发现这个schema是兼容的,随后保存这个新schema作为当前版本(使用新的版本号)。
schema如何工作
Pulsar schema在主题级别应用和实施(schema不能在命名空间或租户级别应用)。
生产者和消费者将schema上传到代理,因此Pulsar schema在生产者和消费者方面都起作用。
生产者
schema-producer.png
应用程序使用 schema 实例来构造生产者实例。
schema实例定义了使用生产者实例生成的数据的schema。
以AVRO为例,Pulsar从POJO类中提取schema定义并构造SchemaInfo,生产者在连接时需要将其传递给broker。
生产者使用从传入的schema实例中提取的SchemaInfo连接到broker。
broker在schema存储中查找schema,以检查它是否已经是注册的schema。
如果是,broker将跳过schema验证,因为它是已知的schema,并将schema版本返回给生产者。
如果否,则broker验证是否可以在此命名空间中自动创建schema:
如果isAllowAutoUpdateSchema设置为true,则可以创建schema,并且broker根据为主题定义的schema兼容性检查策略验证schema。
如果isAllowAutoUpdateSchema设置为false,则无法创建schema,并且将拒绝生产者连接到broker。
消费者
schema-consumer.png
应用程序使用 schema 实例来构造消费者实例。
schema 实例定义使用者用于解码从代理接收的消息的 schema 。
消费者使用从传入的schema实例中提取的SchemaInfo连接到broker。
broker确定主题是否有其中一个(模式/数据/本地消费者和本地生产者)。
如果一个主题没有全部(模式/数据/本地使用者和本地生产者):
- 如果isAllowAutoUpdateSchema设置为true,则使用者注册一个架构并将其连接到broker。
- 如果isAllowAutoUpdateSchema设置为false,则拒绝使用者连接到broker。
如果主题有其中一个(模式/数据/本地使用者和本地生产者),则执行模式兼容性检查。
- 如果schema通过兼容性检查,则使用者连接到broker。
- 如果schema未通过兼容性检查,则拒绝使用者连接到broker。
消费者从代理接收消息。
如果消费者使用的schema支持schema版本控制(例如,AVRO架构),则消费者获取消息中标记的版本的SchemaInfo,并使用传入schema和消息中标记的schema来解码消息
以上是 Pulsar2.5.0之Schema进阶 的全部内容, 来源链接: utcz.com/z/516854.html