RedisAOF重写阻塞问题分析

问题背景
某个业务线使用Redis集群保存用户session数据,数据量大约在4千万-5千万,每天发生3-4次AOF重写,每次时间持续30-40秒,AOF重写期间出现Redis主进程阻塞,应用端响应超时的问题。
环境:Redis 2.8,一主一从。
什么是AOF重写
AOF重写是AOF持久化的一个机制,用来压缩AOF文件,通过fork一个子进程,重新写一个新的AOF文件,该次重写不是读取旧的AOF文件进行复制,而是读取内存中的Redis数据库,重写一份AOF文件,有点类似于RDB的快照方式。
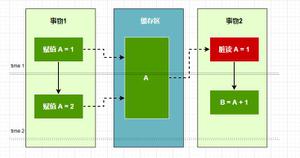
在子进程进行AOF重启期间,Redis主进程执行的命令会被保存在AOF重写缓冲区里面,这个缓冲区在服务器创建子进程之后开始使用,当Redis执行完一个写命令之后,它会同时将这个写命令发送给 AOF缓冲区和AOF重写缓冲区。如下图:
阻塞原因
当子进程完成AOF重写工作之后,它会向父进程发送一个信号,父进程在接收到该信号之后,会调用一个信号处理函数,并执行以下工作:
- 将
AOF重写缓冲区中的所有内容写入到新的AOF文件中,保证新AOF文件保存的数据库状态和服务器当前状态一致。 - 对新的
AOF文件进行改名,原子地覆盖现有AOF文件,完成新旧文件的替换 - 继续处理客户端请求命令。
在整个AOF后台重写过程中,只有信号处理函数执行时会对 Redis主进程造成阻塞,在其他时候,AOF后台重写都不会阻塞主进程,如下图所示:
解决方案
这是当时的Redis配置:
127.0.0.1:6379> config get *append*1) "no-appendfsync-on-rewrite"
2) "no"
3) "appendonly"
4) "yes"
5) "appendfsync"
6) "everysec"
从配置看,原因理论上就很清楚了:我们的这个Redis实例使用AOF进行持久化(appendonly),appendfsync策略采用的是everysec刷盘。但是AOF随着时间推移,文件会越来越大,因此,Redis还有一个rewrite策略,实现AOF文件的减肥,但是结果是幂等的。我们no-appendfsync-on-rewrite的策略是 no,这就会导致在进行rewrite操作时,appendfsync会被阻塞。如果当前AOF文件很大,那么相应的rewrite时间会变长,appendfsync被阻塞的时间也会更长。
这不是什么新问题,很多开启AOF的业务场景都会遇到这个问题。解决的办法有这么几个:
- 将
no-appendfsync-on-rewrite设置为yes. 这样可以避免与appendfsync争用文件句柄,但是在rewrite期间的AOF有丢失的风险。 - 给当前
Redis实例添加slave节点,当前节点设置为master, 然后master节点关闭AOF,slave节点开启AOF。这样的方式的风险是如果master挂掉,尚没有同步到slave的数据会丢失。
我们采取了折中的方式:
- 在
master节点设置将no-appendfsync-on-rewrite设置为yes(表示在日志重写时,不进行命令追加操作,而只是将命令放在重写缓冲区里,避免与命令的追加造成磁盘IO上的冲突),同时auto-aof-rewrite-percentage参数设置为0关闭主动重写 - 为了防止
AOF文件越来越大,我们在缓存云平台上配置在凌晨低峰期定时手动执行bgrewriteaof命令完成每日一次的AOF重写 - 在重写时为了避免硬盘空间不足或者
IO使用率高影响重写功能,我们还添加了硬盘空间报警和IO使用率报警保障重写的正常进行
那么如果rewrite的时候对新的写操作不进行fsync,那么新的AOF文件里面是否会丢失这个写操作呢?
答案是不会的,Redis会将新的写操作放在重写缓存区中,等待rewrite操作完成的时候,将新操作直接追加到新的AOF中。
参考资料
- Redis AOF 持久化详解
- Redis的一些坑
- 一次非典型性 Redis 阻塞总结
- Redis持久化之大数据服务暂停问题
以上是 RedisAOF重写阻塞问题分析 的全部内容, 来源链接: utcz.com/z/516800.html