MySQL数据库备份与恢复

目录
- 前言
- 1.备份数据的意义
- 2.使用mysqldump进行数据库备份" title="数据库备份">数据库备份
- 2.1.不带参数备份单个数据库
- 2.2.加-B参数备份
- 2.3.使用gzip压缩备份数据库
- 2.4.mysqldump命令工作原理
- 2.5.备份多个库
- 2.5.1.备份多个库
- 2.5.2.如何做分库备份
- 2.6.备份单个表
- 2.7.备份多个表
- 2.8.备份数据库表结构(不包含数据)
- 2.9.只备份数据库表的数据(不包含表结构)
- 2.10.同时将数据和表结构分离导出
- 2.11.刷新binlog文件参数(-F)
- 2.11.1.binlog是什么
- 2.11.2.binlog对于备份的作用
- 2.11.3.为什么要刷新binlog
- 2.11.4.如何开启binlog功能
- 2.11.5.使用-F刷新binlog日志
- 2.12.记录binlog位置的特殊参数(--master-data)
- 2.13.锁定所有表备份(-x参数)
- 2.14.innodb表特有的备份参数(--single-transaction)
- 3.mysqldump重要关键参数说明
- 4.不同引擎的mysqldump备份命令
- 4.1.innodb引擎的备份命令
- 4.2.适合多引擎混合的备份命令
- 5.利用SQL语句方式对表进行导入导出
- 5.1.导出表
- 5.1.1.导出表SQL语句语法
- 5.1.2.导出表
- 5.2.导入表
- 5.2.1.导入表命令语法
- 5.2.2.导入表
- 5.1.导出表
前言
1.备份数据的意义
运维工作的核心简单概括起来就是两件事:第一个是保护公司的数据,第二个是让网站能够7*24小时提供服务。
虽然这两件事情都很重要,但是相比较而言,丢失一部分数据和让网站7*24小时提供服务,哪个更重要呢?
对于绝大多数企业来讲,失去数据就相当于失去商机,失去产品,失去客户,甚至会造成公司倒闭,那么,在所有的数据中,最核心的数据又是哪些呢?这恐怕要属数据库中的数据了。既然数据库中的数据地位这么高,那么数据库备份与恢复的重要性就不言而喻了。
2.使用mysqldump进行数据库备份
MySQL数据库自带了一个很优秀的备份命令,即mysqldump。
2.1.不带参数备份单个数据库
mysqldump oldboy >/opt/mysql_bak.sql2.2.加-B参数备份
mysqldump -B oldboy >/opt/mysql_bak_B.sql #B参数的作用是增加创建数据库和连接数据库的语句,可同时备份多个库。2.3.使用gzip压缩备份数据库
mysqldump -B oldboy|gzip>/opt/mysql_bak_B.gz2.4.mysqldump命令工作原理
利用mysqldump命令备份数据的过程,实际上就是把数据(包括库表)从MySQL库里以SQL语句的形式直接输出或者生成备份文件的过程,这种备份成SQL语句的方式称为逻辑备份。
使用mysqldump命令可以把数据库中的数据导出来,并通过SQL语句的形式存储。这种备份方式称为逻辑备份,效率不是很高。在当下的生产场景中,多用于数据量不是很大的备份情况,例如30GB以内的数据。若在数据库数据很大的时候采用此备份方法,则所用的时候就会很长,恢复的时间也会很长,因此,当数据大于30GB后,建议选择其他的诸如Xtrabackup的物理方式进行备份和恢复。
2.5.备份多个库
2.5.1.备份多个库
mysqldump -B oldboy oldboy_utf8 mysql|gzip>/opt/all.sql.gz2.5.2.如何做分库备份
分库备份实际上就是每次只执行一个mysqldump备份命令语句备份一个库,如果数据库里有多个库,就执行多条相同的语句来备份各个库。
mysqldump -uroot -p"oldboy123" -B oldboy |gzip >/tmp/oldboy.sql.gzmysql -e "show databases;" |egrep -v "_schema|atabase" |sed -r "s#^(.*)#mysqldump -B 1 |gzip >/tmp/1.sql.gz#g" |bash #bash执行这些备份命令,就是一次分开备份多个库了
2.6.备份单个表
当不加-B参数备份数据库时,例如“mysqldump oldboy test”,mysqldump命令默认就会把oldboy当作库,把test当作表,如果后面还有多个字符串,例如“mysqldump oldboy test test1“,那么除了oldboy为库之外,其他的test、test1都是oldboy库的表。
mysqldump oldboy test>/tmp/oldboy_test,sql2.7.备份多个表
分表备份的缺点:数据文件多,很碎,一旦需要全部恢复又很麻烦。
1、做一个完整备份,再做一个分库分表备份。
2、虽然文件多、碎,但可以利用脚本批量操作多个SQL文件。
mysqldump mysql user db>/tmp/mysql.sqlegrep -v "#|*|--|^$" /tmp/mysql.sql
mysqldump oldboy test > /tmp/oldboy_test.sql
2.8.备份数据库表结构(不包含数据)
利用mysqldump的-d参数可以只备份表的结构,即建表的语句。
mysqldump -d oldboy >/opt/oldboy.sql2.9.只备份数据库表的数据(不包含表结构)
利用-t参数备份数据库表的数据(SQL语句形式)。
mysqldump -t oldboy >/opt/oldboy1.sql2.10.同时将数据和表结构分离导出
利用-T参数可以实现将数据和表结构同时分离备份。
vi /etc/my.cnfsecure_file_priv="" #在[mysqld]模块下增加
/etc/init.d/mysqld restart
mysqldump oldboy test --compact -T /tmp/
1、-d参数的作用是只备份库表结构(SQL语句形式)。
2、-t参数的作用是只备份表内的数据(SQL语句形式)。
3、-T将库表和数据分离成不同的文件,数据是纯文本,表结构是SQL语句。
2.11.刷新binlog文件参数(-F)
2.11.1.binlog是什么
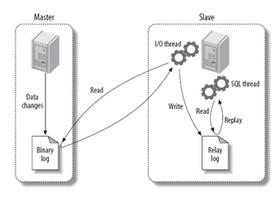
binlog是一个二进制格式的文件,用于记录用户对数据库更新的SQL语句信息,例如更改数据库库表和更改表内容的SQL语句都会记录到binlog里,但是对库表等内容的查询则不会记录到日志中。
2.11.2.binlog对于备份的作用
当有数据写入到数据库时,还会同时把更新的SQL语句写入到对应的binlog文件里。
使用mysqldump备份时,一般是对某一时刻的数据进行全备,例如,0点进行数据库备份。
假设是每天0点对数据库进行备份,那么在两次备份之间就有24小时的数据没有备份,在这期间如果数据库发生故障,使用mysqldump全量恢复也只能恢复到当日0点,但是有了binlog文件,就可以将两次完整备份间隔之间的数据还原,因为binlog文件里的数据就是写入数据库的数据,使用binlog文件恢复数据,我们称之为二进制增量数据恢复。
2.11.3.为什么要刷新binlog
刷新(切割)binlog日志的目的就是确定全备和增量备(binlog文件)的临界点,当全备完成后,全备时刻以前的binlog文件就无用了(全备里已有这部分数据了),但是全备以后到下一次全备之前的数据就是十分重要的,这部分数据就存在于binlog文件里,因此在进行全备时需要找到全备之后和binlog增量之间的临界点,使得恢复时,需要的binlog文件数据一条不多(不能和全备的内容重合),一条不少(全备后的所有数据都要有)。
2.11.4.如何开启binlog功能
binlog文件生效需要一个参数:log_bin,编辑配置文件增加log_bin参数即可。
vi /etc/my.cnf添加log_bin=mysql-bin到mysqld模块下
2.11.5.使用-F刷新binlog日志
使用-F将会从备份后的时刻起重新记录binlog日志文件,将来增量恢复从新的binlog日志文件开始即可。
例如,早晨10点丢失数据需要恢复数据。
1、将0点时刻备份的全备数据还原到数据库,这个时候数据就恢复到了当日0点。
2、0点到10点丢失的数据,就要从全备后当天的所有binlog里恢复,而使用-F切割日志,就是找到0点这个时刻全备和binlog接缝的起始binlog文件。
mysqldump -F -B oldboy|gzip >/opt/bak_$(date +%F).sql.gz2.12.记录binlog位置的特殊参数(--master-data)
mysqldump里提供了一个参数,使得管理员不用刷新binlog,也可以在备份的文件对应的SQL语句里会添加change mastar语句及binlog文件及位置点信息。
当“--master-data=1”时,备份结果为可执行的“change master...”语句;当“--master-data=2”时,备份结果为注释的“--change master...” 语句,“--”在SQL语句里为注释的意思。“--master-data“ 参数除了确定增量恢复和全备之间的临界点之外,进行主从复制时的作用更大。
mysqldump --master-data=1 oldboy --compact|head -1mysqldump --master-data=2 oldboy --compact|head -1
2.13.锁定所有表备份(-x参数)
使用mysqldump命令备份期间,数据库依然是可以写入数据的,此时,备份的数据就不是某一个时刻的一致性备份了,因此也会在恢复时造成困扰。例如备份时使用-x锁表备份就会取得0点时刻的完整备份,即在0点时刻停止所有写入操作,然后导出备份数据,备份完毕,放开写入。
如果不锁表进行备份,就会无法得到某一个时刻的完整备份,由于是一边备份数据一边写入数据,因此最后备份的数据很可能就是一个时间段的数据,而非某一个时刻的一致性全备。
2.14.innodb表特有的备份参数(--single-transaction)
当使用mysqldump的“--single-transaction”对innodb表进行备份时,会开启一个事务,并将整个备份过程放到一个事务里,以确保执行本次dump会话时,不会看到其他连接会话已经提交了的数据,即备份开始时刻的数据是什么样,备份出来就是什么样子。这也相当于是锁表之后备份的数据,但是这个参数是允许在备份期间写入数据的,而不是在使用“-x”参数锁表之后,备份期间无法写入任何数据。
3.mysqldump重要关键参数说明
mysqldump重要参数 参数说明
-B,--databases
会在备份的数据中增加建库(create)及“use库”的语句,可以直接接多个库名,同时备份多个库
-A,--all-databases
备份所有的数据库
-d,--no-data
只备份库表结构(SQL语句形式),没有行数据
-t,--no-create-info
只备份表内行数据(SQL语句形式),没有表结构
-T,--tab=name
将库表和数据分离成不同的文件,行数据是纯文本,表结构是SQL语句
-F,--flush-logs
刷新binlog日志,生产新binlog文件,将来增量恢复从这个新binlog文件开始,当备份多个库时,每个库都会刷新一次binlog,如果想只刷新一次binlog,可加“--lock-all-tables”或“--master-data”参数
--master-data={1|2}
在备份结果中增加binlog日志文件名及对应的binlog位置点(即change master...语句)。值为1时是不注释状态,值为2时是注释状态,该参数执行时会打开“--lock-all-tables”功能,除非有“--single-transaction”存在,使用该参数时会关闭“--lock-tables”功能
-x,--lock-all-tables
备份时对所有数据库的表执行全局读锁,期间同时禁止“--single-transaction”和“--lock-tables”参数功能
-l,--lock-tables
锁定所有的表为只读
--single-transaction
在备份innodb引擎数据表时,通常会启用该选项来获取一个一致性的数据快照备份,它的工作原理是设定本次备份会话的隔离级别为repeatable read,并将整个备份放在一个事务里,以确保执行本次dump会话时,不会看到其他连接会话已经提交了的数据,即备份开始时刻的数据是什么样,备份出来就是什么样子!也就相当于锁表备份数据,但是这个参数是允许在备份期间写入数据的,而不是-x锁表后的备份期间无法写入任何数据,启用该参数会关闭“--lock-tables”
-R,--routines
备份存储过程和函数数据
--triggers
备份触发器数据
--compact
只显示很少的有用输出,适合学习和测试环境调试用
4.不同引擎的mysqldump备份命令
4.1.innodb引擎的备份命令
“--single-transaction”是innodb引擎专有的备份参数,优势就是备份期间数据依然可以执行写操作。
mysqldump -A -B --master-data=2 --single-transaction |gzip >/opt/all.sql.gz4.2.适合多引擎混合的备份命令
使用“--master-data”会自动开启-x锁表参数功能,在备份期间会影响数据写入。
mysqldump -A -B --master-data=2 |gzip >/opt/all_$(date +%F).sql.gz5.利用SQL语句方式对表进行导入导出
5.1.导出表
5.1.1.导出表SQL语句语法
export options 说明
character set utf8
导出时设置字符为utf8,默认和库字符集一致
fields terminated by "-"
导出时设置不同的域分隔符为“-”,默认是tab
field enclosed by "";
导出时设置对字段内容的引用符号,这里设置为“”,默认为空
lines starting by "="
导出时每行行首设置等号,默认为空
lines termibated by"="
导出时每行行尾的结束符设置为“=”,默认是回车符
5.1.2.导出表
use oldboyselect * from test;
select * from test into outfile "/tmp/oldboy_test1.txt"; #将test表里的数据导出为纯文本
system cat /tmp/oldboy_test.txt;
select * from test into outfile "/tmp/oldboy_test2.txt" character set utf8; #导出时设置字符集
select * from test into outfile "/tmp/oldboy_test3.txt" fields terminated by "-"; #指定分隔符导出
select * from test into outfile "/tmp/oldboy_test4.txt" fields enclosed by ""; #导出时设置对字段内容进行引用
5.2.导入表
5.2.1.导入表命令语法
import options 说明
character set utf8
导入时设置字符集为utf8,默认和库字符集一致
fields terminated by "-"
不同域之间的分隔符导入,这里是“-”,默认是tab
fields enclosed by "";
根据字段内容的引用符号导入,这里是引号,默认为空
lines starting by "="
导入时在每行行首设置等号,默认为空
lines terminated by "="
导入时将每行行尾的结束符设置为“=”,默认是回车符
ignore number lines
不导入文件的前N行
5.2.2.导入表
delete from test;system cat /tmp/oldboy_test1.txt;
load data infile "/tmp/oldboy_test1.txt" into table test; #默认方式将数据导入数据库
select * from test;
system cat /tmp/oldboy_test3.txt;
load data infile "/tmp/oldboy_test3.txt" into table test fields terminated by "-"; #指定分隔符方式导入数据库
select * from test;
system cat /tmp/oldboy_test4.txt
load data infile "/tmp/oldboy_test4.txt" into table test fields enclosed by ""; #双引号引用数据导入数据库
以上是 MySQL数据库备份与恢复 的全部内容, 来源链接: utcz.com/z/516255.html