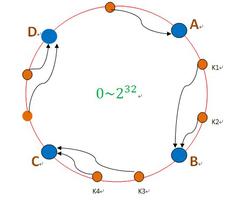
hash冲突的方法

image.png
问题:这样就会导致落在区间内的关键字Key要进行多次探测才能找到合适的位置,并且还会继续增大这个连续区间,使探测时间变得更长,这样的现象被称为“一次聚集(primary clustering)”,也就是说越后面的数,如果发生hash冲突,探测的时间越长,因为前面的数都已经将很多可用区域占了。
例如对数组(5,1,3,2,4)做mod 3处理
hashcode
2
1
0
2
1
未发生冲突前
对应数字
3
1
5
直到现在2插入,发现2位置上上是5,已经有值,所以去找下一个发现没有了,紧接着直接扩容和线性探测
对应数字
3
1
5
2
后面4插入时,先去看1,发现有1,看2发现有5,看3发现有2,扩容插入4
对应数字
3
1
5
2
4
可以看到非常容易产生一次聚类
2.平发探测法
以上为例:
当2发现发生冲突时直接每次增长i^2 倍,即2(hash值)+(-) i^2
对应数字
3
1
5
2
当4发生冲突,先是寻找2(1+1^2)再寻找5(1+ 2^2)
对应数字
3
1
5
2
4
3.伪随机探测再散列:
发生冲突:如果用伪随机探测再散列处理冲突,且伪随机数序列为:2,5,9,……..,则下一个哈希地址为H1=(3 + 2)% 11 = 5,仍然冲突,再找下一个哈希地址为H2=(3 + 5)% 11 = 8,此时不再冲突,将69填入8号单元
4.再哈希法
这种方法是同时构造多个不同的哈希函数:
Hi=RH1(key) i=1,2,…,k
当哈希地址Hi=RH1(key)发生冲突时,再计算Hi=RH2(key)……,直到冲突不再产生。这种方法不易产生聚集,但增加了计算时间。
2.链地址法(拉链法:HashMap等采用的就是这个方法):
image.png
在我hashcode的后面建立一个链表,每一个链表表示现在hashcode为当前的所有元素
但是这个方法很容易就造成链表的长度过大,在访问时候可能会时间很长,
所有适时的要增大数组的长度。来换取链表的长度
例如上面是mod3,我们可以mod5
0
5
1
1
2
2
3
3
4
4
什么时候扩容?
“我们可以定义这样一个变量 α = 所有元素个数/数组的大小,我们叫它装载因子吧,它代表着我们的Hash表(也就是数组)的装满程度,在这里也代表链表的平均长度
例如上面的 数组{5,1,3,2,4} 当取mod3时候就是 α = 5%3,这时候我们扩容
即使Hash函数设计的合理,基本上每次存放元素的时候就会冲突,所以鉴于两者之间我觉得 0.6 - 0.9 之间是一个不错的选择,不妨选0.75吧”
以上是 hash冲突的方法 的全部内容, 来源链接: utcz.com/z/516044.html