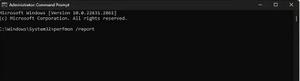
垃圾收集器

serial 收集器
单线程,尽兴垃圾回收时需要Stop The World。Client模式下默认收集器
ParNew
serial多线程版本。除了多线程,其他跟serial基本一样。也需要Stop The World,多线程下比serial好。Server模式下新生代收集器的首选,除了效率,还因为除了serial,只有他能与CMS配合使用
Parallel Scavenge 收集器
并行多线程收集器,追求高吞吐。与其他收集器追求用户线程低停顿不同,高吞吐能更快的完成计算任务。适合后台的计算,而不是用户交
老生代收集器
serial old
单线程老生代收集器。serial的老生代版本。标记清理算法
Parallel Old收集器
多线程并行标记整理收集器。注重高吞吐,对CPU敏感。与新生代Parallel Scavenge组合。
CMS收集器
追求低停顿标记-清理,适合现在B/S的服务端上:
- 过程:
- 初始标记:标记直接与GC ROOT链接的对象,需要 Stop The World
- 并发标记:引用链(GC ROOTS Tracing),耗时长
- 重新标记:修改并发标记期间变动的标记,需要Stop The World
- 并发清理:CMS concurrent sweep
- 缺点:
- CPU敏感:并发期间占用CPU资源,降低吞吐量
- 无清理浮动垃圾:清理阶段,用户线程还在运行会产生垃圾(浮动垃圾)。因此需要预留一定内存空间再进行回收。
- 标记清理产生内存碎片
G1:
唯一一个手机新生代和老生代,标记-整理收集器。面向服务端应用的垃圾收集器
- 并行与并发:并行充分使用多核心CPU;并使用并发方式用户线程仍可以运行
小结
协作关系
serial 与 serial old:
相关概念
并行和并发
并行(Parallel):指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态。
并发(Concurrent):指用户线程与垃圾收集线程同时执行(但不一定是并行的,可能会交替执行),用户程序在继续运行。而垃圾收集程序运行在另一个CPU上。
吞吐量(Throughput)
吞吐量就是CPU用于运行用户代码的时间与CPU总消耗时间的比值,即
吞吐量 = 运行用户代码时间 /(运行用户代码时间 + 垃圾收集时间)。
假设虚拟机总共运行了100分钟,其中垃圾收集花掉1分钟,那吞吐量就是99%
参考:https://crowhawk.github.io/2017/08/15/jvm_3/
以上是 垃圾收集器 的全部内容, 来源链接: utcz.com/z/515380.html