RabbitMQ消息中间件技术精讲笔记

RabbitMQ消息中间件技术精讲笔记
错别字有点多, 改了一部分. 剩下的不影响阅读,实在没精力改了...
业界主流消息中间件介绍
MQ衡量指标
- 服务性能
- 数据存储
- 集群架构
主流MQ介绍
- ActiveMQ
Apache出品, 早期非常流行,完全支持JMS规范的消息中间件,API丰富,提供多种集群架构.
但是现在已经落伍了,并发小的话可以用一用.
集群模式: 利用zookeeper实现主从管理, 但是从库不能提供服务; network模式: 其实就是两组主从,利用网关进行连接配置,实现分布式集群.
- Kafka
是Linkedln开源的分布式消息系统,目前属于Apache顶级项目
主要是基于Pull的模式来处理消息消费,追求高吞吐量, 性能强劲.
高性能主要是利用操作系统底层的page cache空中接力,完全没有磁盘和内存的同步情况.
0.8开始支持复制,不支持事务,对消息的重复,丢失,错误没有严格要求.
集群模式: 利用zookeeper实现集群管理,支持数据复制.
PS: 我之前用过kafka,各种版本及其混乱.不懂的话别乱用.要用,先学一遍版本管理.
- RocketMQ(有钱用这个)
是阿里的开源消息中间件,目前也是Apache的顶级项目,用Java开发.
思路是起源于kafka,但是它对消息的可靠性传输及事务性做了优化
非常适合大规模的分布式应用系统,而且可以不使用zookeeper,自己实现了一套nameserver来做集群之间的管理.
具有kafka的高性能,同时又具有可靠性,分布式事务,水平扩展,上亿级别的消息堆积,主从之间自由切换等等,基本上我们要的优点它都能满足.
虽然他很厉害,不过他的商业版收费,很多功能不对外提供.有钱真好
- RabbitMQ(没钱用这个)
使用Erlang开发基于AMQP协议
主要特征是面向消息,队列,路由,包括点对点的发布和订阅,可靠性,安全支持镜像队列.
AMQP协议更多用在对数据的一致性,稳定性,可靠性要求很高的场景,对性能和吞吐量的要求还在其次.
在金融行业,对数据的稳定性和可靠性要求高的地方用这个最好
性能比不上kafka,但是也不是很差,尤其是比上面的ActiveMQ高出很多,而且我们可以自己对他做性能优化
他的集群可以构建好多的组,一些异地双活架构,包括每个节点的存储方式可以选择内存和磁盘非常的灵活
节点之间使用镜像度列的方式进行同步,这种方式能够保证数据100%不丢失.
最完美的集群方案(基于RabbitMQ):
非常完善,高可用,高性能,高稳定性,具有各种数据恢复手段,即使磁盘损坏也没事.
入门RabbitMQ核心概念
RabbitMQ是用Erlang语言编写的基于AMQP协议的一个开源的消息代理和队列服务器,用来通过普通协议在完全不同的应用之间共享数据,比如在前面用PHP投递到RabbitMQ中,后面使用GO来监听数据做处理.
为什么用RabbitMQ
- 高性能
- 开源
- 高稳定性
- 高可靠性,可靠性投递,返回模式等等
- 与spring的AMQP,go的AMQP,PHP的AMQP完美的整合,API丰富
- 集群模式丰富,表达式配置,HA模式,镜像队列模型等
- 保证数据不丢失的情况下做到高可靠,高可用
RabbitMQ的高性能实现方式
使用Erlang语言开发,该语言有着和原生socket一样的延迟,且该语言最初就是用在交换机领域的架构模式
使得RabbitMQ在broker之间进行数据交换的性能非常的优秀
AMQP高级消息队列协议
AMQP全称: Advanced Message Queuing Protocol
AMQP翻译: 高级消息队列协议
AMQP定义: 具有现代特征的二进制协议,是一个提供统一消息服务的应用层标准高级消息度列协议,是一个应用层协议的开放标准,为面向消息的中间件专门设计的.有点类似Java的JMS,其实就是一个上层的规范,然后基于该规范来开发各种消息中间件.
- server: 接受客户端的连接又叫做broker,,实现AMQP实体服务
- connection: 连接,应用程序与broker的网络连接
- channel: 网络通道,几乎所有的操作都在channel中进行,channel是进行消息读写的通道,客户端可用创建多个channel,每个channel代表一个会话
- message: 消息,服务器和应用程序之间传送的数据,由properties和body组成.properties可用对消息进行修饰,比如消息的优先级,延迟等高级特性; body则就是消息体的内容
- virtual host: 虚拟地址,用于逻辑隔离,最上层的消息路由,一个virtual host里面可以有若干个Exchange和queue,同一个virtual host里面不能有相同名称的exchange和queue
- exchange: 交换机,接收消息根据路由键转发消息到绑定的队列
- binding: exchange和queue之间的虚拟连接,binding中可以包含routing key
- routing key: 一个路由规则,虚拟机可用他来确定如何路由一个特定的消息
- queue: 消息队列,也叫message queue,用来保存消息并将他们转发给消费者
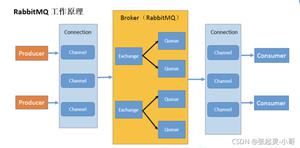
RabbitMQ整体架构模型
如图, 生产者只需要关注投递到哪个exchange中个,而消费者只需要关注指定的队列即可
exchange和queue没有耦合的情况,他们之间有一个routing key来做路由绑定
比如绿色的X上面写的exchanges route and filter,意思就是可以通过exchange对消息进行路由和过滤,将消息路由到指定的队列上
RabbitMQ消息流转
为什么消息流转图中的message queue只有左边的一个里面有message,其他两个没有?
因为他们上面的exchange中会有路由策略也就是routing key,来指定把消息发送到哪个queue中.
发消息的时候必须要指定两个关键的属性:
- 消息要发到哪个exchange上.
- routing key,而后通过exchange和queue建立一个绑定的关系,通过routing key把消息路由到指定的queue中
安装和使用
我在另一篇日志<rabbitmq快速入门>里写的更详细,这里不赘述了
命令行和控制台
我在另一篇日志<rabbitmq快速入门>里写的更详细,这里不赘述了
RabbitMQ消息生产与消费快速入门
- ConnectionFactory: 获取连接工厂
- connection: 获取一个连接
- channel: 数据通信信道,可发送和接收消息
- queue: 具体的消息存储队列
- producer&consumer:生产者和消费者
源码是java的,我这里用PHP来实现,原理都是一样的.
php使用AMQP协议有两种方式:
官方扩展
pecl install amqpcomposer包
composer install php-amqplib
之前用的时候,amqp扩展更加稳定,而php-amqplib老不抛异常之类的.
所以我这里就是用的amqp扩展来做的
- PHP代码
注意:
durable, auto_delete,passive 等参数前后要一致,也就是交换机类型和队列类型要保持一致,否则是要出问题的
尤其是在夸语言使用中,特别容易忽略这一点,导致这类出错:
file:/Users/liuhao/Desktop/tmp/rabbitmq_consumer.php line:30 msg:Server channel error: 406, message: PRECONDITION_FAILED - inequivalent arg "durable" for exchange "exchange-1" in vhost "/": received "true" but current is "false"%生产者代码
<!--?php$message = "测试内容-这里是测试内容";
//接受确认
$ackCallback = function ($delivery_tag, $multiple) {
var_dump("Message confirm");
};
//未接受确认
$nackCallback = function ($delivery_tag, $multiple, $requeue) use ($message) {
// nack处理: 重新发送消息该批次消息,或者记录日志
var_dump("Message unconfirm");
};
try {
//创建连接
$conn = new AMQPConnection();
$conn--->setHost("localhost");
$conn->setPort("5672");
$conn->setLogin("root");
$conn->setPassword("root");
$conn->setVhost("/");
//发送连接
$conn->connect();
//连接通道
$channel = new AMQPChannel($conn);
$channel->confirmSelect(); //设置消息投递确认
//因为我们是如果exchange不能存在就自动创建,所有这里不会生效,如果没有设置自动生效,而且如果要启用这个的话,需要在投递时设置flag为mandatory
$channel->setReturnCallback(function ($reply_text, $exchange, $routing_key, $properties, $body) {
var_dump("发送失败");
});
//连接交换机
$exchange = new AMQPExchange($channel);
$exchange->setName("exchange-1"); //设置交换机名称
$exchange->setType(AMQP_EX_TYPE_DIRECT);//设置direct类型
$exchange->setFlags(AMQP_DURABLE);//持久的交换和队列将在代理重新启动后幸存下来,并保留所有数据。
$exchange->declareExchange();//声明一个交换机(如果不存在就会自动创建)
//发送消息到交换机
for ($i = 0; $i < 10; $i++) {
//注意routing key要前后一致
$exchange->publish($message.$i, "routing-1");
}
//接收confirm消息确认
$channel->setConfirmCallback($ackCallback, $nackCallback);//消息投递确认后的回调
// $channel->waitForConfirm(2); //设置消息投递接收的等待时间,如果不设置就是不等待的意思,大概率拿不到确认
} catch (AMQPException $e) {
dd($e);
}
//关闭连接
$channel->close();
$conn->disconnect();
//打印日志
function dd($e)
{
$log = "file:".$e->getFile();
$log .= " line:".$e->getLine();
$log .= " msg:".$e->getMessage();
echo $log;
exit;
}
消费端代码
<!--?phptry {
//连接broker
$conn = new AMQPConnection();
$conn--->setHost("localhost");
$conn->setPort("5672");
$conn->setLogin("root");
$conn->setPassword("root");
$conn->setVhost("/");
//连接
$conn->connect();
//连接通道
$channel = new AMQPChannel($conn);
$channel->qos(0, 1); //限制,每次只获取一条,防止队列拥挤时把程序打爆,前面的0代表字节数,这里设置0标识忽略该参数
//连接交换机
$exchange = new AMQPExchange($channel);
$exchange->setName("exchange-1");//设置交换机名称
/**
* /AMQP_EX_TYPE_DIRECT:直连交换机
* AMQP_EX_TYPE_FANOUT:扇形交换机
* AMQP_EX_TYPE_HEADERS:头交换机
* AMQP_EX_TYPE_TOPIC:主题交换机
*/
$exchange->setType(AMQP_EX_TYPE_DIRECT);//设置交换机类型
// $exchange->setFlags(AMQP_DURABLE); //持久的交换和队列将在代理重新启动后幸存下来,并保留所有数据。
// $exchange->setFlags(AMQP_PASSIVE); //被动交换是队列不会被重新声明,但是如果交换或队列不存在,则代理将抛出错误。
$exchange->declareExchange();//声明交换机
//创建一个消息队列,如果不设置参数就会生成随机队列,通过一系列的getXX()方法可以获取到随机生成的队列名称属性之类的
$queue = new AMQPQueue($channel);
$queue->setName("queue-1");//设置队列名称
$queue->setFlags(AMQP_DURABLE);//持久的交换和队列将在代理重新启动后幸存下来,并保留所有数据。
// $queue->setFlags(AMQP_PASSIVE);//被动交换是队列不会被重新声明,但是如果交换或队列不存在,则代理将抛出错误。
// $queue->setFlags(AMQP_EXCLUSIVE);//此标志仅对队列有效,指示只有一个客户端可以侦听和使用此队列。注意:独占队列将始终在客户端断开连接时自动删除。
// $queue->setFlags(AMQP_AUTODELETE);//设置客户端断开连接后,将自动删除该队列
$queue->declareQueue();//声明消息队列
$queue->bind($exchange->getName(), "routing-1");//为交换机和queue绑定routing key ,但是要注意routing key要前后一致
//设置消费者的回调,会自动阻塞, 默认手动确认消息
$queue->consume("receiveMessage");//手动确认消息已接收
//$queue->consume("receive", AMQP_AUTOACK);//自动确认消息已接收,拿到消息就会自动通知RabbitMQ删除该消息
} catch (Exception $e) {
dd($e);
}
$channel->close();
$conn->disconnect();
//接收消息的回调函数
function receiveMessage($envelope, $queue)
{
//获取消息内容
echo $envelope->getBody().PHP_EOL;
//手动确信消息已接收,RabbitMQ接收到确认后会自动删除该消息,如果上面没有设置自动确认,这里接收数据后不手动确认消息的话会在获取数据后僵死
$queue->ack($envelope->getDeliveryTag());
}
//打印日志
function dd($e)
{
$log = "file:".$e->getFile();
$log .= " line:".$e->getLine();
$log .= " msg:".$e->getMessage();
echo $log;
exit;
}
RabbitMQ交换机详解
exchange: 接收消息,并根据路由键转发消息到所绑定的队列
上图:
蓝色框: 标识生产者,发送消息通过exchange,通过routingKey路由到指定的queue.
绿色框: 标识消费者,只监听指定的队列
黄色框: 标识routingKey和绑定的关系,exchange和queue要有一个绑定,我们的消息到大exchange后如何分发到queue,这个规则就是通过routingKey来做的.
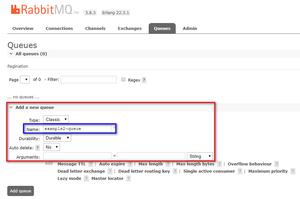
交换机属性
- Name: 交换机名称
- type: 交换机类型,direct,topic,fanout,headers(fanout转发性能最快)
- Durability: 是否需要持久化,true为持久化
- auto delete: 当最后一个绑定在交换机上的队列被删除后,自动删除该交换机
- Internal: 当前exchange是否用于RabbitMQ内部使用,默认为false(一般不考虑,通过erlang扩展插件时才用到)
- Arguments: 扩展参数,用于扩展AMQP协议自定义化时使用
direct exchange
所有被发送到该交换机的消息都会被转发到routing key中指定的queue中
注意: 该模式可以使用RabbitMQ自带的exchange: default,即在使用时不指定exchange就会使用默认的exchange类型
所以不需要将exchange进行任何binding操作,但是发送消息时routing key的名字必须完全匹配queue的名字才能被接收,否则消息将被配抛弃
Topic exchange
所有发送到该交换机的消息都将被转发到所有他关注的routingKEy所指定的topic的queue中
即: 交换机将routingKey和某topic进行模糊匹配,此时队列需要绑定一个topic
注意:模糊匹配可以使用通配符,这里的匹配指的是对routingKey进行匹配
"#" 匹配一个或多个词,每个词之间的区分可以用-/.等等,比如"nihao.tahao.haha"这就是三个词
RabbitMQ队列,绑定,虚拟主机,消息
Binding-绑定
其实就是exchange与exchange和queue之间的连接关系, 但是要注意如果exchange和exchange绑定的话调用节点会很长
queue-消息队列
消息队列,实际存储消息数据,下面是属性:
- Durability: 是否持久化,durable:持久化; transient:不持久话; 不持久化的队列,一旦没有数据,该队列会被自动删除
- auto delete: 当最后一个监听客户端断开连接后,该队列会被自动删除
message-消息
服务器和应用之间传送的消息
本质上就是一段数据,有properties和payload(body)组成
常用属性:
- Delivery mode: 送达模式,可以设置持久化和非持久化
- Headers(自定义属性)
- content_type: 编码类型
- contetn_encoding: 字符集
- Priority: 消息的优先级
- Correlation_id: 可以当做消息唯一ID
- Reply_to: 做重回队列时,比如处理失败,可以将消息重回到指定的队列中
- Expiration: 消息的堆积时间,比如设置10秒,消息只能在度列中存活10秒,十秒内没有被消费就会消失
- Message_id: 消息的ID
- Timestamp: 时间戳
- type: user_id:app_id:cluster_id:等自定义属性,可以直接来客制化来做,在PHP中可以通过new AMQPBasicProperties([各种参数]);来做.
Virtual host-虚拟主机
虚拟地址,用于逻辑隔离使用,最上层的消息路由
一个virtual host里面可以有若干个exchange和queue
同一个virtual host里面不能有相同的exchange或queue
深入RabbitMQ高级特性
- 消息如何100%投递成功
- 幂等性概念
- 海量数据,如何避免消息的重复消费
- Confirm确认消息,return返回消息
- 自定义消费者
- 消息的ack和重回队列
- 消息的限流
- TTL消息
- 死信队列
保证可靠性投递
- 保证数据成功发送
- 保证MQ节点成功接收
- 发送端收到MQ节点的应答
- 完善消息补偿机制(因为应答之类的可能会因为网络问题而失效)
常见解决方案
- 消息落库,对消息状态进行打标,即在生产消息之前,先将数据存储在数据库中,消费消息后对数据库状态进行修改
- 消息的延迟投递,做二次确认,回调检查
第一种方式:
高并发下并不合适,因为多次入库对性能来说就是噩梦!
但是我们千万不要觉得消息落库看起来很奇怪,本来我们推消息之前就要自己存一个订单记录之类的.现在还有再次落库给消费端打标用,性能岂不是下降和很多.
没错这样的话性能会下降, 但是需要想一下,如果我们在高并发中定然是不能使用事务的,那这种方式是不是完美的解决了事务的问题呢.而且比较简单,对于并发比较大但是又没那么大,人力有限的团推,这简直就是最佳方案.
不过这种方式的性能确实不是最佳的选择
如上图中:
生产者在发送消息之前,本来就需要在bzDB中插入一个订单记录的业务记录, 此时还要多保存一个MSGDB的数据的打标数据,用以消费端打标用
消费者拿到数据以后,修改MSGDB中该条数据的状态
同时分布式的定时任务,会定期的对两个数据库做数据对比,以完善补偿机制
而且在step7中,入库时也会有一个retry count作为最大尝试次数,防止入库失败.这时候一般是不会入库失败的,即使出了问题一般也是业务问题,比如投递的消息不符合要求之类的,那这时候只能人工干预了.
第二种方式:
延迟投递,二次确认,回调检查, 这种方式主要是为了减少DB的操作,可以大力提高性能.
注意下面都是server的服务化,可不是一个简单的接口之类的东西:
蓝色upstream server就是生产端
红色downstream server就是消费端
灰色callback server就是回调服务
具体执行流程
异步数据, 一定要等到业务处理完,比如业务订单入库后再去发送消息.任何时候都绝对不能先发消息后入库,切记这是常识;
- step1 生产业务消息,也就是我们要正常处理的消息.将消息投递到指定的队列给消费端消费用
- Step2 生产延迟消息投递检查将检查消息投递到另一个队列,可能要设置延迟时间,比如几秒钟后投递该消息
- Step3 消费端监听消费,
- Step4 消费端处理完毕之后会发送一个confirm确认的消息,该消息也要入另一个队列,注意这个confirm并不是一个普通的act,而是生成一个消息入到另外一个队列投递出去
- Step5 callback服务监听消费端投递的消息,收到消息后对该消息做持久化的存储到MSGDB中,表示真正的处理成功了.
- Step6 callback服务同时监听Step2中投递的检查消息,将收到的消息去DB中核查该数据是否被消费端正常处理.
- 如果callback接收到检查消息后发现DB中没有该数据,或者说发现数据不对,此时去调用upstream server中的RPC服务,告诉我ste1,让step1查询BIZDB库的该条数据,重新发送该业务消息,给消费端去处理.
保证幂等性概念
幂等性案例
同一条数据不论执行多少次,结果都是相同的.
比如跟新一条库存的SQL
Update t_reps set count= count-1,version=version+1此时如果有并发的话,count可能会小于0.为了不让count小于0所以我们要加一个条件来做限制
Update t_reps set count= count-1,version=version+1 where version=1逻辑说明:
- 首先select出来当前商品的version
- 然后在需改数据时将该version作为一个where条件
- 同时在update中将version的值+1
- 此时后面如果有人以他查出来的的version作为where条件进行修改时就会失败,以保证幂等性
消费端幂等性
消费端在消费数据时,因为重复投递或者网络闪断的原因可能会导致重复消费.所以必须要做幂等性
幂等性方案:
唯一ID+指纹机机制
- 唯一ID+指纹机机制,利用数据库主键去重.为什么要用指纹码,因为有的情况下业务可能允许单个用户提交多次,这个指纹码可以是,比如银行账单,交易流水,时间戳什么的, 根据具体业务来.
select count(1) from t_order where id=唯一ID+指纹码- 好处: 简单
- 坏处:高并发下有数据库写入瓶颈
- 高并发解决方案: 跟进ID分库分表进行路由算法
利用Redis的原子性来实现
使用Redis幂等性需要考虑的问题
- 是否要落库,如果落库关键解决的问题是,数据库和缓存如何做到幂等性
- 如果不落库,那么都存在缓存中,如何进行定时的同步策略
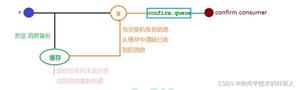
生产者confirm消息确认
消息投递确认机制
- 消息的确认,是指生产者投递消息后,如果broker收到消息,则会返回给生产者一个应答
- 生产者进行接收应答,用来确认这条数据是否正常的发送到了broker.该方式作为可靠性投递的一个核心保证.
如上图所示,confirm是AMQP协议中自有的功能,我们不需要通过业务再次实现,只需要调用该方法询问而后传入回调函数接口
- 实现方式:
- 在channel中开启确认模式: confirmSelect();即可
- 在channel中添加监听:addConfirmLIstener();(php中不叫这个名字,主要用setConfirmCallback()和waitForConfirm());监听成功和失败的返回结果,然后我们可以根据结果来做消息重发或者记录日志之类的操作
生产者return消息机制
return listen用于处理一些不可路由的消息,或者说是一些路由失败的消息
我们的消息生产者,通过指定一个exchange和routingKey,把消息送达到某一个队列中去,然后我们的消费者监听队列进行消费
但是在某些情况下,如果我们在发送消息的时候,当前的exchange不存在或者指定的路由Key路由不到,这时候需要我们监听这中不可达的消息,就需要用到return消息机制
return机制的关键配置: mandatory:需要在投递消息时设置(PHP中为publis()),如果为true则监听器会接收到路由不可达的信息,然后进行后续的处理,如果为false,那么broker会自动删除该消息
如上图,将消息投递到指定的exchange,但是这时候broker总没有改exchange,或者说找不到指定的队列,此时就会通过return 消息机制来返回信息.
消费端限流
为啥要限流? 比如在RabbitMQ中堆积了上百万调数据没有被处理,这时候我们打开一个消费者
瞬间巨量的消息全部推送过来,但是我们的客户端无法同时处理这么多的消息,导致服务器过载很可能导致服务器崩溃
还有一种情况,比如生产端的生产能力一般都会比消费者强,而且我们不可能在生产端去做限制.因为我们做MQ的一个很重要的目的也是为了削峰平谷,只能通过消费端限流同时增加消费者的方式来做
此时RabbitMQ提供了qos(服务质量保证)功能,即在非自动确认消息(不是autoact)的前提下,如果一定数目的消息(通过consume或channel设置qos的值)未被确认前,不进行消费新的消息.
qos这个设置,在多数语言中(java,php,golang)名字都一样,如果使用IDE的话只需要在channel中追踪一下代码就能看到了
一般都是,qos(size,count),size:代表每次获取多少字节,一般都写0,不限制.count:每次获取多少条的消息,一般根据情况来,大多数情况都写1即可.而且size这块RabbitMQ还没有实现这个功能....更加要写0了
消费端ACK与重回队列
消费端的手工ACT和NACT
消费端进行消费时,如果由于业务异常我们可以捕捉异常然后在日志中记录,最后进行补偿, 比如: 每次在处理同一条数据的时候都调用NACK,如果连续调用了2.3次之后还在NACT,这时候我们就可以直接ACT,然后将该消息记录在错误日志中
如果由于服务器宕机等问题,那我们就需要手工进行ACT保证消费端消费成功
消费端的重回队列
消费端重回队列时为了应对没有处理成功的的消息,把消息重新回递给broker;
一般在实际应用中,都会关闭重回队列,也就是设置为false;一般不用考虑重回队列这个问题,默认都是不会重回的.只要做好手动ACT即可
TTL队列/消息
TTL 是time to live的缩写,也就是生存时间
RabbitMQ 支持消息的过期时间,在发送消息时可以指定
RabbitMQ 支持队列的过期时间,从消息入列开始算起,只要超过了队列的超时时间配置,那么消息就会被自动清除(PHP中在new AMQPBasicProperties()时设置$expiration参数即可.)
死信队列
死信队列: DLX,Dead-Letter-Exchange
利用DLX,当消息在一个队列中变成死信(dead message)之后,它被重新publish到另一个exchange,这个exchange就是DLX.
消息变成死信的情况
- 消息被拒绝,并且requeue=false(不需要重回队列)
- 消息TTL过期
- 队列达到了最大的长度
DLX其实也是一个正常的Exchange,和一般的exchange没有任何的区别,他能在任何的队列上被指定,实际上就是设置某个队列的属性
当队列中有死信时,rabbitMQ就会自动的将这个消息重新发布到设置的exchange中去,进而被路由到另一个队列
可以监听这个死信队列中消息做相应的处理,这个特性弥补了rabbitMQ3.0以前支持的Immediate参数的功能
死信队列的设置
首先设置私信队列的exchange和queue,然后进行绑定
- exchange: dlx.exchange(这个名称是自定义的)
- queue: dlx.queue(这个名称是自定义的)
- routingKey: # (匹配所有)
然后我们进行正常声明交换机,队列,绑定,只不过我们需要在队列加上一个参数即可标记为死信队列: argments.put("x-dead-letter-exchange", "dlx.exchange")
这样,消息再过期,requeue,队列在达到最大长度时,消息就可以直接路由到死信队列了.
整合RabbitMQ&Spring家族
不是搞Java的,这里不深究.
</rabbitmq快速入门></rabbitmq快速入门>
以上是 RabbitMQ消息中间件技术精讲笔记 的全部内容, 来源链接: utcz.com/z/515187.html