基于Flink+ClickHouse的一款适合于构建量化回测研究系统的高性能列式数据库

引用网络文章开启本课程的开篇:
在大数据分析领域中,传统的大数据分析需要不同框架和技术组合才能达到最终的效果,在人力成本,技术能力和硬件成本上以及维护成本让大数据分析变得成为昂贵的事情。让很多中小型企业非常苦恼,不得不被迫租赁第三方大型公司的数据分析服务。
ClickHouse开源的出现让许多想做大数据并且想做大数据分析的很多公司和企业耳目一新。ClickHouse 正是以不依赖Hadoop 生态、安装和维护简单、查询速度快、可以支持SQL等特点在大数据分析领域越走越远。
本课程采用全新的大数据技术栈:Flink+ClickHouse,让你体验到全新技术栈的强大,感受时代变化的气息,通过学习完本课程可以节省你摸索的时间,节省企业成本,提高企业开发效率。本课程不仅告诉你如何做项目,还会告诉你如何验证系统如何支撑亿级并发,如何部署项目等等。希望本课程对一些企业开发人员和对新技术栈有兴趣的伙伴有所帮助,如对我录制的教程内容有建议请及时交流。
课程概述:
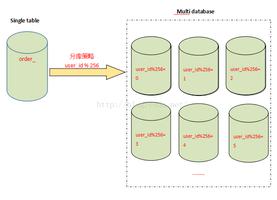
在这个数据爆发的时代,像大型电商的数据量达到百亿级别,我们往往无法对海量的明细数据做进一步层次的预聚合,大量的业务数据都是好几亿数据关联,并且我们需要聚合结果能在秒级返回。
那么我们该如何实现这一需求呢?基于Flink+ClickHouse构建电商亿级实时数据分析平台课程,将带领大家一步一步从无到有实现一个高性能的实时数据分析平台,该系统以热门的互联网电商实际业务应用场景为案例讲解,对电商数据的常见实战指标以及难点实战指标进行了详尽讲解,具体指标包括:概况统计、全站流量分析、渠道分析、广告分析、订单分析、运营分析(团购、秒杀、指定活动)等,该系统指标分为分钟级和小时级多时间方位分析,能承载海量数据的实时分析,数据分析涵盖全端(PC、移动、小程序)应用。
项目预览
本课程凝聚讲师多年一线大数据企业实际项目经验,大数据企业在职架构师亲自授课,全程实操代码,带你体验真实的大数据开发过程,代码现场调试。通过本课程的学习再加上老师的答疑,你完全可以将本案例直接应用于企业。
本套课程可以满足世面上绝大多数大数据企业级的海量数据实时分析需求,全部代码在老师的指导下可以直接部署企业,支撑千亿级并发数据分析。最后的项目代码也是具有极高的商业价值的,大家可以根据自己的业务进行修改,便可以使用。
**本课程包含的技术: **
开发工具为:IDEA、WebStorm
Flink1.9.0
ClickHouse
Hadoop2.6.0
Hbase1.0.0
Kafka2.1.0
Hive1.0.0
Jmeter(验证如何支撑亿级并发)
Docker (虚拟化部署)
HDFS、MapReduce
Zookeeper
SpringBoot2.0.2.RELEASE
SpringCloud Finchley.RELEASE Binlog、
Canal
MySQL
Vue.js、Nodejs
Highcharts
Linux Shell编程
**课程亮点: **
1.与企业无缝对接、真实工业界产品
2.ClickHouse高性能列式存储数据库
3.大数据热门技术Flink新版本
4.Flink join 实战
5.Flink 自定义输出路径实战
6.全链路性能压力测试
7.虚拟化部署
8.集成指标明细查询
9.主流微服务后端系统
10.分钟级别与小时级别多时间方位分析
11.数据库实时同步解决方案
12.涵盖主流前端技术VUE+jQuery+Ajax+NodeJS
13.集成SpringCloud实现统一整合方案
14.互联网大数据企业热门技术栈
15.支持海量数据的实时分析
16.支持全端实时数据分析
17.全程代码实操,提供全部代码和资料
内容详情:https://www.roncoo.com/view/1235566166733291521
以上是 基于Flink+ClickHouse的一款适合于构建量化回测研究系统的高性能列式数据库 的全部内容, 来源链接: utcz.com/z/514578.html