微服务(ribbon负载均衡)

问题1:它是怎么实现的负载均衡算法?
问题2:它是怎么通过实例名获取到的ip地址?
我们可以开始尝试跟踪一下:
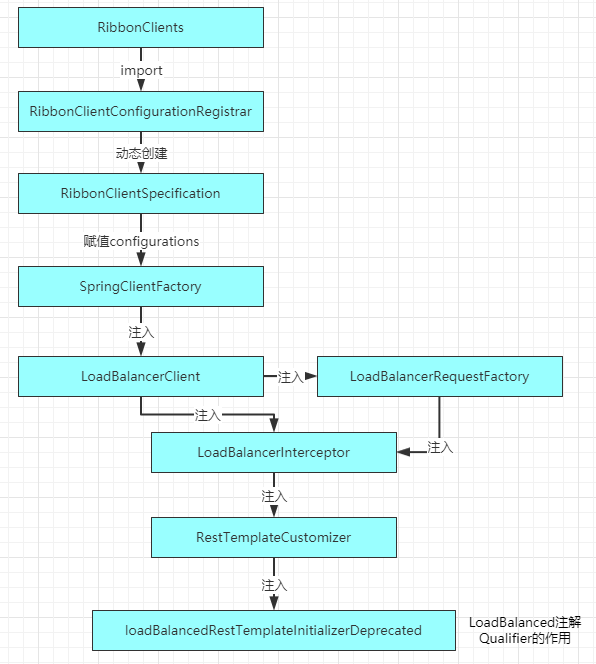
我们对RestTemplate已经比较了解了,它本身只提供了Http调用的功能,并不具备负载均衡的能力,那么我们可以猜测可能起到作用的就是@LoadBalanced这个注解。我们进入这个注解,会发现注解上存在一句注释:
Annotation to mark a RestTemplate bean to be configured to use a LoadBalancerClient.这句注释说明了,当前这个注解是表明RestTemplate 将要使用 LoadBalancerClient ,我们把这个bean给记下来。
接下来我们进入到LoadBalancerClient ` 发现它是一个接口,接口中提供了三个方法:
//使用从LoadBalancer中选择出来的实例执行<T> T execute(String serviceId, LoadBalancerRequest<T> request) throws IOException;
//使用从LoadBalancer中选择出来的实例执行,指定哪个实例来执行
<T> T execute(String serviceId, ServiceInstance serviceInstance, LoadBalancerRequest<T> request) throws IOException;
//为系统构建一个合适的host:port形式的Url
URI reconstructURI(ServiceInstance instance, URI original);
追踪它的实现类,我们会看到RibbonLoadBalancerClient这个类,它里面实现了这些方法。
我们通过RestTemplate 的追踪,我们会发现RestTemplate 中调用postForObject() 方法时会触发LoadBalancerInterceptor的方法,然后会发现它最后执行了一个this.loadBalancer.execute()方法
而这个execute方法就是我们在LoadBalancerClient 接口中看到的方法!
我们进入RibbonLoadBalancerClient中去查看它的实现方法--
public <T> T execute(String serviceId, LoadBalancerRequest<T> request, Object hint) throws IOException { //通过seviceid获取到我们的loadBalancer
ILoadBalancer loadBalancer = getLoadBalancer(serviceId);
//获取到我们的sever对象
Server server = getServer(loadBalancer, hint);
if (server == null) {
throw new IllegalStateException("No instances available for " + serviceId);
}
RibbonServer ribbonServer = new RibbonServer(serviceId, server, isSecure(server,
serviceId), serverIntrospector(serviceId).getMetadata(server));
return execute(serviceId, ribbonServer, request);
}
追踪getServer()方法 发现有这一行代码
return loadBalancer.chooseServer(hint != null ? hint : "default");我们可以得到一个结论,这行代码的chooseServer方法实现了负载均衡的策略,同时给我们返回了一个实例回来。
那么它是如何找到的host:port的呢?
进入到RibbonLoadBalancerClient中找到reconstructURI()方法,可以看到有一个RibbonLoadBalancerContext类,进入这个类,会发现它在构造器中传入了一个ILoadBalancer
在ILoadBalancer这个接口中存在addServers(List<Server> newServers)在内部我们可以得到一个结论,
我们所有的host:port形式的东西都存放在RibbonLoadBalancerContext中,它会去通过一个实例去获取到我们的
host:port形式的一个uri地址。也就是一个server对象。
追踪RibbonLoadBalancerContext我们会发现里面实现了很多方法
public class RibbonLoadBalancerContext extends LoadBalancerContext { public RibbonLoadBalancerContext(ILoadBalancer lb) {
super(lb);
}
//构造器2,初始化了一个Client的配置项
public RibbonLoadBalancerContext(ILoadBalancer lb, IClientConfig clientConfig) {
super(lb, clientConfig);
}
//构造器3,初始化时带入了重试机制,进入RetryHandler,
public RibbonLoadBalancerContext(ILoadBalancer lb, IClientConfig clientConfig,RetryHandler, handler) {
super(lb, clientConfig, handler);
}
/**记录活跃数,这里注意Serverstats类,里面定义了大量的状态(响应时间,错误数量,活跃数量等), *note 代表笔记本的意思,
*它实际上就是记录一些状态数据 noteOpenConnection 方法里面 实际上就给我们提供一次加一方法
*/
@Override
public void noteOpenConnection(ServerStats serverStats) {
super.noteOpenConnection(serverStats);
}
@Override
public Timer getExecuteTracer() {
return super.getExecuteTracer();
}
/***
* 比如这个,就是记录请求响应结束,这时候的异常会被记录。
*
*/
@Override
public void noteRequestCompletion(ServerStats stats, Object response, Throwable e,long responseTime) {
super.noteRequestCompletion(stats, response, e, responseTime);
}
@Override
public void noteRequestCompletion(ServerStats stats, Object response, Throwable e,long responseTime, RetryHandler errorHandler) {
super.noteRequestCompletion(stats, response, e, responseTime, errorHandler);
}
上面代码可以看到一个很明显的RetryHandler,跟踪进去看
public interface RetryHandler {
public static final RetryHandler DEFAULT = new DefaultLoadBalancerRetryHandler();
/**
* Test if an exception is retriable for the load balancer
*
* @param e the original exception
* @param sameServer if true, the method is trying to determine if retry can be
* done on the same server. Otherwise, it is testing whether retry can be
* done on a different server
*/
public boolean isRetriableException(Throwable e, boolean sameServer);
/**
* Test if an exception should be treated as circuit failure. For example,
* a {@link ConnectException} is a circuit failure. This is used to determine
* whether successive exceptions of such should trip the circuit breaker to a particular
* host by the load balancer. If false but a server response is absent,
* load balancer will also close the circuit upon getting such exception.
*/
public boolean isCircuitTrippingException(Throwable e);
/**
* @return Number of maximal retries to be done on one server
*/
//返回在同一台服务器最大的重试次数
public int getMaxRetriesOnSameServer();
/**
* @return Number of maximal different servers to retry
*/
//返回在下一个服务器最大重试次数
public int getMaxRetriesOnNextServer();
}
这些东西只需要了解一下
问题3:它的负载均衡器有哪些?
追踪我们的RibbonLoadBalancerClient中的execute中的loadBalancer.chooseServer()会发现它调用了接口ILoadBalancer中的chooseServer()方法.
追踪ILoadBalancer我们可以看到它内部其实实现了这几种方法:
//添加服务实例public void addServers(List<Server> newServers);
//选择服务实例
public Server chooseServer(Object key);
//由负载均衡器的客户端调用,以通知服务器宕机,否则,LB会认为它还活着,直到下一个Ping周期——有可能
public void markServerDown(Server server);
@Deprecated //不推荐使用
public List<Server> getServerList(boolean availableOnly);
//返回一个启动并且正常的服务
public List<Server> getReachableServers();
//返回所有服务
public List<Server> getAllServers();
结论:ILoadBalancer接口实际上给我们提供了三种结果
- 添加服务实例
- 返回服务实例
- 让服务下线
它的默认实现就是ZoneAwareLoadBalancer
我们可以在RibbonClientConfiguration#ribbonLoadBalancer()中看到它如果没有设定负载均衡器就返回默认的。
- ZoneAwareLoadBalancer 是对DynamicServerListLoadBalancer的扩展,它重写了setServerListForZones()方法,这个方法在父类的作用是根据按区域zone的分组实例列表,再给每一个Zone对应一个zoneStats来存储一些状态和统计信息的。
重写之后我们可以看到,在该实现中创建了一个ConcurrentHashMap类型的balance对象,用来存储每个Zone区域对应的负载均衡器,负载均衡器的创建就是通过getLoadBalancer(zone).setServersList(entry.getValue());来完成的。 这是ILoadBalancer的默认实现
查看这个方法的实现类,我们会发现这里有几个类实现了它的方法:
- BaseLoadBalaner 是实现Ribbon负载均衡的基础实现类,在该类中定义了很多关于负载均衡的基础内容
- 它维护了两个存储服务实例Server对象的列表,一个存储所有服务实例清单,一个存储正常服务实例清单
- 它定义了检查服务器里是否正常的Iping 对象,需要在构造时注入它的实现
- 定义了检查服务实例操作的执行策略对象IPingStrategy
- 它定义了负载均衡处理规则IRule
- 它定义了用来存储负载均衡器的各个服务实例属性和统计信息的LoadBalancerStats
在BaseLoadBalaner基础上,还有两个子类
DynamicServerListLoadBalancer 是对BaseLoadBalaner 做的一个扩展,在父类的基础上,实现了服务实例清单在运行期的动态更新能力;同时还具备了对服务实例清单过滤的功能,也就是说,使用它的时候,可以通过过滤器来选择性的获取一批服务实例的清单。
1.新增了一个ServerList<T> serverListImpl的接口,去跟踪ServerList 会发现内部定义了两个抽象方法
public interface ServerList<T extends Server> {
//获取初始化的服务实例清单
public List<T> getInitialListOfServers();
//获取更新的服务实例清单
public List<T> getUpdatedListOfServers();
}
继续追踪,会发现它的实现有五个,我们需要去判断一下,在这里它用的是什么方式来做的实现?
我们做一个猜测,既然在负载均衡器中需要实现服务实例的动态更新,那么它就势必需要有去访问Eureka来获取服务实例的能力。我们可以去查看一下EurekaRibbonClientConfiguration
@Bean @ConditionalOnMissingBean
public ServerList<?> ribbonServerList(IClientConfig config, Provider<EurekaClient> eurekaClientProvider) {
if (this.propertiesFactory.isSet(ServerList.class, this.serviceId)) {
return (ServerList)this.propertiesFactory.get(ServerList.class, config, this.serviceId);
} else {
/**通过DiscoveryEnabledNIWSServerList内部的obtainServersViaDiscovery()
从注册中心通过serviceId获取到服务实例列表,将状态为UP的服务放入list返回**/
DiscoveryEnabledNIWSServerList discoveryServerList = new DiscoveryEnabledNIWSServerList(config, eurekaClientProvider);
//通过discoveryServerList 获取到两个集合--初始化的服务清单,更新的服务清单
DomainExtractingServerList serverList = new DomainExtractingServerList(discoveryServerList, config, this.approximateZoneFromHostname);
return serverList;
}
}
在这里我们能够看到里面是采用了DomainExtractingServerList来进行实现的。我们开始追踪DomainExtractingServerList会发现它在构造器内部,通过传入的List<DiscoveryEnabledServer>
在实现这两个方法的时候通过setZones方法获得了两个集合。
内部的实现方法过于复杂,感兴趣的同学可以自己追踪。只要知道流程就OK了。
问题4:刚才看到了IRule这个接口,也知道了这是ribbon的负载均衡策略,那么具体它包含了哪些策略?
默认策略:ZoneAvoidanceRule ===> RibbonClientConfiguration#ribbonRule()
- ZoneAvoidanceRule 规避区域策略
- AbstractLoadBalancerRule 策略的抽象类,它在内部定义了ILoadBalancer对象,这个对象主要是用来在具体选择哪种策略的时候,获取到负载均衡器中维护的信息的。
- AvailabilityFilteringRule该策略继承自抽象策略PredicateBasedRule所以也继承了"先过滤清单,再轮询选择"的基本处理逻辑,该策略通过线性抽样的方式直接尝试可用且较空闲的实例来使用,优化了父类每次都要遍历所有实例的开销。
- BestAvailableRule继承自ClientConfigEnabledRoundRobinRule该策略的特性是可选出最空闲的实例
- ClientConfigEnabledRoundRobinRule该策略较为特殊,我们一般不直接使用它。因为它本身并没有实现什么特殊的处理逻辑。通过继承该策略,默认的choose就实现了线性轮询机制,在子类中做一些高级策略时通常可能存在。一些无法实施的情况,就可以用父类的实现作为备选
- PredicateBasedRule抽象策略,继承自ClientConfigEnabledRoundRobinRule,基于Predicate的策略 Predicateshi Google Guava Collection工具对集合进行过滤的条件接口
- RandomRule 随机数策略,它就是通过一个随机数来获取uplist的某一个下标,再返回。
- RetryRule 带重试机制策略,它在内部还定义了一个IRule,默认使用了RoundRobinRule,在内部实现了反复重试的机制,如果重试能够得到一个服务,就返回,如果不能就会根据之前设置的时间来决定,时间一到就返回null.
- RoundRobinRule 一个轮询策略,通过一个count计数变量,每次循环都会累加,注意,如果一直没有server可供选择达到了10次,就会打印一个警告信息。
- WeightedResponseTimeRule 这个策略是对轮询策略的扩展,增加了根据实例的运行情况来计算权重,并根据权重来挑选实例,用以达到更好的分配结果。
这个策略比较复杂,请注意:
首先类里面定义了一个定时任务DynamicServerWeightTask,默认30秒执行一次
class DynamicServerWeightTask extends TimerTask { public void run() {
ServerWeight serverWeight = new ServerWeight();
try {
//每隔30秒计算一次权重
serverWeight.maintainWeights();
} catch (Exception e) {
logger.error("Error running DynamicServerWeightTask for {}", name, e);
}
}
}
public void maintainWeights() {
ILoadBalancer lb = getLoadBalancer();
if (lb == null) {
return;
}
if (!serverWeightAssignmentInProgress.compareAndSet(false, true)) {
return;
}
try {
logger.info("Weight adjusting job started");
AbstractLoadBalancer nlb = (AbstractLoadBalancer) lb;
LoadBalancerStats stats = nlb.getLoadBalancerStats();
if (stats == null) {
// no statistics, nothing to do
return;
}
//计算所有实例的想赢时间的总和
double totalResponseTime = 0;
// find maximal 95% response time
for (Server server : nlb.getAllServers()) {
//如果服务不在缓存中,就自动加载。
ServerStats ss = stats.getSingleServerStat(server);
totalResponseTime += ss.getResponseTimeAvg();
}
//遍历计算每个实例的权重,公式如下:weightSoFar+totalResponseTime - 平均响应时间
Double weightSoFar = 0.0;
// create new list and hot swap the reference
List<Double> finalWeights = new ArrayList<Double>();
for (Server server : nlb.getAllServers()) {
ServerStats ss = stats.getSingleServerStat(server);
double weight = totalResponseTime - ss.getResponseTimeAvg();
weightSoFar += weight;
finalWeights.add(weightSoFar);
}
setWeights(finalWeights);
} catch (Exception e) {
logger.error("Error calculating server weights", e);
} finally {
serverWeightAssignmentInProgress.set(false);
}
}
}
这段代码利用了一个公式,weightSoFar+totalResponseTime - 平均响应时间
我们可以举个例子 假设有,A,B,C三个实例可以选择,他们的平均响应时间为10,40,80,那么我们可以得到它的一个总响应时长为10+40+80 = 130
那么根据这个公式可以得到的权重
A:0+130 -10 =120;
B:120+(130-40) = 210;
C: 210 +(130-80) = 260;
这里实际上是一个数字轴,它会自己生成一个随机数落在这个数字轴上,在哪个区间就会去选择哪台服务。
问题5:Ribbon的ping策略
在ribbon中IPing这个对象定义了它的ping策略,我们都知道,需要判断服务是否存活的方式通常都是用心跳,在计算机中心跳通常都是ping这样标识,我们会每隔一段时间去访问一次服务,一旦有正确返回状态,我们就认为当前服务存活。
同样的我们可以在RibbonClientConfiguration下去看到它的默认策略DummyPing()
问题6:服务列表ServerList<Server> 的初始化
RibbonClientConfiguration#ribbonServerList下会初始化
ServerList主要是负责:
- 获取初始化的服务列表
- 获取更新的服务列表
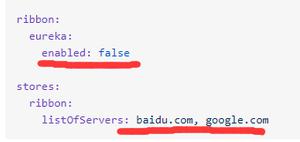
它的默认实现比较有意思,如果Eureka关闭,它实现的就是ConfigurationBasedServerList
如果我们整合了Eureka,会发现它默认实现的就是DiscoveryEnabledNIWSServerList -->我们可以通过EurekaRibbonClientConfiguration#ribbonServerList中去看到这个服务列表
问题7:Ribbon的自动装配
- RibbonAutoConfiguration 内部初始化了比较重要的两个东西:
LoadBalancerClient 这个我们在之前解释过
PropertiesFactory 通过一些配置化的方式进行组装。
- RibbonClientConfiguration 这个里面实现了非常多的东西
RibbonLoadBalancerContext
IRule 规则
IPING 心跳
ServerList 服务列表
ILoadBalancer
IClientConfig
问题8:重试机制
在我们使用ribbon中,一旦某个服务实例宕机或者掉线,而我们的eureka没有及时清理,会发生返回错误的情况,那么针对这种情况下,我们有没有什么机制可以去解决问题的?
我们可以继续去找LoadBalancerAutoConfiguration 会看到这样一段代码
@Configuration@ConditionalOnClass(RetryTemplate.class)
public static class RetryInterceptorAutoConfiguration {
@Bean
@ConditionalOnMissingBean
public RetryLoadBalancerInterceptor ribbonInterceptor(LoadBalancerClient loadBalancerClient, LoadBalancerRetryProperties properties,LoadBalancerRequestFactory requestFactory,LoadBalancedRetryFactory loadBalancedRetryFactory) {
return new RetryLoadBalancerInterceptor(loadBalancerClient, properties, requestFactory, loadBalancedRetryFactory);
}
@Bean
@ConditionalOnMissingBean
public RestTemplateCustomizer restTemplateCustomizer(final RetryLoadBalancerInterceptor loadBalancerInterceptor) {
return restTemplate -> {
List<ClientHttpRequestInterceptor> list = new ArrayList<>(
restTemplate.getInterceptors());
list.add(loadBalancerInterceptor);
restTemplate.setInterceptors(list);
};
}
}
它在这里面定义了负载均衡的重试机制,我们可以来看看这个怎么用的。
导入pom.xml
<!--引入重试机制,让重试生效--><dependency>
<groupId>org.springframework.retry</groupId>
<artifactId>spring-retry</artifactId>
</dependency>
然后,我们再来尝试,我们会发现重试机制生效了。
以上是 微服务(ribbon负载均衡) 的全部内容, 来源链接: utcz.com/z/513261.html