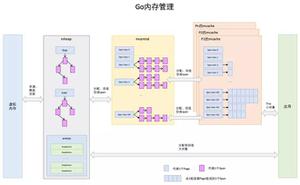
Netty快速入门(03)JavaNIO介绍Buffer

NIO 介绍
NIO,可以说是New IO,也可以说是non-blocking IO,具体怎么解释都可以。
NIO 1是在JSR51里面定义的,在JDK1.4中引入,因为BolckingIO不支持高并发网络编程,这也是Java1.4以前被人诟病的原因。NIO 2是在JSR203中定义的,在JDK1.7中引入,这是JavaNIO整个的发展历程。NIO 1和NIO 2并不是一个新旧替代的关系,而是一个补充的关系,NIO 2补充了1中缺少的一些东西。我们可以看一下两个的内容:
NIO 1(本系列文章只介绍NIO 1):
> Buffers
>
> Channels
>
> Selectors
NIO 2:
> Update
>
> New File System API(引入文件系统API,之前的NIO 1当中,在Linux中操作文件都需要有读写权限,操作各种属性等等,在Java中是没办法操作的,所以这里引入了一个文件API)
>
> Asynchronous IO(即 常说的 AIO)
BIO与NIO的比较
BIO:
> 面向流(Stream Oriented)(连接建立的时候就可以获得InputStream和OutputStream,就可以通过流来进行操作,流是没有缓冲的,效率比较低)
>
> 阻塞IO(Blocking IO)
NIO:
> 面向缓冲区(Buffer Oriented)(读写都是通过Buffer来进行的,要读数据就得先把数据读到Buffer中去,写数据也要先把数据写到Buffer中,再从Buffer写到网络中去)
>
> 非阻塞IO(Non Blocking IO)(IO复用模型)
>
> 选择器(Selectors)
NIO Buffer 学习
上面说了,NIO三个最重要的概念就是Buffer,Channel,Selector,Buffer缓冲区是用来放数据,Channel就是通道,可以把数据写到别的地方,Selector就是一个多路复用器,用来实现线程复用。下面会一个一个说。NIO不像BIO那么简单,甚至比起来要复杂的多。所以要一块一块的学习。下面先学习Buffer。
一个Buffer本质上是内存中的一块,可以将数据写入这块内存,也可以从这块内存中读取数据。JavaNIO中定义了七种类型的Buffer:
可以看到几种基本类型对应的都有Buffer(除了布尔类型),可以存放不同类型的原始数据。
Buffer有三大核心概念:position,limit,capacity。
> 最好理解的是capacity,代表Buffer的容量,申请一个容量为1024的Buffer,那么capacity就是1024。没有特殊情况,capacity永远不会变。一旦Buffer的数据大小达到了capacity,需要清空Buffer,才能从新写入值。
>
> position就是表示下一个可以操作(读或者写)的位置。JavaNIO很多人诟病比较复杂的一个地方就是,把读操作和写操作混在一起,同一种操作可以分成读模式和写模式,从读模式到写模式需要自己手动去切换(执行flip),就是说没有分开的读指针和写指针,就一个操作指针position,在写模式下,position表示下一个可以写入的位置,在读模式下,position表示下一个可以读的位置。两种模式在切换的时候,position都会归零,这样就可以从头开始操作。比如在写模式下,position从0写到了5,那么切换到读模式,position会变成0,从第一位开始读。
>
> limit表示一个限制的最大位置,在写模式下,limit代表的是最大能写入的数据的位置,这个时候limit等于capacity。写结束后切换到读模式,此时的limit等于Buffer中实际的数据大小,因为Buffer不一定被写满,比如写模式下在capacity为10的Buffer中写入了五个数据,那么切换到读模式,capacity还是10,limit变为5,position自然归0,值变为0。
Buffer的创建
Buffer大致分为两种类型,一种是Direct Buffer,一种是non-direct Buffer,也叫HeapBuffer。下面看一下比较:
Non-direct ByteBuffer
> HeapByteBuffer,标准的java类(表示在堆上创建了一个Buffer,就是一个普通的Java类,在堆上申请内存存放Buffer实例)
>
> 维护一份byte[] 在JVM堆上
>
> 创建开销小(heap申请内存是很快的,所以创建开销很小)
>
> 拷贝到临时DirectByteBuffer,但临时缓冲区使用缓存。聚集写/发散读时没有缓存临时缓冲区 (也就是前面的线程模型提到的当做数据拷贝的时候,并不能直接从堆上直接写到内核态缓冲区发送出去,必须要在native中申请一块内存,先把数据拷贝到native中去,然后再发送)
>
> 可以自动GC(垃圾回收)
Direct ByteBuffe
> 底层存储在非JVM堆上,通过native代码操作(数据存储在堆之外,也就是JVM之外的普通内存空间,Java通过JNI调用c函数malloc申请的nvtive内存,也就代表JVM是无法回收的)
>
> -XX:MaxDirectMemorySize=<size>
>
> 创建开销大(需要调用c函数申请,创建开销大)
>
> 无需临时缓冲区做拷贝(数据本来就在native中,可以直接发送)
>
> 需要自己GC,每次创建或者释放都需要调用一次System.gc()
我们来看一下代码,创建Buffer有两种方法,allocate/allocateDirect方法,从名字就能看出各自创建的是上面哪种Buffer。或者借助数组创建(使用warp)。我们先用allocate创建:
> ByteBuffer buffer0 = ByteBuffer.allocate(10);
可以看到,很简单,然后用allocateDirect方法创建:
> ByteBuffer buffer1 = ByteBuffer.allocateDirect(10);
然后用第三种,根据一个数组去创建:
> byte[] bytes = new byte[10];
>
> ByteBuffer buffer2 = ByteBuffer.wrap(bytes);
根据数组创建的时候,还可以设置偏移量(新Buffer的位置)和长度:
> byte[] bytes2 = new byte[10];
>
> //指定范围
>
> ByteBuffer buffer3 = ByteBuffer.wrap(bytes2, 2, 3);
上面一共用四种方法创建了Buffer,我们来打印出四种buffer的信息,包括数组的信息,position,limit,capacity三个信息,以及剩余可操作的空间(每个buffer都打印):
> if (buffer0.hasArray()) {
>
> System.out.println("buffer0 array: " + buffer0.array());
>
> System.out.println("Buffer0 array offset: " + buffer0.arrayOffset());
>
> }
>
> System.out.println("Position: " + buffer0.position());
>
> System.out.println("Limit: " + buffer0.limit());
>
> System.out.println("Capacity: " + buffer0.capacity());
>
> System.out.println("Remaining: " + buffer0.remaining());
hasArray()判断表示的是,buffer底层是否是以数组的形式存储的,是就为true,对于HeapByteBuffer,底层都是数组,所以weitrue,DirectByteBuffer底层不是以数组形式存储的,所以为false,使用warp创建的Buffer实际上返回的也是HeapByteBuffer,也在堆上,我们先来看buffer0的打印结果
前两行打印出了数组和数组的偏移量,后面打印出一些属性,因为还没有做任何操作,所以position是0,capacity理所当然是10,可操作的最后位置limit这时候等于capacity,也是10,可操作的剩余空间大小也是10,所以打印出了上面的结果。根据上面创建出的实际情况,buffer0,buffer1,buffer2打印的结果应该是一样的,实际也是如此:
buffer3有些不同,我们创建的时候设置了前提条件,因为偏移量为2,所以position的起始位置是从2开始的,长度设置成了3,所以可操作的最大位置limit是5(2加3),因为是根据数据byte2创建的,所以总的容量还是10,所以capacity还是10,剩余可操作的空间自然就是长度3,所以buffer3的打印结果如下:
Buffer的访问
上面写了代码说了怎么创建Buffer,下面看怎么访问Buffer。先创建一个buffer:
> ByteBuffer buffer = ByteBuffer.allocate(10);
然后看一个打印Buffer信息的方法:
然后我们打印一下刚刚创建的Buffer:
> printBuffer(buffer);
打印结果:
上面打印的信息很简单,不再解释,下面看第一个操作,开始向Buffer中写入数据,然后打印(注意写入的操作):
我们向Buffer中写入了五个数据,来看看Buffer的信息如何变化:
position变成了5,其它信息并未改变,下一步,我们转换buffer的状态,由写模式改为读模式,然后打印:
打印结果:
可以看到,模式转换后,position归零,limit到了已写入数据的末尾,capacity自然不变,现在读取两个元素(注意读操作):
打印结果:
注意上面position的变化,下面我们来标记一下当前buffer的位置,这样进行多次操作后,还可以回到标记时的状态:
打印结果自然没什么变化:
再次读取两个数据:
查看打印结果:
position再次变化,下面恢复到mark之前的位置:
打印结果:
下面来对buffer进行压缩操作,也就是将 position 与 limit之间的数据复制到buffer的开始位置,复制后 position = limit -position,limit = capacity,但如果position 与limit 之间没有数据的话发,就不会进行复制:
打印结果:
可以看到,压缩后,将未读过的数据直接移到了开始位置,position直接移到了这些数据的末尾,并且切换到写模式,所以position等于未操作的数据空间长度,也就是limit减去原来的position,capacity回到了空间最后的位置,下面我们情况buffer:
打印结果:
可以看到,clear直接把buffer回到了初始状态。通过上面几种操作,大家可以对ByteBuffer几种指针变化的流程有所了解。
Slice切片复制Buffer操作
这种复制操作有点类似视图的概念,是一种浅复制,调用该方法得到的新缓冲区所操作的数组还是原始缓冲区中的那个数组,不过,通过slice创建的新缓冲区只能操作原始缓冲区中数组剩余的数据,即索引为调用slice方法时原始缓冲区的position到limit索引之间的数据,超出这个范围的数据通过slice创建的新缓冲区无法操作到。我们给定一个Buffer,放满数据,然后打印:
打印结果:
然后手动指定position和limit的位置:
打印结果:
然后根据定位到的位置,切分buffer,切分后的新buffer 的position为0,limit和capacity都为原来的position和limit之间的长度,打印新buffer:
打印结果:
循环切分出来的新buffer,一个一个读取出来,然后乘以11,然后放到原位置:
打印结果:
可以看到因为读操作所以position发生变化,手动定位原来buffer的开始和结束位置,循环读取打印原来buffer中的每个数据,发现切分的buffer修改的同时,原来的buffer也修改了,说明slice也是浅拷贝:
打印结果:
Duplicate复制Buffer操作
Duplicate表示的也是浅拷贝,也就是只复制饮用,对象实例还是指向一个。我们创建一个buffer,放慢数据,然后打印:
打印结果:
转换读写状态,然后打印:
打印结果:
手动定位位置到3和6,mark一次,然后又单独定位position到5:
打印结果:
浅复制一份,包括原来的position和limit的位置也一起复制了过来,原来的buffer清空,position和limit的位置复位(注意clear只是指针复位,数据还在):
拷贝出来的position和limit的位置还是最后清空前的位置,打印结果:
拷贝出来的也清空,position和limit的位置也回到最左和最右:
打印结果:
asReadOnlyBuffer操作与Duplicate一样,只是前者是只读的。
缺点
NIO编程负责的一个原因就是Buffer复杂,Buffer指针变来变去还是比较复杂的,而且本来就一个指针,读写模式还有互相转换,这种要自己小心的控制才行。模式搞错了会出大问题。
代码地址:https://gitee.com/blueses/netty-demo 02
> 本文由博客一文多发平台 OpenWrite 发布! </size>
以上是 Netty快速入门(03)JavaNIO介绍Buffer 的全部内容, 来源链接: utcz.com/z/512678.html