【模块十】分布式篇Redis缓存篇☞参考答案

一、简介
1.是什么
Rsdis是一个基于内存的高性能key-value数据库
2.特点
(1) 速度快,因为数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)
(2) 支持丰富数据类型,支持string,list,set,sorted set,hash
(3) 支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行
(4) 丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除
3.支持的5种数据类型
1.字符串String
常用命令: set,get,setex(key, seconds,value),setnx(key,value)等。
String数据结构是简单的key-value类型,value其实不仅可以是String,也可以是数字。String类型是 Redis最基本的数据类型,String类型的值最大能存储 512MB。
2.哈希Hash
常用命令: hget,hset,hgetall 等。
Hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。比如:
key=zhangsan
value={
“id”: 1,
“name”: “SnailClimb”,
“age”: 22,
“location”: “Wuhan, Hubei”
}
3.列表List
常用命令: lpush,rpush,lpop,rpop,lrange等
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。
4.集合Set
常用命令: sadd,spop,smembers等
set 是可以自动排重的。
可以基于 set 轻易实现交集、并集、差集的操作。
5.有序集合Sorted Set
常用命令: zadd,zrange,zrem,zcard等
和set相比,sorted set增加了一个权重参数score,使得集合中的元素能够按score进行有序排列。
二、Redis常遇到四种情况
(一)缓存和数据库双写一致性问题
(二)缓存雪崩问题
(三)缓存击穿问题
(四)缓存的并发竞争问题
三、缓存穿透&缓存雪崩
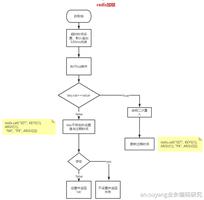
1.缓存穿透
一般的缓存系统,都是按照key去缓存查询,如果不存在对应的value,就应该去后端系统查找(比如DB)。一些恶意的请求会故意查询不存在的key,请求量很大,就会对后端系统造成很大的压力。
如何避免:
1:对查询结果为空的情况也进行缓存,缓存时间设置短一点,或者该key对应的数据insert了之后清理缓存。
2:对一定不存在的key进行过滤。可以把所有的可能存在的key放到一个大的Bitmap中,查询时通过该bitmap过滤。
2.缓存雪崩
当缓存服务器重启或者大量缓存集中在某一个时间段失效,这样在失效的时候,会给后端系统带来很大压力。导致系统崩溃。
如何避免:
1:在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
2:做二级缓存,A1为原始缓存,A2为拷贝缓存,A1失效时,可以访问A2,A1缓存失效时间设置为短期,A2设置为长期
3:不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀
四、Redis作为缓存最大的问题
当服务器内存有限时候,如果大量使用缓存键而且过期时间设置过长会导致redis占满内存;另一方面如果为了防止redis占用内存过大而将缓存键的过期时间设得太短,就可能导致缓存命中率过低并且大量内存白白闲置。实际开发中很难为缓存键设置合理的过期时间
解决方案:限制redis能使用的最大内存,并让redis按照一定的规则淘汰不需要的缓存键
五、过期策略
1.三种键值过期策略
定时删除
- 含义:在设置key的过期时间同时,为key创建一个定时器,让定时器在key的过期时间来临时,对key进行删除
- 优点:保证内存尽快被释放
- 缺点:
- 若过期key很多,删除这些key会占用很多的CPU时间,在CPU时间紧张的情况下,CPU不能把所有的时间用来做要紧的事儿,还需要去花时间删除这些key
- 定时器的创建耗时,若为每一个设置过期时间的key创建一个定时器(将会有大量的定时器产生),性能影响严重
- 没人用
惰性删除
- 含义:key过期的时候不删除,每次从数据库获取key的时候去检查是否过期,若过期,则删除,返回null。
- 优点:删除操作只发生在从数据库取出key的时候发生,而且只删除当前key,所以对CPU时间的占用是比较少的,而且此时的删除是已经到了非做不可的地步(如果此时还不删除的话,我们就会获取到了已经过期的key了)
- 缺点:若大量的key在超出超时时间后,很久一段时间内,都没有被获取过,那么可能发生内存泄露(无用的垃圾占用了大量的内存)
定期删除
含义:定期删除指的是redis默认是每隔100ms就随机抽取一些设置了过期时间的key,检查其是否过期,如果过期就删除。
注意:这里可不是每隔100ms就遍历所有的设置过期时间的key,那样就是一场性能上的灾难。
实际上redis是每隔100ms随机抽取一些key来检查和删除的。
- 优点:
- 通过限制删除操作的时长和频率,来减少删除操作对CPU时间的占用--处理"定时删除"的缺点
- 定期删除过期key--处理"惰性删除"的缺点
- 缺点
- 在内存友好方面,不如"定时删除"
- 在CPU时间友好方面,不如"惰性删除"
- 难点
- 合理设置删除操作的执行时长(每次删除执行多长时间)和执行频率(每隔多长时间做一次删除)(这个要根据服务器运行情况来定了)
- 优点:
看完上面三种策略后可以得出以下结论:
定时删除和定期删除为主动删除:Redis会定期主动淘汰一批已过去的key
惰性删除为被动删除:用到的时候才会去检验key是不是已过期,过期就删除
惰性删除为redis服务器内置策略
定期删除可以通过:
- 第一、配置redis.conf 的hz选项,默认为10 (即1秒执行10次,100ms一次,值越大说明刷新频率越快,Redis性能损耗也越大)
- 第二、配置redis.conf的maxmemory最大值,当已用内存超过maxmemory限定时,就会触发主动清理策略
2.Redis采用的过期策略
惰性删除+定期删除
- 惰性删除流程
- 在进行get或setnx等操作时,先检查key是否过期,
- 若过期,删除key,然后执行相应操作;
- 若没过期,直接执行相应操作
- 定期删除流程(简单而言,对指定个数个库的每一个库随机删除小于等于指定个数个过期key)
- 遍历每个数据库(就是redis.conf中配置的"database"数量,默认为16)
- 检查当前库中的指定个数个key(默认是每个库检查20个key,注意相当于该循环执行20次,循环体时下边的描述)
- 如果当前库中没有一个key设置了过期时间,直接执行下一个库的遍历
- 随机获取一个设置了过期时间的key,检查该key是否过期,如果过期,删除key
- 判断定期删除操作是否已经达到指定时长,若已经达到,直接退出定期删除。
- 检查当前库中的指定个数个key(默认是每个库检查20个key,注意相当于该循环执行20次,循环体时下边的描述)
- 遍历每个数据库(就是redis.conf中配置的"database"数量,默认为16)
六、内存淘汰机制
1.产生背景
如果定期删除漏掉了很多过期key,然后也没及时去查,也就没走惰性删除,此时会怎么样?
会导致大量过期key堆积在内存里,导致Redis内存块耗尽了,怎么办?
答案:走内存淘汰机制
2.六种淘汰机制
内存淘汰机制:即内存占用达到内存限制设定值时触发的Redis的淘汰策略来删除键。
(LRU:Least Recently Used最近最少使用的;LFU:Least Frequently Used最不常用的)
- noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。
- allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。
- allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。
- volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。
- volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。
七、 Redis持久化
持久化就是把内存的数据写到磁盘中去,防止服务器宕机导致内存数据丢失。
Redis 提供了两种持久化方式:RDB(默认)和AOF
RDB:Redis DataBase
功能核心函数rdbSave(生成RDB文件)和rdbLoad(从文件加载内存)两个函数
以上是 【模块十】分布式篇Redis缓存篇☞参考答案 的全部内容, 来源链接: utcz.com/z/512652.html