Redis设计与实现主从复制原理

上一篇:Redis设计与实现-事件
通过前面的学习知道了Redis通过多种数据结构实现5种数据类型,以及Redis数据库的一些维护操作和相当重要的持久化知识。另外还有Redis在LINXU操作系统上通过EPOLL的IO多路复用技术设计了自己的文件事件处理器,以单线程方式循环处理文件事件、时间事件。
接下来看看Redis的主从复制原理,关于Redis主从搭建,请百度一下,关键点就是在从服务器中设置salveof属性,并且要关闭防火墙或者防火墙策略
概要
Redis主从技术实现了读写分离,有一定的容灾备份能力,但是如何保证主从数据一致性喃?Redis有旧版和新版两种,先说说旧版
旧版复制
该模块分为同步和命令传播两个模块,同步负责初始第一次或者断网重连时主从数据库一致性,而命令传播是在同步之后解决主服务器不断执行新的写命令之后的主从数据库一致性
同步
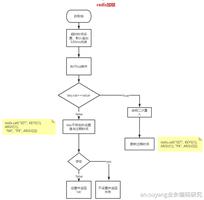
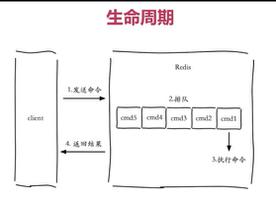
图解
描述
从服务器发送sync命令
主服务器执行BGSAVE命令
主服务器将执行BGSAVE命令期间的所有写命令记录到一个缓冲区当中
主服务器将生成的RDB文件发给从服务器,从服务器载入RDB文件
主服务器将缓冲区中的命令发给从服务器,从服务器执行命令
命令传播
前面的同步解决了初始时主从数据库状态一直的问题,但是主服务器一直在处理新的写命令,主从要同步的话,还得想办法让从服务器像主服务器一样执行命令或者复制数据。Redis是采用的传播命令并执行
解决办法:将主服务器执行过的写命令都发送给从服务器再执行一遍
缺点
主服务器执行BGSAVE相当的耗资源:CPU、磁盘
网络传输RDB文件、消耗大量的网络资源
从服务器重新载入RDB文件速度慢
从服务器载入RDB文件时会阻塞请求
新版复制
新版复制完全解决了断线重连旧版复制的缺点
新版复制具有完全同步和部分同步的功能,完全同步和旧版相差甚少,以下篇幅主要是了解部分同步是如何实现的。
复制偏移量
新版部分复制实现的一个非常重要的变量:复制偏移量。它是主从服务器都维护的命令传播字节数的值,比如:
主服务器向从服务器发送了10个字节,主服务器的复制偏移量+10
从服务器收到了发送过来的10个字节,从服务器的复制偏移量+10
因此得到一个结论:如果主从服务器处于一致状态,那么它们的复制偏移量相同,否则不相同。
通过下面的一张图看看不同场景下的复制偏移量
补充:复制偏移量在后面的哨兵模式中“从所有的从服务器中选择一个新的主服务器时有用:在某种情况下,数据最优的被选举”
复制挤压缓冲区
复制挤压缓冲区中记录的是主服务器写命令按字节编号(与复制偏移量对应)的结果,如图:
复制挤压缓冲区是一个固定长度的FIFO队列,一旦缓冲区满,那么最先入队的会被弹出,因此会丢失掉过旧的数据。所以基于这种模式需要根据实际情况来设置缓冲区大小,否则可能触发断网重连的全同步。设置的参考公式:
公式:repl-backlog-size=2*SECOND*WRITE_SIZE_PER_SECONDSECOND:断网重连平均耗时
WRITE_SIZE_PER_SECOND:每秒写命令大小(包含协议信息)
另外还有一个repl-backlog-ttl是设置主服务器没有从服务器时,多久将复制积压缓冲区清空
将复制挤压缓冲区和复制偏移量通过程序串联起来就可以完成新版部分复制功能
图解
描述
从服务器与主服务器重新建立上链接
从服务器将自己的复制偏移量1006和RUN ID=AABBCC发给主服务器(可能是新的-比如哨兵模式从多个从服务器中选择了一个新的主服务器)
主服务器判断RUN ID=AABBCC是不是当前主服务器,如果不是则进行全同步,否则继续往下
主服务器判断1006之后的数据是否在复制挤压缓冲区当中,如果没有则进行全同步,否则将复制挤压缓冲区中1006之后的数据全部发送给从服务器
从服务器接收主服务器发送过来的复制挤压缓冲区中的数据,执行命令
主从数据库状态达到一致
RUN ID是服务器运行的ID,主从服务器都有自己的RUN ID。
为了方便书写将RUN ID偷懒写成了AABBCC,其实它是40个随机十六进制的字符组成。
以上是 Redis设计与实现主从复制原理 的全部内容, 来源链接: utcz.com/z/512552.html