源码分析Dubbo负载算法

Dubbo支持在服务调用方对服务提供者采用负载均衡算法,LoadBalance 接口定义如下:
@SPI(RandomLoadBalance.NAME)public interface LoadBalance {
/**
* select one invoker in list.
*
* @param invokers invokers.
* @param url refer url
* @param invocation invocation.
* @return selected invoker.
*/
@Adaptive("loadbalance")
<t> Invoker<t> select(List<invoker<t>> invokers, URL url, Invocation invocation) throws RpcException;
}
从中透露出如下几个信息:
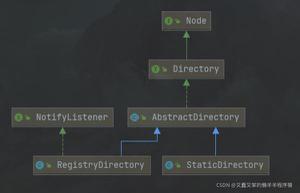
默认如果不配置,使用RandomLoadBalance策略(加权随机负载算法)。整个Dubbo的负载均衡类图如下所示:
上述各种路由负载策略,对应的配置值如下:dubbo-clustersrcmainesourcesMETA-INFdubbointernalcom.alibaba.dubbo.rpc.cluster.LoadBalance
random
random=com.alibaba.dubbo.rpc.cluster.loadbalance.RandomLoadBalance
roundrobin
roundrobin=com.alibaba.dubbo.rpc.cluster.loadbalance.RoundRobinLoadBalance
leastactive
leastactive=com.alibaba.dubbo.rpc.cluster.loadbalance.LeastActiveLoadBalance
consistenthash
consistenthash=com.alibaba.dubbo.rpc.cluster.loadbalance.ConsistentHashLoadBalance
其配置使用,通常一般在< dubbo:consumer/>、< dubbo:service />、< dubbo:reference />的loadbalance属性配置,通常< dubbo:consumer/>这个属性指定消费端的默认策略,某些服务需要指定特殊负载均衡策略的话,一般通过< dubbo:reference />来指定。
如果各位对其源码实现比较有兴趣的话,可以看接下来的部分,源码分析各种负载算法的具体实现细节。
1、源码分析ConsistentHashLoadBalance(一致性Hash算法)
一致Hash算法,通常用在缓存领域,主要解决的问题是当数据节点数量发送变化后,尽量减少数据的迁移,在负责算法领域,个人不建议使用。Dubbo一致性Hash算法的实现逻辑主要分布在ConsistentHashLoadBalance$ConsistentHashSelector中。
1.1 核心属性与构造方法
private final TreeMap<long, invoker<t>> virtualInvokers;private final int replicaNumber;
private final int identityHashCode;
private final int[] argumentIndex;
TreeMap< Long, Invoker< T>> virtualInvokers:虚拟节点,使用TreeMap实现Hash环,将Invoker分布在环上。
int replicaNumber:虚拟节点个数。
int identityHashCode:HashCode。
int[] argumentIndex:需要参与hash的参数索引,,argumentIndex = [0,1]表示服务方法的第一个,第二个参数参与hashcode计算。
接下来看一下其构造方法:
public ConsistentHashSelector(List<invoker<t>> invokers, String methodName, int identityHashCode) { this.virtualInvokers = new TreeMap<long, invoker<t>>();
this.identityHashCode = System.identityHashCode(invokers); // @1
URL url = invokers.get(0).getUrl();
this.replicaNumber = url.getMethodParameter(methodName, "hash.nodes", 160); // @2
String[] index = Constants.COMMA_SPLIT_PATTERN.split(url.getMethodParameter(methodName, "hash.arguments", "0")); // @3 start
argumentIndex = new int[index.length];
for (int i = 0; i < index.length; i ++) {
argumentIndex[i] = Integer.parseInt(index[i]);
} // @3 end
for (Invoker<t> invoker : invokers) { // @4
for (int i = 0; i < replicaNumber / 4; i++) {
byte[] digest = md5(invoker.getUrl().toFullString() + i);
for (int h = 0; h < 4; h++) {
long m = hash(digest, h);
virtualInvokers.put(m, invoker);
}
}
} // @4 end
}
代码@1:根据所有的调用者生成一个HashCode,用该HashCode值来判断服务提供者是否发生了变化。
代码@2:获取服务提供者< dubbo:method/>标签的hash.nodes属性,如果为空,默认为160,表示一致性hash算法中虚拟节点数量。其配置方式如下:
< dubbo:method ... >
< dubbo:parameter key="hash.nodes" value="160" />
< dubbo:parameter key="hash.arguments" value="0,1" />
< /dubbo:method/>
代码@3:一致性Hash算法,在dubbo中,相同的服务调用参数走固定的节点,hash.arguments表示哪些参数参与hashcode,默认值“0”,表示第一个参数。
代码@4:为每一个Invoker创建replicaNumber 个虚拟节点,每一个节点的Hashcode不同。同一个Invoker不同hashcode的创建逻辑为:
invoker.getUrl().toFullString() + i (0-39)的值,对其md5,然后用该值+h(0-3)的值取hash。一致性hash实现的一个关键是如果将一个Invoker创建的replicaNumber 个虚拟节点(hashcode)能够均匀分布在Hash环上,Dubbo给出的实现如下,由于能力有限,目前并未真正理解如下方法的实现依据:
private long hash(byte[] digest, int number) { return (((long) (digest[3 + number * 4] & 0xFF) << 24)
| ((long) (digest[2 + number * 4] & 0xFF) << 16)
| ((long) (digest[1 + number * 4] & 0xFF) << 8)
| (digest[number * 4] & 0xFF))
& 0xFFFFFFFFL;
}
综上所述,构造函数主要完成一致性Hash算法Hash环的构建,利用了TreeMap的有序性来实现。
1.2 源码分析public Invoker< T> select(Invocation invocation):根据调用环境根据一致性Hash算法选择一个Invoker
public Invoker<t> select(Invocation invocation) { String key = toKey(invocation.getArguments()); // @1
byte[] digest = md5(key); // @2
return selectForKey(hash(digest, 0)); // @3
}
代码@1:根据调用参数,并根据hash.arguments配置值,获取指定的位置的参数值,追加一起返回。
代码@2:对Key进行md5签名。
代码@3:根据key进行选择调用者。
1.2.1 ConsistentHashLoadBalance$ConsistentHashSelector#selectForKey
private Invoker<t> selectForKey(long hash) { Map.Entry<long, invoker<t>> entry = virtualInvokers.tailMap(hash, true).firstEntry(); // @1
if (entry == null) { // @2
entry = virtualInvokers.firstEntry();
}
return entry.getValue(); // @3
}
代码@1,对虚拟节点,从virtualInvokers中选取一个子集,subMap(hash,ture,lastKey,true),其实就是实现根据待查找hashcode(key)顺时针,选中大于等于指定key的第一个key。
代码@2,如果未找到,则返回virtualInvokers第一个key。
代码@3:根据key返回指定的Invoker即可。
这里实现,应该可以不使用tailMap,代码修改如下:
private Invoker<t> selectForKey(long hash) { Map.Entry<long, invoker<t>> entry = virtualInvokers.ceilingEntry(hash);
if(entry == null ) {
entry = virtualInvokers.firstEntry();
}
return entry.getValue();
}
如果想要了解TreeMap关于这一块的特性(tailMap、ceillingEntry、headMap)等API的详细解释,可以查看我的另外一篇博文:https://blog.csdn.net/prestigeding/article/details/80821576
2、源码分析RandomLoadBalance实现细节(随机从调用者列表中选择一个Invoker)
2.1 Dubbo预热机制(权重)
由于roundrobin(加权轮询)、random(加权随机)、leastactive(最小活跃连接数)都与权重有关系,在介绍这两种负载均衡算法之前,我们首先看一下Dubbo关于权重的获取逻辑,代码见AbstractLoadBalance#getWeigh方法:
protected int getWeight(Invoker<!--?--> invoker, Invocation invocation) { int weight = invoker.getUrl().getMethodParameter(invocation.getMethodName(), Constants.WEIGHT_KEY, Constants.DEFAULT_WEIGHT); // @1
if (weight > 0) {
long timestamp = invoker.getUrl().getParameter(Constants.REMOTE_TIMESTAMP_KEY, 0L); // @2
if (timestamp > 0L) {
int uptime = (int) (System.currentTimeMillis() - timestamp);
int warmup = invoker.getUrl().getParameter(Constants.WARMUP_KEY, Constants.DEFAULT_WARMUP); // @3
if (uptime > 0 && uptime < warmup) {
weight = calculateWarmupWeight(uptime, warmup, weight); // @4
}
}
}
return weight;
}
代码@1:首先获取服务提供者的权重(weight)。
代码@2:获取服务提供者的启动时间,在服务提供者启动时,会将启动时间戳存储在服务提供者的URL中,在服务发现(RegistryDirecotry)服务发现时,会将服务提供者的时间戳KEY,换成REMOTE_TIMESTAMP_KEY,避免与服务消费者的启动时间戳冲突。
代码@3:获取服务提供者是否开启预热机制,通过服务提供者< dubbo:service warmup=""/>参数来设置,如果未设置,去默认值10 * 60 * 1000(10分钟)。
代码@4:如果服务提供者启动时间小于预热时间(预热期间),需要根据启动时间,来计算预热期间服务提供者的权重。
AbstractLoadBalance#calculateWarmupWeight
static int calculateWarmupWeight(int uptime, int warmup, int weight) { // @1 int ww = (int) ((float) uptime / ((float) warmup / (float) weight));
return ww < 1 ? 1 : (ww > weight ? weight : ww);
}
代码@1:参数说明,uptime:服务提供者启动时间;warmup:设置的预热时间;weight:服务提供者的权重,该方法在uptime < warmup时被调用
该方法的实现,就是在预热期间,根据启动时间,动态返回该服务提供者的权重,并且启动时间越长,返回的权重越接近weight,启动时间超过预热时间,则直接返回weight。
该方法单元测试:
其输出结果:
2.2 RandomLoadBalance 加权随机算法实现分析
protected <t> Invoker<t> doSelect(List<invoker<t>> invokers, URL url, Invocation invocation) { int length = invokers.size(); // Number of invokers
int totalWeight = 0; // The sum of weights // @1 start
boolean sameWeight = true; // Every invoker has the same weight?
for (int i = 0; i < length; i++) {
int weight = getWeight(invokers.get(i), invocation);
totalWeight += weight; // Sum
if (sameWeight && i > 0
&& weight != getWeight(invokers.get(i - 1), invocation)) {
sameWeight = false;
}
} // @1 end
if (totalWeight > 0 && !sameWeight) { // @2
// If (not every invoker has the same weight & at least one invoker"s weight>0), select randomly based on totalWeight.
int offset = random.nextInt(totalWeight);
// Return a invoker based on the random value.
for (int i = 0; i < length; i++) {
offset -= getWeight(invokers.get(i), invocation);
if (offset < 0) {
return invokers.get(i);
}
}
}
// If all invokers have the same weight value or totalWeight=0, return evenly.
return invokers.get(random.nextInt(length)); // @3
}
代码@1:首先求所有服务提供者的总权重,并判断每个服务提供者的权重是否相同。
代码@2:如果提供者之间的权重不相同,则产生一个随机数(0-totalWeight),视为offset,然后依次用offset减去服务提供者的权重,如果减去(offset - provider.weight < 0),则该invoker命中。
代码@3:如果服务提供者的权重相同,则随机产生[0-invoker.size)即可。
2.3 RoundRobinLoadBalance 加权轮询算法分析
加权轮询算法的核心算法是按权重轮询,一个基本点是应该是一个当前序号与服务提供者数量取模,需要结合权重。Dubbo使用如下数据结构存储当前序号:
private final ConcurrentMap<string, atomicpositiveinteger> sequences = new ConcurrentHashMap<string, atomicpositiveinteger>();键值:serviceKey(<dubbo:service interface="" />+ methodname),每个方法采用不同的计数器。RoundRobinLoadBalance #doSelect
protected <t> Invoker<t> doSelect(List<invoker<t>> invokers, URL url, Invocation invocation) {
String key = invokers.get(0).getUrl().getServiceKey() + "." + invocation.getMethodName(); // @1
int length = invokers.size(); // Number of invokers
int maxWeight = 0; // The maximum weight
int minWeight = Integer.MAX_VALUE; // The minimum weight
final LinkedHashMap<invoker<t>, IntegerWrapper> invokerToWeightMap = new LinkedHashMap<invoker<t>, IntegerWrapper>(); // @2 start
int weightSum = 0;
for (int i = 0; i < length; i++) {
int weight = getWeight(invokers.get(i), invocation);
maxWeight = Math.max(maxWeight, weight); // Choose the maximum weight
minWeight = Math.min(minWeight, weight); // Choose the minimum weight
if (weight > 0) {
invokerToWeightMap.put(invokers.get(i), new IntegerWrapper(weight));
weightSum += weight;
}
} // @2 end
AtomicPositiveInteger sequence = sequences.get(key);
if (sequence == null) {
sequences.putIfAbsent(key, new AtomicPositiveInteger());
sequence = sequences.get(key);
}
int currentSequence = sequence.getAndIncrement(); // @3
if (maxWeight > 0 && minWeight < maxWeight) { // @4
int mod = currentSequence % weightSum;
for (int i = 0; i < maxWeight; i++) {
for (Map.Entry<invoker<t>, IntegerWrapper> each : invokerToWeightMap.entrySet()) {
final Invoker<t> k = each.getKey();
final IntegerWrapper v = each.getValue();
if (mod == 0 && v.getValue() > 0) {
return k;
}
if (v.getValue() > 0) {
v.decrement();
mod--;
}
}
}
}
// Round robin
return invokers.get(currentSequence % length); // @5
}
代码@1:构建ConcurrentMap< String, AtomicPositiveInteger> sequences中的key,以interface+methodname为键,里面存储的是当前序号(轮询)。
代码@2:构建LinkedHashMap< Invoker< T>, IntegerWrapper>存储结构,通过遍历所有Invoker,构建每个Invoker的权重,与此同时算出总权重,并且得出所有服务提供者权重是否相同。
代码@3:获取当前的轮询序号,用于取模。
代码@4:如果服务提供者之间的权重有差别,需要按权重轮询,实现方式是:
1)用当前轮询序号与服务提供者总权重取模,余数为mod。
2)然后从0循环直到最大权重,针对每一次循环,按同一顺序遍历所有服务提供者,如果mod等于0并且对应的Invoker的权重计算器大于0,则选择该服务提供者;否则,mod--,invoker对应的权重减一,权重是临时比那里LinkedHashMap< Invoker< T>, IntegerWrapper>。由于外层循环的次数为所有服务提供者的最大权重,内层循环当mod等于0时,肯定会有一个服务提供者的权重计数器大于0,而返回对应的服务提供者。返回的服务提供者是第一个满足的服务提供者,后续的服务提供者在下一次就会有机会, 因为下一次mod会增大1,后续的服务提供者通过轮询会被选择,选择的机会,取决于权重的大小。
代码@5:如果各服务提供者权重相同,则直接对服务提供者取模即可,轮询后递增。
2.4 LeastActiveLoadBalance 最少活跃连接数负载均衡算法分析
最小活跃连接数,其核心实现就是,首先找到服务提供者当前最小的活跃连接数,如果一个服务提供者的服务连接数比其他的都要小,则选择这个活跃连接数最小的服务提供者发起调用,如果存在多个服务提供者的活跃连接数,并且是最小的,则在这些服务提供者之间选择加权随机算法选择一个服务提供者。
protected <t> Invoker<t> doSelect(List<invoker<t>> invokers, URL url, Invocation invocation) { int length = invokers.size(); // Number of invokers // @1 start
int leastActive = -1; // The least active value of all invokers
int leastCount = 0; // The number of invokers having the same least active value (leastActive)
int[] leastIndexs = new int[length]; // The index of invokers having the same least active value (leastActive)
int totalWeight = 0; // The sum of weights
int firstWeight = 0; // Initial value, used for comparision
boolean sameWeight = true; // Every invoker has the same weight value? // @1 end
for (int i = 0; i < length; i++) { // @2
Invoker<t> invoker = invokers.get(i);
int active = RpcStatus.getStatus(invoker.getUrl(), invocation.getMethodName()).getActive(); // Active number
int weight = invoker.getUrl().getMethodParameter(invocation.getMethodName(), Constants.WEIGHT_KEY, Constants.DEFAULT_WEIGHT); //
// Weight
if (leastActive == -1 || active < leastActive) { // Restart, when find a invoker having smaller least active value. // @3
leastActive = active; // Record the current least active value
leastCount = 1; // Reset leastCount, count again based on current leastCount
leastIndexs[0] = i; // Reset
totalWeight = weight; // Reset
firstWeight = weight; // Record the weight the first invoker
sameWeight = true; // Reset, every invoker has the same weight value?
} else if (active == leastActive) { // If current invoker"s active value equals with leaseActive, then accumulating. // @4
leastIndexs[leastCount++] = i; // Record index number of this invoker
totalWeight += weight; // Add this invoker"s weight to totalWeight.
// If every invoker has the same weight?
if (sameWeight && i > 0
&& weight != firstWeight) {
sameWeight = false;
}
}
}
// assert(leastCount > 0)
if (leastCount == 1) { // @5
// If we got exactly one invoker having the least active value, return this invoker directly.
return invokers.get(leastIndexs[0]);
}
if (!sameWeight && totalWeight > 0) { // @6
// If (not every invoker has the same weight & at least one invoker"s weight>0), select randomly based on totalWeight.
int offsetWeight = random.nextInt(totalWeight);
// Return a invoker based on the random value.
for (int i = 0; i < leastCount; i++) {
int leastIndex = leastIndexs[i];
offsetWeight -= getWeight(invokers.get(leastIndex), invocation);
if (offsetWeight <= 0)
return invokers.get(leastIndex);
}
}
// If all invokers have the same weight value or totalWeight=0, return evenly.
return invokers.get(leastIndexs[random.nextInt(leastCount)]);
}
代码@1:解释相关局部变量。
length :服务提供者数量。
leastActive :服务提供者的最小活跃连接数,初始化为-1。
leastCount :服务提供者中都是活跃连接数的个数,例如,3个服务提供者当前的活跃连接数分别为 100,102,100,则leastCount 为2。
leastIndexs:存放拥有活跃连接数的Invoker索引,例如上面100,102,100,则leastIndexs[0]=0, leastIndexs[1] = 2;
totalWeight:拥有最小活跃连接数的Invoker的总权重。
firstWeight :第一个最小活跃连接数的Invoker的权重。
sameWeight :拥有最小活跃连接数的Invoker权重是否相同。
代码@2:遍历所有的服务提供者,计算上述变量的值。
代码@3:如果leastActive (最小活跃连接数为-1,表示第一次遍历)或最新连接数大于当前遍历的Invoker的活跃连接数,需要reset如下值,重新计算:
leastActive = active; // Record the current least active value
leastCount = 1; // Reset leastCount, count again based on current leastCount
leastIndexs[0] = i; // Reset
totalWeight = weight; // Reset
firstWeight = weight; // Record the weight the first invoker
sameWeight = true; // Reset, every invoker has the same weight value?
代码@4:如果当前遍历的服务提供者的活跃数等于leastActive ,则将总权重想加,并在leastIndexs中记录服务提供者序号。
代码@5,如果最小活跃连接数的服务提供者数量只有一个,则直接返回该服务提供者。
代码@6,如果最小活跃连接数的服务提供者有多个,则使用加权随机算法选取服务提供者。
关于Dubbo的4种负载均衡算法的实现细节就分析到这里了。
作者介绍:丁威,《RocketMQ技术内幕》作者,RocketMQ 社区布道师,公众号:中间件兴趣圈 维护者,目前已陆续发表源码分析Java集合、Java 并发包(JUC)、Netty、Mycat、Dubbo、RocketMQ、Mybatis等源码专栏。可以点击链接:中间件知识星球,一起探讨高并发、分布式服务架构,交流源码。
</t></invoker<t></t></t></t></invoker<t></invoker<t></invoker<t></invoker<t></t></t></string,></string,></invoker<t></t></t></long,></t></long,></t></t></t></long,></invoker<t></long,></invoker<t></t></t>
以上是 源码分析Dubbo负载算法 的全部内容, 来源链接: utcz.com/z/512532.html