Redis设计与实现RDB持久化

上一篇:Redis设计与实现-数据库
众所周知Redis是一个内存数据库,因此一旦断电数据便会丢失,为了避免这种糟糕的体验,Redis提供了两种将数据写到磁盘的持久化技术,分别是RDB和AOF。
先说说RDB的一些工作方式和实现原理:
触发方式
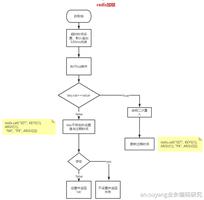
RDB有SAVE和BGSAVE两种手动触发方式,还有一种通过配置redis.conf中的save项,自动执行BGSAVE,它们最终都是调用rdbsave函数。
手动方式
RDB可以通过显示执行SAVE、BGSAVE命令完成数据持久化,两者的区别是:
SAVE命令是服务器进程调用RDB对应的函数,会阻塞请求
BGSAVE是服务器进程FORK一个子进程,只有FORK的时候会阻塞,真正RDB过程是不会阻塞请求的
因此生产环境中禁止使用SAVE命令,避免出现严重生产事故。
另外:
BGSAVE 的RDB操作在执行期间,会拒绝其他的SAVE BGSAVE命令,会延迟BGREWRITEAOF命令
反过来,如果BGREWRITEAOF执行期间,会拒绝其他所有的命令
自动方式
除手动触发以外,还可以通过由服务器根据扫描redis.conf中配置的rdb持久化条件完成数据持久化。比如:
# Redis 默认配置内容:save 900 1
save 300 10
save 60 10000
默认Redis是开启了自动触发BGSAVE的,但是可以通过如下方式关闭:
注释掉所有的save配置项
或者配置save ""
实现原理
先看RedisServer的定义
typedef struct redisServer{//其他属性
//数据库,一个数组,默认是16个
redisDb *db;
//上次save或者bgsave成功之后被修改的次数
long dirty;
//最后一次save时间戳
time_t lastsave;
//其他属性
}
结合数据结构定义可以想到Redis服务器进程会周期性(100毫秒)的调用某一个函数(serverCron),使用dirty和lastsave与配置项进行匹配,任何一个配置项被匹配成功就会执行BGSAVE命令
RDB函数rdbSave
首先打开一个临时文件, 调用 rdbSaveRio函数,将当前 Redis 的内存信息写入到这个临时文件中, 接着调用 fflush、fsync 和 fclose 接口将文件写入磁盘中, 使用 rename 将临时文件改名为 正式的 RDB 文件, 最后记录 dirty 和 lastsave等状态信息。这些状态信息在 serverCron时会使用到
RDB文件结构
databases:数据库,里面是有值的所有数据库,比如SELECTDB 0,SELECTDB1
pairs:键值对,分为带过期时间与不带过期时间的,结构有所不同
Type:分别对应5种数据类型
key:键
value:值,因为不同数据类型的数据结构不一样,因此存储方式也不会相同。就好比压缩列表是好几种数据类型的底层数据结构实现之一,具体在压缩列表中的存放方式都有自己的规则。
该文件结构有点过时了,新的长这样子,摘抄自:[Redis RDB 持久化详解]
新文件结构写入大致步骤:
先写入 REDIS 魔法值,然后是 RDB 文件的版本( rdb_version ),额外辅助信息 ( aux )。辅助信息中包含了 Redis 的版本,内存占用和复制库( repl-id )和偏移量( repl-offset )等。
然后 rdbSaveRio 会遍历当前 Redis 的所有数据库,将数据库的信息依次写入。先写入 RDB_OPCODE_SELECTDB识别码和数据库编号,接着写入RDB_OPCODE_RESIZEDB识别码和数据库键值数量和待失效键值数量,最后会遍历所有的键值,依次写入。
在写入键值时,当该键值有失效时间时,会先写入RDB_OPCODE_EXPIRETIME_MS识别码和失效时间,然后写入键值类型的识别码,最后再写入键和值。
写完数据库信息后,还会把 Lua 相关的信息写入,最后再写入 RDB_OPCODE_EOF结束符识别码和校验值
Redis启动时恢复数据流程
服务器在启动时候会检查AOF持久化是否开启了,如果开启了,则使用AOF恢复数据,否则使用RDB恢复数据。。。。通常两种方式都开启,确保万无一失
以上是 Redis设计与实现RDB持久化 的全部内容, 来源链接: utcz.com/z/512377.html