面试【JAVA基础】多线程

本次整理的内容如下:
1、进程与线程的区别
进程是一个可执行的程序,是系统资源分配的基本单位;线程是进程内相对独立的可执行单元,是操作系统进行任务调度的基本单位。
2、进程间的通信方式
2.1、操作系统内核缓冲区
由于每个进程都有独立的内存空间,进程之间的数据交换需要通过操作系统内核。需要在操作系统内核中开辟一块缓冲区,进程 A 将需要将数据拷贝到缓冲区中,进程 B 从缓冲区中读取数据。因为共享内存没有互斥访问的功能,需配合信号量进行互斥访问。
2.2、管道
管道的实现方式:
- 父进程创建管道,得到两个描述文件指向管道的两端。
- 父进程 fork 出子进程,子进程也拥有两个描述文件,指向同一个管道的两端。
- 父进程关闭读端(fd(0)),子进程关闭写端(fd(1))。父进程往管道里面写,子进程从管道里面读。
管道的特点:
只允许具有血缘关系的进程间通讯,只允许单向通讯,进程在管道在,进程消失管道消失。管道内部通过环形队列实现。
有名管道(命名管道):
通过文件的方式实现进程间的通信。允许无血缘关系的进程间的通信
2.3、消息队列
由消息组成的链表,存在系统内核中。克服了信号量传递的信息少,管道只能承载无格式的字符流及缓冲区的大小受限等特点。通过消息类型区分消息。
2.4、信号量
本质是一个计数器,不以传送数据为目的,主要用来保护共享资源,使得资源在一个时刻只有一个进程独享。
2.5、套接字
可用于不同机器间进程的通信。
套接字包括 3 个属性:域、类型、 协议。
- 域包括 ip 端口
- 类型指的是两种通信机制:流(stream)和数据报(datagram)
- 协议指 TCP/UDP 底层传输协议
创建 socket 通过 bind 命名绑定端口,listen 创建队列保存未处理的客户端请求,accept 等待客户端的连接,connect 服务端连接客户端 socket,close 关闭服务端客户端的连接。
stream 和 datagram 的区别:
stream 能提供有序的、可靠的、双向的、基于连接的字节流(TCP),会有拆包粘包问题。
datagram 是无连接、不可靠、使用固定大小的缓冲区的数据报服务(UDP),因为基于数据报,且有固定的大小,所以不会有拆包粘包问题。
详细请参考:进程间的五种通信方式介绍
3、线程间的通信方式
共享内存:
Java 采用的就是共享内存,内存共享方式必须通过锁或者 CAS 技术来获取或者修改共享的变量,看起来比较简单,但是锁的使用难度比较大,业务复杂的话还有可能发生死锁。
消息传递:
Actor 模型即是一个异步的、非阻塞的消息传递机制。Akka 是对于 Java 的 Actor 模型库,用于构建高并发、分布式、可容错、事件驱动的基于 JVM 的应用。消息传递方式就是显示的通过发送消息来进行线程间通信,对于大型复杂的系统,可能优势更足。
详细请参考:Java 内存模型分析
4、多线程的优缺点
优点:
充分利用 cpu 的资源,提高 cpu 的使用率,使程序的运行效率提高。
缺点:
有大量的线程会影响性能,操作系统会在线程之间切换,会增加内存的开销。可能会产生死锁、存在线程之间的并发问题。
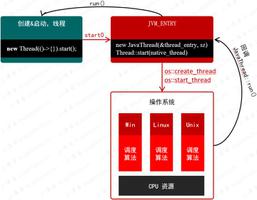
5、创建线程的方法
- 集成 Thread 类,重写 run 方法,利用 start 启动线程。
- 实现 Runable 接口创建线程,重写 run 方法,通过 new Thread 方式创建线程。
- 通过 callable 和 futuretask 创建线程,实现 callable 接口,重写 call 方法,使用 future 对象包装 callable 实例,通过 new Thread 方式创建线程。
- 通过线程池创建线程。
6、runable 和 callable 区别
- runable 是重写 run 方法,callable 重写 call 方法。
- runable 没有返回值,callable 有返回值。
- callable 中的 call 方法可以抛出异常,runable 中的 run 方法不能向外界抛出异常。
- 加入线程池运行 runable 使用 execute 运行,callable 使用 submit 方法。
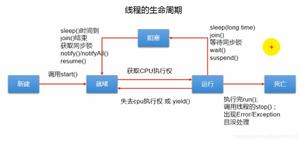
7、sleep 和 wait 区别
- wait 只能在 synchronized 块中调用,属于对象级别的方法,sleep 不需要,属于 Thread 的方法。
- 调用 wait 方法时候会释放锁,sleep 不会释放锁。
- wait 超时之后线程进入就绪状态,等待获取 cpu 继续执行。
8、yield 和 join 区别
- yield 释放 cpu 资源,让线程进入就绪状态,属于 Thread 的静态方法,不会释放锁,只能使同优先级或更高优先级的线程有执行的机会。
- join 等待调用 join 方法的线程执行完成之后再继续执行。join 会释放锁和 cpu 的资源,底层是通过 wait 方法实现的。
9、死锁的产生条件
- 互斥条件。
- 请求与保持条件。
- 不可剥夺条件。
- 循环等待条件。
详细请参考:并发编程挑战:死锁与上下文切换
10、如何解决死锁
- 破坏请求与保持条件
静态分配,每个线程开始前就获取需要的所有资源。
动态分配,每个线程请求获取资源时本身不占有资源。
- 破坏不可剥夺条件
当一个线程不能获取所有的资源时,进入等待状态,其已经获取的资源被隐式释放,重新加入到系统的资源列表中,可被其他线程使用。
- 死锁检测:银行家算法
11、threadLocal 的实现
- ThreadLocal 用于提供线程局部变量在多线程环境下可以保证各个线程里面的变量独立于其他线程里的变量。
- 底层使用 ThreadLocalMap 实现,每个线程都拥有自己的 ThreadLocalMap,内部为继承了 WeakReference 的 Entry 数组,包含的 Key 为 ThreadLocal,值为 Object。
详细请参考:【SharingObjects】ThreadLocal
12、threadLocal 什么时候会发生内存泄漏
java.lang.ThreadLocal.ThreadLocalMap.Entry:
static class Entry extends WeakReference<ThreadLocal<?>> { /** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
//重点!!!!!
super(k);
value = v;
}
}
因为 ThreadLocalMap 中的 key 是弱引用,而 key 指向的对象是 threadLocal,一旦把 threadLocal 实例置为 null 之后,没有任何强引用的对象指向 threadLocal 对象,因此 threadLocal 对象会被 Gc 回收,但与之关联的 value 却不能被回收,只有当前线程结束后,对应的 map value 才会被回收。如果当前线程没结束,可能会导致内存泄漏。
如线程池的场景,在线程中将 threadlocal 置为 null,但线程没被销毁且一直不被使用,就可能会导致内存泄漏
在调用 get、set、remove 方法时,会清除线程 map 中所有 key 为 null 的 value。所以在不使用 threadLocal 时调用 remove 移除对应的对象。
13、线程池
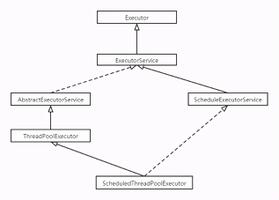
13.1、线程池类结构
ThreadPoolExecutor 继承关系图:
13.2、shutDown 和 shutDownNow 的区别、
shutDown 方法执行之后会变成 SHUTDOWN 状态,无法接受新任务,随后等待已提交的任务执行完成。
shutDownNow 方法执行之后变成 STOP 状态,无法接受新任务。并对执行中的线程执行 Thread.interrupt()方法。
- SHUTDOWN:不接受新任务提交,但是会继续处理等待队列中的任务。
- STOP:不接受新任务提交,不再处理等待队列中的任务,中断正在执行任务的线程。
13.3、线程池的参数
- CorePoolSize 核心线程数
- MaximumPoolSize 最大线程数,线程池允许创建的最大线程数
- keepAliveTime 空闲线程的存活时间
- wokeQueue 任务队列
- handler 饱和策略
- threadFactory 用于生成线程。
当任务来时,如果当前的线程数到达核心线程数,会将任务加入阻塞队列中,如果阻塞队列满了之后,会继续创建线程直到线程数量达到最大线程数,如果线程数量已经达到最大线程数量,且任务队列满了之后,会执行拒绝策略。
如果想让核心线程被回收,可以使用 allowCoreThreadTimeOut 参数,如果为 false(默认值),核心线程即使在空闲时也保持活动状态。如果 true,核心线程使用 keepAliveTime 来超时等待工作。
13.4、线程池的饱和策略
- CallerRunsPolicy:由提交任务的线程自己执行这个任。
- AbortPolicy (默认): 直接抛出 RejectExecutionException 异常。
- DisCardPolicy:不做处理,抛弃掉当前任务。
- DiscardOldestPolicy: 把队列队头的任务直接扔掉,提交当前任务进阻塞队列。
13.5、线程池分类
java.util.concurrent.Executors 类:
- newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
生成一个固定大小的线程池,此时核心线程数和最大线程数相等,keepAliveTime = 0 ,任务队列采取 LinkedBlockingQueue 无界队列(也可设置为有界队列)。
适用于为了满足资源管理需求,而需要限制当前线程数量的应用场景,比如负载比较重的服务器。
- newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
生成只有一个线程的线程池,核心线程数与最大线程数都是 1,keepAliveTime = 0,任务队列采取 LinkedBlockingQueue,适用于需要保证顺序地执行各个任务,并且在任意时间点不会有多个线程是活动的应用场景。
- newCachedThreadPool
public static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
核心线程数是 0,最大线程数是 int 最大值,keepaliveTime 为 60 秒,任务队列采取 SynchronousQueue,适用于执行很多的短期异步任务的小程序,或者是负载较轻的服务器。
- newScheduledThreadPool
public static ScheduledExecutorService newSingleThreadScheduledExecutor() { return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1));
}
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
定长的线程池,支持周期性任务,最大线程数是 int 最大值,超时时间为 0,任务队列使用 DelayedWorkQueue,适用于需要多个后台执行周期任务,同时为了满足资源管理需求而需要限制后台线程的数量的应用场景。
13.6、任务执行过程中出现异常会怎么样?
任务执行失败后,只会影响到当前执行任务的线程,对于整个线程池是没有影响的。
详细请参考:ThreadPoolExecutor 线程池任务执行失败的时候会怎样
13.7、线程池的底层实现
- 使用 hashSet 存储 worker
- 每个 woker 控制自己的状态
- 执行完任务之后循环获取任务队列中的任务
13.8、重启服务、如何优雅停机关闭线程池
kill -9 pid 操作系统内核级别强行杀死某个进程。
kill -15 pid 发送一个通知,告知应用主动关闭。
ApplicationContext 接受到通知之后,会执行 DisposableBean 中的 destroy 方法。
一般我们在 destroy 方法中做一些善后逻辑。
调用 shutdown 方法,进行关闭。
13.9、为什么使用线程池
- 降低资源消耗,减少创建销毁线程的成本。
- 提高响应速度。
- 提高线程的可管理性,线程的无限制的创建,消耗系统资源,降低系统的稳定性。
以上是 面试【JAVA基础】多线程 的全部内容, 来源链接: utcz.com/z/511747.html