shardingjdbc4.0使用方式

Sharding-jdbc 简介
Sharding-JDBC是ShardingSphere的第一个产品,也是ShardingSphere的前身。 它定位为轻量级Java框架,在Java的JDBC层提供的额外服务。它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
- 适用于任何基于JDBC的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
- 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer,PostgreSQL以及任何遵循SQL92标准的数据库。
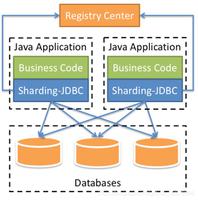
内部结构
使用流程
- 初始化流程
- 配置Configuration对象。
- 通过Factory对象将Configuration对象转化为Rule对象。
- 通过Factory对象将Rule对象与DataSource对象装配。
- Sharding-JDBC使用DataSource对象进行分库。
版本依赖
<dependency> <groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-core</artifactId>
<version>4.0.0-RC2</version>
</dependency>
场景使用demo
创建数据源方法
public static DataSource createDataSource() { DruidDataSource dataSource = new DruidDataSource();
dataSource.setDriverClassName("com.mysql.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://10.136.15.102:3306/otoc_weixin_user?useUnicode=true&characterEncoding=utf-8");
dataSource.setUsername("dptest");
dataSource.setPassword("111111");
return dataSource;
}
sharding自定义类
package com.szeastroc.gateway;import java.util.Collection;
import org.apache.commons.lang.StringUtils;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import com.szeastroc.common.utils.RouterUtils;
import lombok.extern.slf4j.Slf4j;
/**
* hash分片规则
* 适用于 =,>场景
* @author LiangHao
*
*/
@SuppressWarnings("rawtypes")
@Slf4j
public class HashShardingAlgorithm implements PreciseShardingAlgorithm{
/**
* 表数量
*/
private Integer tableNum;
public HashShardingAlgorithm(Integer tableNum) {
this.tableNum = tableNum;
}
@Override
public String doSharding(Collection availableTargetNames, PreciseShardingValue shardingValue) {
StringBuilder table = new StringBuilder();
table.append(availableTargetNames.iterator().next()).append("_");
String value = (String) shardingValue.getValue();
table.append(StringUtils.leftPad(String.valueOf(RouterUtils.getResourceCode(value) % tableNum), 3, "0"));
log.info("切片表名:{}",table);
return table.toString();
}
}
package com.szeastroc.gateway;import java.util.Arrays;
import java.util.Collection;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingValue;
import lombok.extern.slf4j.Slf4j;
/**
* 范围查询分片适用于between等范围语句
* @author LiangHao
*
*/
@SuppressWarnings("rawtypes")
@Slf4j
public class RangeShardingAlgoithm implements RangeShardingAlgorithm{
@Override
public Collection doSharding(Collection availableTargetNames, RangeShardingValue shardingValue) {
log.info("范围切片表名:{}",Arrays.asList("t_weixin_user_000","t_weixin_user_001"));
return Arrays.asList("t_weixin_user_000","t_weixin_user_001");
}
}
package com.szeastroc.gateway;import java.util.Arrays;
import java.util.Collection;
import org.apache.commons.lang.StringUtils;
import org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingValue;
import com.alibaba.fastjson.JSON;
import com.szeastroc.common.utils.RouterUtils;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class ComplexShardingAlgorithm implements ComplexKeysShardingAlgorithm{
private Integer tableNum;
private String[] shardingCloumns;
public ComplexShardingAlgorithm(Integer tableNum,String ...shardingCloumns) {
this.tableNum=tableNum;
this.shardingCloumns = shardingCloumns;
}
@Override
public Collection doSharding(Collection availableTargetNames, ComplexKeysShardingValue shardingValue) {
log.info("复合字段切片表名:{}",Arrays.asList("t_weixin_user_000","t_weixin_user_001"));
return Arrays.asList("t_weixin_user_000","t_weixin_user_001");
}
}
1.标准分片demo,适用于单字段分片=,>
public static void standardShardingTableDemo() throws SQLException { Map<String, DataSource> dataSourceMap = new HashMap<String, DataSource>();
dataSourceMap.put("ds0", createDataSource());
/**
* 配置表规则
*/
TableRuleConfiguration orderTableRuleConfig = new TableRuleConfiguration("t_weixin_user");
orderTableRuleConfig.setTableShardingStrategyConfig(
new StandardShardingStrategyConfiguration("openid", new HashShardingAlgorithm(10)));
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTableRuleConfigs().add(orderTableRuleConfig);
DataSource dataSource = ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig,
new Properties());
Connection connection = dataSource.getConnection();
PreparedStatement prepareStatement = connection.prepareStatement("select * from t_weixin_user where openid=?");
prepareStatement.setString(1, "2342");
prepareStatement.execute();
ResultSet result = prepareStatement.getResultSet();
if (result.next()) {
log.info("标准分片查询数据x_openid:{}", result.getString(1));
}
connection.close();
}
2.范围分片demo,适用于between语句
/** * 标准范围分片规则demo
*
* @throws SQLException
*/
public static void standardRangeShardingTableDemo() throws SQLException {
Map<String, DataSource> dataSourceMap = new HashMap<String, DataSource>();
dataSourceMap.put("ds0", createDataSource());
/**
* 配置表规则
*/
TableRuleConfiguration orderTableRuleConfig = new TableRuleConfiguration("t_weixin_user");
orderTableRuleConfig.setTableShardingStrategyConfig(new StandardShardingStrategyConfiguration("openid",
new HashShardingAlgorithm(10), new RangeShardingAlgoithm()));
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTableRuleConfigs().add(orderTableRuleConfig);
DataSource dataSource = ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig,
new Properties());
Connection connection = dataSource.getConnection();
PreparedStatement prepareStatement = connection
.prepareStatement("select * from t_weixin_user where openid between ? and ?");
prepareStatement.setString(1, "2342");
prepareStatement.setString(2, "2342");
prepareStatement.execute();
ResultSet result = prepareStatement.getResultSet();
if (result.next()) {
log.info("范围分片查询数据x_openid:{}", result.getString(1));
}
connection.close();
}
3.复合字段demo,适用于多个字段组合分片
/** * 复合字段规则demo
*
* @throws SQLException
*/
public static void complexShardingTableDemo() throws SQLException {
Map<String, DataSource> dataSourceMap = new HashMap<String, DataSource>();
dataSourceMap.put("ds0", createDataSource());
/**
* 配置表规则
*/
TableRuleConfiguration orderTableRuleConfig = new TableRuleConfiguration("t_weixin_user");
orderTableRuleConfig.setTableShardingStrategyConfig(new ComplexShardingStrategyConfiguration("openid,x_openid",
new ComplexShardingAlgorithm(10, "openid", "x_openid")));
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
shardingRuleConfig.getTableRuleConfigs().add(orderTableRuleConfig);
DataSource dataSource = ShardingDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig,
new Properties());
Connection connection = dataSource.getConnection();
PreparedStatement prepareStatement = connection
.prepareStatement("select * from t_weixin_user where openid=? and x_openid=?");
prepareStatement.setString(1, "2342");
prepareStatement.setString(2, "234");
prepareStatement.execute();
ResultSet result = prepareStatement.getResultSet();
if (result.next()) {
log.info("复合字段分片查询数据x_openid:{}", result.getString(1));
}
connection.close();
}
4.读写分离demo
/** * 读写分离
*
* @throws SQLException
*/
public static void masterSlaveDemo() throws SQLException {
Map<String, DataSource> dataSourceMap = new HashMap<String, DataSource>();
dataSourceMap.put("ds0", createDataSource());
dataSourceMap.put("ds1", createDataSource());
MasterSlaveRuleConfiguration masterSlaveRuleConfig = new MasterSlaveRuleConfiguration("读写分离", "ds1", Arrays.asList("ds1", "ds_slave1"));
DataSource dataSource = MasterSlaveDataSourceFactory.createDataSource(dataSourceMap, masterSlaveRuleConfig,
new Properties());
Connection connection = dataSource.getConnection();
PreparedStatement prepareStatement = connection
.prepareStatement("select * from t_weixin_user_000 where openid=? and x_openid=?");
prepareStatement.setString(1, "2342");
prepareStatement.setString(2, "234");
prepareStatement.execute();
ResultSet result = prepareStatement.getResultSet();
if (result.next()) {
log.info("读写分离查询数据x_openid:{}", result.getString(1));
}
connection.close();
}
以上是 shardingjdbc4.0使用方式 的全部内容, 来源链接: utcz.com/z/511596.html