Linux下利用coredump技术追查进程崩溃原因

原文链接:https://blog.csdn.net/u014585564/article/details/68063269
最近项目中出现了一个问题,服务器端程序会突然崩溃退出,我们采取了coredump技术以找到崩溃原因,即确定进程退出时正在执行的函数是哪个,其状态如何。
如果系统开启了coredump,准确的说如果当前的shell环境开启了coredump,当前shell环境下的程序崩溃退出时,会把当时进程的栈的内存状态写入core文件。使用gdb可以查看这个core文件中保存的栈的状态,gdb a.out core。(关于coredump的开启和对shell的理解,请参考本人另一篇博客《由coredump的开启引起的对shell的深入探究》,关于gdb请参考《GDB观察栈的内存布局》)
core文件生成的位置默认是可执行文件所在的位置,名称默认为core,其位置和名称是可以设置的,我的设置为:
mkdir /home/corefile
echo “/home/corefile/core-%e-%p-%t” > /proc/sys/kernel/core_pattern
这样,生成的core文件会放在/home/corefile目录下,core文件名会以core-%e-%p-%t的形式出现,其中%e表示可执行文件的名称,%p表示进程,%t表示生成core文件的时间(注意是unix时间)。
下面是一个可以导致coredump的例程:
划线处是会导致coredump处。执行后会在/home/corefile目录下产生以下文件:
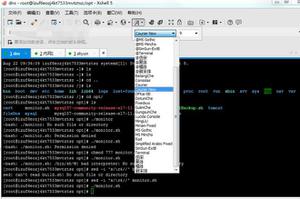
[root@localhostwin7]# ls /home/corefile/
a.out是可执行文件名,5082是PID,1490760381是产生该文件的unix时间。把a.out 和core文件放在一个目录下,使用命令:
gdb a.out core-a.out-5082-1490760381
进入gdb,然后使用backtrace命令,即可看进程退出时的栈的内存状态,如下所示:
可见,进程退出时,执行的最后一个函数是square函数。
————————————————
以上是 Linux下利用coredump技术追查进程崩溃原因 的全部内容, 来源链接: utcz.com/z/511564.html