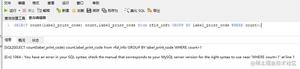
索引简记:B树B+树

数据库索引演进:
1、二叉树
如上,二叉树当时算法中的鼻祖了,O(N)的复杂度也使得他应用声名大噪,hash即使脱胎于此
那么为什么hash索引很少使用呢?一是因为极端情况下二叉树会退化为一个链表失去其二叉树的优势
2、由此,B-树, 注意是B树不是B减数,就诞生了,B树可以简单理解为平衡M岔树。如下示例为3路B树
再附一张带指针的:
B树:M个节点M+1个分叉,分为数据域和指针域,既存关键字,由存指针指向孩子节点,常用于文件系统索引。
B树是解决了退化的问题了,但是如上结构,在进行范围查询的时候,B树也是疲于奔命
3、由此,B+树诞生了,B+树是基于B树的拓展,示例如下:
再附一张带指针的
如此B+树就解决了范围查询的问题,且节点(空间)利用率也高过B树。常用于DB索引!
B树与B+树的区别:
- 在B+树中,具有n个关键字的节点只含有n棵子树,即每个关键字对应一个子树;而在B树中,具有n个关键字的节点只含有n+1棵子树。
- 在B+树中,每个结点(非根节点)关键字个数n的范围是m/2(向上取整)<=n<=m(根结点:1<=n<=m);在B树中,每个结点(非根节点)关键字个数n的范围是m/2(向上取整)-1<=n<=m-1(根结点:1<=n<=m-1)。
- 在B+树中,叶结点包含信息,所有非叶子结点仅起到索引作用,非叶结点中的每个索引项只含有对应子树的最大关键字和指向该子树的指针,不含有该关键字对应记录的存储地址。
- 在B+树中,叶结点包含了全部关键字,即在非叶结点中出现的关键字也会出现在叶节点中;而在B树中,叶结点包含的关键字和其他结点包含的关键字是不重复的。
参考文档:
https://www.cnblogs.com/xueqiuqiu/articles/8779029.html
https://segmentfault.com/a/1190000019927682?utm_source=tag-newest
https://my.oschina.net/u/4141148/blog/3071690
以上是 索引简记:B树B+树 的全部内容, 来源链接: utcz.com/z/511451.html