
shell正则表达式

Ps:本内容摘自鸟哥的私房菜
前言:正则表达式本质是一种格式化的“字符串”,由相应标准的程序执行。
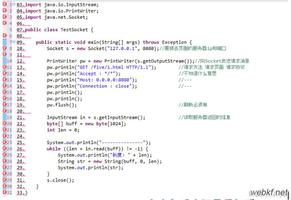
grep "mail" /etc/rc.d/*
grep [-acinv] "搜寻字符串" filename
参数说明:
-a: 将binary 档案以text档案的方式搜寻数据
-c: 计算找到"搜寻字符串"的次数
-i: 忽略大小写的不同,所以大小写视为相同
-n: 顺便输出行号
-v: 反向选择,亦即显示出没有"搜寻字符串"内容的那一行!
举例:不支持正规表示法的ls,若我们使用[ls -l *]代表的是任意档名的档案,[ls -l a*]代表的是以a为开头的任意档名的档案;但在正则表示法中,我们要找到含有以a为开头的档案,则必须搭配支持正则表示法的工具:ls | grep -n "^a.*"
sed [-nefr] [动作]
-n:使用安静(silent)模式。在一般sed的用法中,所有来自STDIN的数据一般都会被列出到屏幕上。
但如果加上 -n 参数后,则只有经过sed特殊处理的那一行(或者动作)才会被列出来。
-e:直接在指令列模式上进行sed的动作编辑;
-f:直接将sed的动作写在一个档案内,-f filename则可以执行filename内的sed动作;
-r:sed的动作支持的是延伸型正则表示法的语法。(预设是基础正则表达式)
动作说明:[n1[,n2]]function
n1,n2: 不见得会存在,一般代表[选择进行动作的行数]。
举例来说,如果我的动作在10到20行之间进行,则[10,20[动作行为]]。
function 包含如下:
a: 新增,a的后面可以接字符串,而这些字符串会在新的一行出现(目前的下一行)
c: 取代,c的后面可以接字符串,而这些字符串可以n1,n2之间的行!
d: 删除,因为是删除啊,所以d后面通常不接任何东西。
i: 插入,i的后面可以接字符串,而这些字符串会在新的一行出现(目前的上一行)
p: 打印,亦即将某个选择的数据印出。通常p会与参数sed -n 一起动作
s: 取代,可以直接进行取代的工作!通常这个s的动作可以搭配正规表示法!
例如: 1,20s/old/new/g
awk:倾向于一行当中分成数个【字段】来处理,适合处理小型的数据处理。
awk通常运作的模式是这样:awk "条件类型1{动作1} 条件类型2{动作2} ..." filename
awk是[以行为一次处理的单位],而[以字段为最小的处理单位]
awk的内置变量:
变量名称 代表意义
NF 每一行($0)拥有的字段总数
NR 目前awk所处理的是[第几行]数据
FS 目前的分隔字符,预设是空格键
diff [-bBi] from_file to_file
注意:from_file 或 to_file 可以 - 取代,代表 【standard input】之意
-b 忽略一行当中,仅有多个空白的差异
-B 忽略空白行的差异
-i 忽略大小写的不同
以上是 shell正则表达式 的全部内容, 来源链接: utcz.com/z/510609.html


![正则表达式中 [\s\S]* 什么意思 居然能匹配所有字符 [] 不是范围描述符吗?](/wp-content/uploads/thumbs/270159_thumbnail.jpg)

