ELK日志收集系统

1. ELK简介
在传统项目中,如果在生产环境中,有多台不同的服务器集群,如果生产环境需要通过日志定位项目的Bug的话,需要在每台节点上使用传统的命令方式查询,这样效率非常低下。因此我们需要集中化的管理日志,ELK则应运而生。ELK=ElasticSeach+Logstash+Kibana,本项目采用的是 ElasticSeach + Logstash + kafka + Kibana
2. 各个组件介绍
2.1 Logstash
Logstash 主要用于收集服务器日志,它是一个开源数据收集引擎,具有实时管道功能。Logstash 可以动态地将来自不同数据源的数据统一起来,并将数据标准化到您所选择的目的地。
Logstash 收集数据的过程主要分为以下三个部分:
- 输入:数据(包含但不限于日志)往往都是以不同的形式、格式存储在不同的系统中,而 Logstash 支持从多种数据源中收集数据(File、Syslog、MySQL、消息中间件等等)。
- 过滤器:实时解析和转换数据,识别已命名的字段以构建结构,并将它们转换成通用格式。
- 输出:Elasticsearch 并非存储的唯一选择,Logstash 提供很多输出选择。
2.2 Elasticsearch
Elasticsearch (ES)是一个分布式的 Restful 风格的搜索和数据分析引擎,它具有以下特点:
- 查询:允许执行和合并多种类型的搜索 — 结构化、非结构化、地理位置、度量指标 — 搜索方式随心而变。
- 分析:Elasticsearch 聚合让您能够从大处着眼,探索数据的趋势和模式。
- 速度:很快,可以做到亿万级的数据,毫秒级返回。
- 可扩展性:可以在笔记本电脑上运行,也可以在承载了 PB 级数据的成百上千台服务器上运行。
- 弹性:运行在一个分布式的环境中,从设计之初就考虑到了这一点。
- 灵活性:具备多个案例场景。支持数字、文本、地理位置、结构化、非结构化,所有的数据类型都欢迎。
2.3 Kibana
Kibana 可以使海量数据通俗易懂。它很简单,基于浏览器的界面便于您快速创建和分享动态数据仪表板来追踪 Elasticsearch 的实时数据变化。其搭建过程也十分简单,您可以分分钟完成 Kibana 的安装并开始探索 Elasticsearch 的索引数据 — 没有代码、不需要额外的基础设施。
对于以上三个组件在 《ELK 协议栈介绍及体系结构》 一文中有具体介绍,这里不再赘述。
在 ELK 中,三大组件的大概工作流程如下图所示,由 Logstash 从各个服务中采集日志并存放至 Elasticsearch 中,然后再由 Kiabana 从 Elasticsearch 中查询日志并展示给终端用户。
3.目前系统采用的架构图
加了kafka 是想做一个数据缓冲, 和后期日志的实时计算处理.
这种架构的好处:
- 这种架构适合于较大集群的解决方案,但由于Logstash中心节点和Elasticsearch的负荷会比较重,可将他们配置为集群模式,以分担负荷;
- 这种架构的优点在于引入了消息队列机制,均衡了网络传输,从而降低了网络闭塞尤其是丢失数据的可能性,但依然存在Logstash占用系统资源过多的问题
- filebeat 将收集到到日志, 按照不同的 topic(主题) 传递给 kafka 集群;
- kafka集群, 将消息传递给后续;
- logstash 根据不同的 topic 的消息进行过滤, 然后存储到es;
- kibana 从es 中读取消息;
4. ELK日志收集系统实战展示
ELK收集系统信息
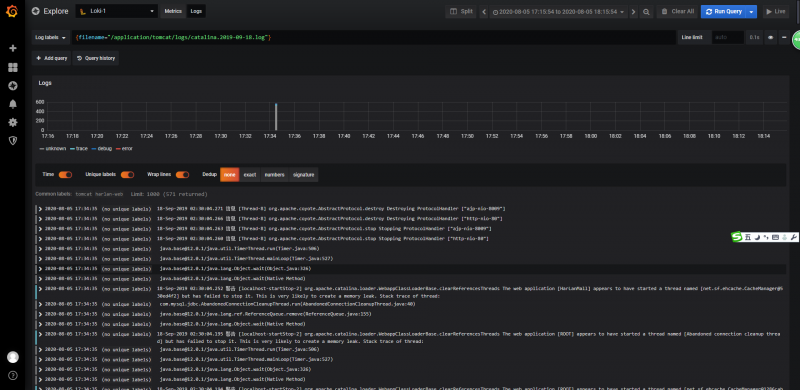
ELK收集日志信息
5. ELK 安装及配置
5.1 elk安装
ELK安装参考: https://www.elastic.co/cn/wha...
- 注意: ELK 各个组件需要注意版本号要一致;
kafka + zookeeper 安装略
5.2 ELK 配置
5.2.1 filebeat 收集日志系统
# 在不同的目录下, 收集不同的日志, 发送到不同的topic# 收集目录1下的日志, 发送到 topic1
-type:log
enabled:true
paths:
-/data/docker/cactus-web/logs/cactus.safe.xxx.cn/app/*.log
fields:
log_topics:logs_xxx_app
# 收集目录2下的日志, 发送到 topic2
-type:log
enabled:true
paths:
-/data/docker/cactus-web/logs/cactus.xxx.cn/web/*.log
fields:
log_topics:logs_xxx_web
#发送到Kafka集群的,对应的topic
output.kafka:
#Kafka集群的 ip:port
hosts: ["xx.20.xx.21:9092", "xx.220.xx.227:9092", "xx.xx.169.212:9092"]
# 自动把上面的topic进行区分
topic:'%{[fields][log_topics]}'
# 发送后的一些配置
partition.round_robin:
reachable_only:false
required_acks:1
compression:gzip
max_message_bytes:1000000
5.2.2 logstach 配置
# 消费kafka里面 对应的 topic 数据input {
kafka {
bootstrap_servers => "xx.xx.169.210:9092,xx.220.169.227:9092,xx.220.169.212:9092"
topics_pattern => "logs.*"
consumer_threads => 5
decorate_events => true
codec => "json"
}
}
# 过滤规则, 可以自己配置多个, 下面的配置是将filebeat自己产生的日志过滤掉
filter {
ruby {
code => "event.timestamp.time.localtime"
}
mutate {
remove_field => ["beat"]
}
}
# 输出到 对应的es里面
output {
elasticsearch {
hosts => ["xx.xx.169.210:9200", "xx.xx.169.227:9200", "xx.xx.169.212"]
index => "%{[@metadata][kafka][topic]}-%{+YYYY-MM-dd}"
codec => "json"
}
stdout { codec => rubydebug }
}
6. 通过kibana查看
以上是 ELK日志收集系统 的全部内容, 来源链接: utcz.com/z/510194.html