实战kudu集成impala

推荐阅读:
论主数据的重要性(正确理解元数据、数据元)
CDC+ETL实现数据集成方案
Java实现impala操作kudu
实战kudu集成impala
impala基本介绍
impala是基于hive的大数据分析查询引擎,直接使用hive的元数据库metadata,意味着impala元数据都存储在hive的metastore当中,并且impala兼容hive的绝大多数sql语法。所以需要安装impala的话,必须先安装hive,保证hive安装成功,并且还需要启动hive的metastore服务
impala是cloudera提供的一款高效率的sql查询工具,提供实时的查询效果,官方测试性能比hive快10到100倍,其sql查询比sparkSQL还要更加快速,号称是当前大数据领域最快的查询sql工具,
impala是参照谷歌的新三篇论文(Caffeine--网络搜索引擎、Pregel--分布式图计算、Dremel--交互式分析工具)当中的Dremel实现而来,其中旧三篇论文分别是(BigTable,GFS,MapReduce)分别对应我们即将学的HBase和已经学过的HDFS以及MapReduce。
impala是基于hive并使用内存进行计算,兼顾数据仓库,具有实时,批处理,多并发等优点
Kudu与Apache Impala (孵化)紧密集成,impala天然就支持兼容kudu,允许开发人员使用Impala的SQL语法从Kudu的tablets 插入,查询,更新和删除数据;
impala的优点
1、 impala比较快,非常快,特别快,因为所有的计算都可以放入内存当中进行完成,只要你内存足够大
2、 摈弃了MR的计算,改用C++来实现,有针对性的硬件优化
3、 具有数据仓库的特性,对hive的原有数据做数据分析
4、支持ODBC,jdbc远程访问
impala的缺点
1、基于内存计算,对内存依赖性较大
2、改用C++编写,意味着维护难度增大
3、基于hive,与hive共存亡,紧耦合
4、稳定性不如hive,不存在数据丢失的情况
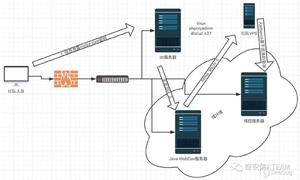
impala的架构以及查询计划
Impalad
基本是每个DataNode上都会启动一个Impalad进程,Impalad主要扮演两个角色:
Coordinator:
- 负责接收客户端发来的查询,解析查询,构建查询计划
- 把查询子任务分发给很多Executor,收集Executor返回的结果,组合后返回给客户端
- 对于客户端发送来的DDL,提交给Catalogd处理
Executor:
- 执行查询子任务,将子任务结果返回给Coordinator
Catalogd
- 整个集群只有一个Catalogd,负责所有元数据的更新和获取
StateStored
- 整个集群只有一个Statestored,作为集群的订阅中心,负责集群不同组件的信息同步
- 跟踪集群中的Impalad的健康状态及位置信息,由statestored进程表示,它通过创建多个线程来处理Impalad的注册订阅和与各Impalad保持心跳连接,各Impalad都会缓存一份State Store中的信息,当State Store离线后(Impalad发现State Store处于离线时,会进入recovery模式,反复注册,当State Store重新加入集群后,自动恢复正常,更新缓存数据)因为Impalad有State Store的缓存仍然可以工作,但会因为有些Impalad失效了,而已缓存数据无法更新,导致把执行计划分配给了失效的Impalad,导致查询失败。
使用impala操作kudu整合
1、需要先启动hdfs、hive、kudu、impala
2、使用impala的shell控制台
- 执行命令impala-shell
(1):使用该impala-shell命令启动Impala Shell 。默认情况下,impala-shell 尝试连接到localhost端口21000 上的Impala守护程序。要连接到其他主机,请使用该-i <host:port>选项。要自动连接到特定的Impala数据库,请使用该-d <database>选项。例如,如果您的所有Kudu表都位于数据库中的Impala中impala_kudu,则-d impala_kudu可以使用此数据库。
(2):要退出Impala Shell,请使用以下命令: quit;
创建kudu表
内部表由Impala管理,当您从Impala中删除时,数据和表确实被删除。当您使用Impala创建新表时,它通常是内部表。
- 使用impala创建内部表:
CREATE TABLE my_first_table(
id BIGINT,
name STRING,
PRIMARY KEY(id)
)
PARTITION BY HASH PARTITIONS
16STORED AS KUDU
TBLPROPERTIES (
'kudu.master_addresses' = 'node1:7051,node2:7051,node3:7051','kudu.table_name' = 'my_first_table');
在 CREATETABLE 语句中,必须首先列出构成主键的列。
- 此时创建的表是内部表,从impala删除表的时候,在底层存储的kudu也会删除表。
drop table if exists my_first_table;
外部表
外部表(创建者CREATE EXTERNAL TABLE)不受Impala管理,并且删除此表不会将表从其源位置(此处为Kudu)丢弃。相反,它只会去除Impala和Kudu之间的映射。这是Kudu提供的用于将现有表映射到Impala的语法。
使用java创建一个kudu表:
publicclass CreateTable {privatestatic ColumnSchema newColumn(String name, Type type, boolean iskey) {ColumnSchema.ColumnSchemaBuilder column
= newColumnSchema.ColumnSchemaBuilder(name, type);
column.key(iskey);
return column.build();}
publicstaticvoid main(String[] args) throws KuduException {// master地址
final String masteraddr = "node1,node2,node3";
// 创建kudu的数据库链接
KuduClient client = new
KuduClient.KuduClientBuilder(masteraddr).defaultSocketReadTimeoutMs(6000).build();
// 设置表的schema
List<ColumnSchema> columns = new LinkedList<ColumnSchema>();
columns.add(newColumn("CompanyId", Type.INT32, true));
columns.add(newColumn("WorkId", Type.INT32, false));
columns.add(newColumn("Name", Type.STRING, false));
columns.add(newColumn("Gender", Type.STRING, false));
columns.add(newColumn("Photo", Type.STRING, false));
Schema schema = new Schema(columns);
//创建表时提供的所有选项
CreateTableOptions options = new CreateTableOptions();
// 设置表的replica备份和分区规则
List<String> parcols = new LinkedList<String>();
parcols.add("CompanyId");
//设置表的备份数
options.setNumReplicas(1);
//设置range分区
options.setRangePartitionColumns(parcols);
//设置hash分区和数量
options.addHashPartitions(parcols, 3);
try {
client.createTable("person", schema, options);
} catch (KuduException e) {
e.printStackTrace();
}
client.close();
}
}
在kudu的页面上可以观察到如下信息:
在impala的命令行查看表:
当前在impala中并没有person这个表
使用impala创建外部表 , 将kudu的表映射到impala上:
在impala-shell执行
CREATE EXTERNAL TABLE `person` STORED AS KUDUTBLPROPERTIES(
'kudu.table_name' = 'person','kudu.master_addresses' = 'node1:7051,node2:7051,node3:7051')使用impala对kudu进行DML操作
将数据插入 Kudu 表
impala 允许使用标准 SQL 语句将数据插入 Kudu
插入单个值
创建表
CREATE TABLE my_first_table(
id BIGINT,
name STRING,
PRIMARY KEY(id)
)
PARTITION BY HASH PARTITIONS
16STORED AS KUDU;
此示例插入单个行
INSERT INTO my_first_table VALUES (50, "zhangsan");查看数据
select * from my_first_table使用单个语句插入三行
INSERT INTO my_first_table VALUES (1, "john"), (2, "jane"), (3, "jim");批量插入Batch Insert
从 Impala 和 Kudu 的角度来看,通常表现最好的方法通常是使用 Impala 中的 SELECT FROM 语句导入数据
INSERT INTO my_first_tableSELECT
* FROM temp1;更新数据
UPDATE my_first_table SET name="xiaowang"where id =1 ;删除数据
delete from my_first_table where id =2;更改表属性
开发人员可以通过更改表的属性来更改 Impala 与给定 Kudu 表相关的元数据。这些属性包括表名, Kudu 主地址列表,以及表是否由 Impala (内部)或外部管理。
Rename an Impala Mapping Table ( 重命名 Impala 映射表 )
ALTER TABLE PERSON RENAME TO person_temp;Rename the underlying Kudu table for an internal table ( 重新命名内部表的基础 Kudu 表 )
创建内部表:
CREATE TABLE kudu_student(
CompanyId INT,
WorkId INT,
Name STRING,
Gender STRING,
Photo STRING,
PRIMARY KEY(CompanyId)
)
PARTITION BY HASH PARTITIONS
16STORED AS KUDU
TBLPROPERTIES (
'kudu.master_addresses' = 'node1:7051,node2:7051,node3:7051','kudu.table_name' = 'student');
如果表是内部表,则可以通过更改 kudu.table_name 属性重命名底层的 Kudu 表
ALTER TABLE kudu_student SET TBLPROPERTIES('kudu.table_name' = 'new_student');Remapping an external table to a different Kudu table ( 将外部表重新映射到不同的 Kudu 表 )
如果用户在使用过程中发现其他应用程序重新命名了kudu表,那么此时的外部表需要重新映射到kudu上
创建一个外部表:
CREATE EXTERNAL TABLE external_tableSTORED AS KUDU
TBLPROPERTIES (
'kudu.master_addresses' = 'node1:7051,node2:7051,node3:7051','kudu.table_name' = 'person');
重新映射外部表,指向不同的kudu表:
ALTER TABLE external_tableSET TBLPROPERTIES(
'kudu.table_name' = 'hashTable')上面的操作是:将external_table映射的PERSON表重新指向hashTable表
Change the Kudu Master Address ( 更改 Kudu Master 地址 )
ALTER TABLE my_tableSET TBLPROPERTIES(
'kudu.master_addresses' = 'kudu-new-master.example.com:7051');Change an Internally-Managed Table to External ( 将内部管理的表更改为外部 )
ALTER TABLE my_table SET TBLPROPERTIES('EXTERNAL' = 'TRUE');以上是 实战kudu集成impala 的全部内容, 来源链接: utcz.com/z/509999.html