ZStack实践汇|ZStack+Docker支撑GPU业务实践

背景
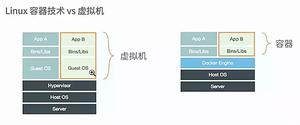
ZStack所聚焦的IaaS,作为云计算里的底座基石,能够更好的实现物理资源隔离,以及服务器等硬件资源的统一管理,为上层大数据、深度学习Tensorflow等业务提供了稳定可靠的基础环境。
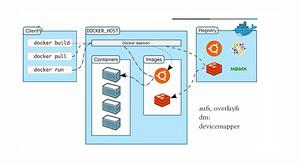
近年来,云计算发展探索出了有别于传统虚拟化、更贴近于业务的PaaS型服务,该类型依赖于docker实现,如K8S等典型的容器云,可以直接从镜像商店下载封装好业务软件的镜像,更加快捷地实现业务部署。
此外,GPU场景也是客户业务的典型场景,相比于CPU的运算特点,在数据分析、深度学习有着明显的优势。
ZStack是如何与容器结合,以IaaS+PaaS的组合拳,为上层业务提供支撑的呢?本篇文章带大家了解一下,如何在ZStack 上部署 centos7.6 虚拟机,在虚拟机里部署docker,以及如何使用nvidia-docker实现在容器里调用GPU的业务场景。
环境
虚机系统:Centos 7.6
虚机内核:Linux 172-18-47-133 3.10.0-957.el7.x86_64 #1 SMP Thu Nov 8 23:39:32 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
docker版本:docker-ce 19.03
nvidia-docker版本:nvidia-docker-1.0.11.x86_64
显卡:RTX6000
Cuda版本:10.1
显卡驱动:418
如下图所示:
Part 01
显卡驱动安装
1、下载对应版本的CUDA,并以此安装驱动。CUDA已经紧密结合了NVIDIA,以下驱动在centos、ubuntu上面均可执行,并自带绝大部分NVIDIA型号的显卡驱动,实用性非常强。
wget http://plan.zstack.io/storage/iso/nvidia/cuda_10.1.168_418.67_linux.run
chmod+x http://plan.zstack.io/storage/iso/nvidia/cuda_10.1.168_418.67_linux.run
GPU透传给虚拟机的操作步骤,详见在zstack.io官网可搜索到的《GPU实践手册》。
特别提醒:平台CPU模式一定要设置成passthrough!否则后续无法正常调用GPU做任何操作。
2、安装驱动,会自动禁止使用默认显卡驱动。特殊情况如需手动禁用,可使用如下操作:
echo “blacklist nouveau” >>/usr/lib/modprobe.d/dist-blacklist.conf
echo “options nouveau modeset=0” >>/usr/lib/modprobe.d/dist-blacklist.conf
mv /boot/initramfs-( u n a m e − r ) . i m g / b o o t / i n i t r a m f s − (uname -r).img /boot/initramfs-(uname−r).img/boot/initramfs−(uname -r).img.bak
dracut /boot/initramfs-$(uname -r).img $(uname -r)
reboot
lsmod|grep nouveau (为空则不加载默认显卡驱动)
3、./cuda_10.1.168_418.67_linux.run (安装时除了最后一项外,其他均需选择)
4、安装完成就表示驱动已安装完毕,可以执行nvidia-smi命令查看
5、驱动安装完毕后,建议采用CUDA自带的测试工具来测试,如果测试结果显示PASS,表示CUDA安装成功。
yum install gcc-c++
yum install cpp
cd /root/NVIDIA_CUDA-10.1_Samples/1_Utilities/bandwidthTest/
make
./bandwidthTest
Part 02
DOCKER-CE安装:
1、如果安装docker,需先卸载,再安装docker-ce
yum remove docker docker-common docker selinux docker-engine
2、配置docker-ce repo源:
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
3、列出可以安装的版本:
yum list docker-ce --showduplicates | sort -r
4、默认安装即可,当前为19.03版本:
yum install docker-ce (默认安装的是Docker version 19.03.13, build 4484c46d9d)
5、启动服务及开机自启配置:
systemctl start docker
systemctl enable docker
6、从镜像商店搜索一个带有GPU驱动的镜像:
docker search nvidia (镜像商店可以搜索带nvidia驱动的镜像,用第一个即可)
7、修改配置文件:
cat >> /etc/docker/daemon.json <<EOF
{
"runtimes": { "nvidia": {
"path": "/usr/bin/nvidia-container-runtime",
"runtimeArgs": []
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
}
EOF
Part 03
nividia-docker 安装
1、配置nvidia-docker相关源:
curl -s -L https://nvidia.github.io/nvidia-docker/centos7/x86_64/nvidia-docker.repo | sudo tee /etc/yum.repos.d/nvidia-docker.repo
2、搜索nvidia-docker包的版本:
yum search --showduplicates nvidia-docker
3、安装nvidia-docker:
yum install nvidia-docker-1.0.1-1.x86_64
4、启动服务,和配置开机自启动:
systemctl start nvidia-docker;
systemctl enable nvidia-docker;
systemctl status nvidia-docker
(需确保nvidia-docker状态一直正常运行,否则无正常使用)
5、检查相关依赖软件包是否已安装,如果缺失,可执行以下命令安装:
yum install libnvidia-container1
yum install nvidia-container-toolkit
yum install libnvidia-container-tools
6、重启一下docker服务:
systemctl restart docker
完成测试
nvidia-docker run --rm --gpus all nvidia/cuda:10.1
-base nvidia-smi (如下图所示,即为安装成功。此处必须加gpus all参数 如此才可调用GPU)
使用备注(躺坑日记)
a、如果需要向容器里传文件,参考一下方式传CUDA软件进容器,前面是本地文件,后面是容器id以及内部目录位置。反过来就是从容器里传文件出来。
docker cp /root/cuda_10.1.168_418.67_linux.run ffb6138f3299:/mnt/1.run
b、排除容器问题,一次性清理所有容器,则使用如下命令:
docker rm -f $(docker ps -aq)
c、重装驱动步骤:
yum remove nvidia-container-runtime
yum remove nvidia-container-toolkit
yum remove libnvidia-container-tools
yum remove nvidia-docker
./cuda_10.1.168_418.67_linux.run
yum install nvidia-docker-1.0.1-1.x86_64
systemctl start nvidia-docker; systemctl enable nvidia-docker; systemctl status nvidia-docker
yum install libnvidia-container1
yum install nvidia-container-toolkit
yum install libnvidia-container-tools
nvidia-docker run --rm --gpus all nvidia/cuda:10.1-base nvidia-smi 再跑就可以了
d、进入容器内部,执行操作使用如下命令:
docker exec -it nvidia/cuda:10.1-base /bin/bash
e、nvidia-docker 服务异常systemctl status nvidia-docker,报错error cuda all cuda-capable device are busy
此时问题为,平台CPU模式没有改成直通,修改后需要重启虚拟机才能生效。通过lscpu,查看并确认虚拟机CPU必须为物理CPU型号,而非QEMU型号CPU。
f、nvidia-docker 服务异常systemctl status nvidia-docker, 服务启动后自己停止,原因可能是GPU驱动没有装好。一定要经过CUDA自带脚本测试,测试通过才能认为显卡状态可用。
2、nvidia-docker run时报错:如果显示 no options [gpus] , --gpu all ,这个参数无效,报错原因是docker版本过低,建议使用19.03。低版本如17.03的docker-ce ,因为调用 GPU参数不同,所以可能被识别无效。
3、报错提示为缺少nvidia-container-runtime-hook,如下图,需要执行安装:yum install libnvidia-container1; yum install nvidia-container-toolkit-1.3.0-2.x86_64; yum install libnvidia-container-tools-1.3.0-1.x86_64
结语
历经一天时间,完成了ubuntu下和centos下的docker+ GPU +nvidia-docker的实践安装使用,中间简单的安装了一个Rancher PaaS平台,进行容器管理。
IaaS和PaaS都有着各自鲜明的优势,很多人总有这么一个疑问:到底该选择IaaS的资源隔离,来更好的管控硬件、迎合未来的混合云市场?还是选择PaaS,让应用更轻便、以释放人力到自己的核心业务上呢?最佳答案是:为何不全都要呢。ZStack IaaS结合PaaS实现IT改造,增加对IT的每一个细节掌控,共同撑起云计算的未来。
ZStack的愿景就是:“让每一家企业都拥有自己的云。”
以上是 ZStack实践汇|ZStack+Docker支撑GPU业务实践 的全部内容, 来源链接: utcz.com/z/509554.html