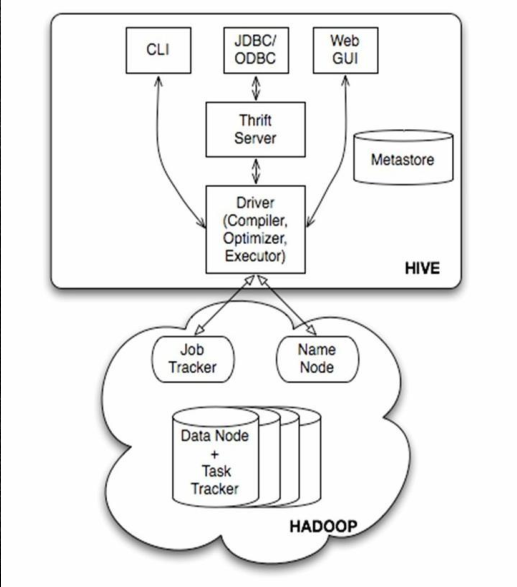
Hive查询

所谓·生活
就是一系列下定决心的努力
· 正 · 文 · 来 · 啦 ·
查询
*SELECT ... FROM语句
SELECT是SQL的射影算子,FROM标识了从哪个表查询
CREATE TABLE employees(
name STRING,
salary FLOAT,
subordinates ARRY<STRING>,
deductions MAP<STRING,FLOAT>
)
PARTITIONED BY (county string,state STRING);
1.比如某一个州有4名员工,查询语句如下:
eg: hive>SELECT name,salary FROM employees;
John Doe 100000.0
Mary Smith 80000.0
Todd Jones 70000.0
Bill King 60000.0
2.表加别名,在这个查询中不是很有用,但是如果有表链接操作,就很有用了
eg: hive>SELECT e.name,e.salary FROM employees e;
3.当查询的列是集合时,Hive会使用JSON用于输出,subordinates列为一个数组,输出如下:
eg: hive>SELECT name,subordinates FROM employees;
John Doe ["Mary Smith","Todd Jones"]
Mary Smith ["Bill King"]
Todd Jones [ ]
Bill King [ ]
注:集合的字符串元素是加引号的,而基本的STRING类型是不加的
4.deductions列是一个MAP,同样使用JSON格式来表达,输出如下:
eg: hive>SELECT name,deductions FROM employees;
John Doe {"Federal Taxes":0.2,"State Taxes":0.05,"Insurance":0.1}
Mary Smith {"Federal Taxes":0.2,"State Taxes":0.05,"Insurance":0.1}
Todd Jones {"Federal Taxes":0.15,"State Taxes":0.03,"Insurance":0.1}
Bill King {"Federal Taxes":0.15,"State Taxes":0.03,"Insurance":0.1}
*使用列值进行计算
例如,我们查询转换为大写的雇员姓名,雇员薪水,需要缴纳的联邦税收比例以及扣除税收后进行取整所得的税后薪资
eg: hive>SELECT upper(name),salary,deductions ["Federal Taxes"] ,
>round( salary* (1-deductions ["Federal Taxes"])) FROM employees;
John Doe 100000.0 0.2 80000
Mary Smith 80000.0 0.2 64000
Todd Jones 70000.0 0.15 59500
Bill King 60000.0 0.15 51000
*算数运算符
比如:INT 和 BIGINT,INT 转化为 BIGINT。INT 和 FLOAT,INT转化为 FLOA
算数运算符接受任意的数值类型,不过,如果类型不同,
那么范围较小的数据类型转换为范围广的类型
注:当进行算数运算时,需要注意数据溢出或数据下溢问题,
Hive底层遵循Java数据类型的规则,
因此当溢出或下溢发生时计算结果不会自动转换为更广泛的数据类型。
如果担心溢出和下溢,可以考虑使用范围更广的数据类型,
不过缺点是每个数据值会占更多额外内存。
*LIMIT语句
一般查询会返回多行数据,LIMIT子句用于限制返回的行数
eg: hive>SELECT upper(name),salary,deductions ["Federal Taxes"] ,
>round( salary* (1-deductions ["Federal Taxes"])) FROM employees
>LIMIT 2;
John Doe 100000.0 0.2 80000
Mary Smith 80000.0 0.2 64000
*列别名
前面的示例可以认为计算后返回一个新列,这个列对于 employees 来说是不存在的,通常给这个新列其一个别名,起别名用as
eg: hive>SELECT upper(name),salary,deductions ["Federal Taxes"] as fed_taxes,
>round( salary* (1-deductions ["Federal Taxes"])) as real_money FROM employees
>LIMIT 2;
John Doe 100000.0 0.2 80000
Mary Smith 80000.0 0.2 64000
*嵌套 SELECT 语句
eg: hive> SELECT e.name,e.salary,e.fed_taxes,e.real_money
> FROM(
> SELECT upper(name) as name,salary,deductions ["Federal Taxes"] as fed_taxes,
> round( salary* (1-deductions ["Federal Taxes"])) as real_money FROM employees
> )e
John Doe 100000.0 0.2 80000
Mary Smith 80000.0 0.2 64000
Todd Jones 70000.0 0.15 59500
Bill King 60000.0 0.15 51000
*CASE...WHEN...THEN句式
CASE...WHEN...THEN语句和if条件语句类似,用于处理单个列的结果
eg: hive>SELECT name,salary,
> CASE
> WHEN salary<70000 THEN 'low'
> WHEN salary>=80000 THEN 'high'
> ELSE 'middle'
> END AS rank FROM employees;
John Doe 100000.0 high
Mary Smith 80000.0 high
Todd Jones 70000.0 middle
Bill King 60000.0 low
*什么情况下Hive可以避免进行MapReduce
用 Hive 的应该都知道到多数的查询都会触发一个 MapReduce 任务(job)
但是本地模式查询不必使用MapReduce
eg: hive>SELECT * FROM employees;
如果属性hive.exec.mode.local.auto的值设为true的话,Hive还会尝试使用本地模式,否则,Hive 使用 MapReduce 来执行所有操作长按二维码关注我们吧
期待您的进步
▽
本文分享自微信公众号 - DataScience(DataScienceTeam)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
以上是 Hive查询 的全部内容, 来源链接: utcz.com/z/508842.html