Java集合--HashMap分析

HashMap在Java开发中有着非常重要的角色地位,每一个Java程序员都应该了解HashMap。
本文主要从源码角度来解析HashMap的设计思路,并且详细地阐述HashMap中的几个概念,并深入探讨HashMap的内部结构和实现细节,讨论HashMap的性能问题,并且在文中贯穿着一些关于HashMap常见问题的讨论。
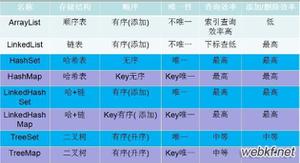
我们会从以下几个方面讲述HashMap的相关知识:Java集合框架、结构与效率(structure)、扩容机制(resize)、put与get、与HashTable、与ConcurrentHashMap、与HashSet、key值为null的存储、equal和hashcode方法、线程不安全
读完本文,你会了解到:
1. HashMap的设计思路和内部结构组成
2. HashMap中的一些概念: 什么是阀值?为什么会有阀值?什么是加载因子?它们有什么作用?
3. HashMap的性能问题以及使用事项
4. HashMap的源码实现解析
5. 为什么JDK建议我们重写Object.equals(Object obj)方法时,需要保证对象可以返回相同的hashcode值?
6. HashMap与HashTable、HashSet、CurrentHashMap之间的关系
Java集合框架
HashMap属于集合中的map,所以具有map的所有特性。
//第一种:(效率高)System.out.println("第一种方法:");
Iterator iter = map.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry entry = (Map.Entry)iter.next();
Object key = entry.getKey();
Object val = entry.getValue();
System.out.println("键:"+key+"<==>"+"值:"+val);
}
//第二种:(效率低)
System.out.println("第二种方法:");
Iterator it = map.keySet().iterator();
while (it.hasNext()) {
Object key = it.next();
Object val = map.get(key);
System.out.println("键:"+key+"<==>"+"值:"+val);
}
//对于keySet只是遍历了2次,一次是转为iterator,一次就从HashMap中取出key所对于的value。
//对于entrySet只是遍历了第一次,它把key和value都放到了entry中,所以快比keySet快些。
System.out.println("For-Each循环输出");
//For-Each循环
for (Map.Entry<String, Integer> entry:map.entrySet()) {
String key = entry.getKey().toString();
String val = entry.getValue().toString();
System.out.println("键:"+key+"<==>"+"值:"+val);
}
结构与效率(structure)
a )Map<K,V>是一种以键值对存储数据的容器,而HashMap则是借助了键值Key的hashcode值来组织存储,使得可以非常快速和高效地地根据键值key进行数据的存取。
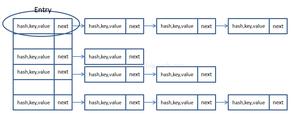
b )数组与链表结构,Map中的属性值数组:Node<K,V>[] table; Node中的属性值{hashCode,K,V,next}。
public class HashMap<K,V> extends AbstractMap<K,V>implements Map<K,V>, Cloneable, Serializable {
...
transient Node<K,V>[] table;
...
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
...}
}
c )对于每个对象而言,JVM都会为其生成一个hashcode值,会根据Key的hashcode值,以某种映射关系,决定应当将这对键值对Node<K,V>存储在HashMap中的什么位置上。
d )在HashMap内部,采用了数组+链表的形式来组织键值对Node<K,V>。
e )HashMap内部维护了一个Node<K,V>[] table 数组,当我们使用 new HashMap()创建一个HashMap时,Node[] table 的默认长度为16。Node[] table的长度又被称为这个HashMap的容量(capacity);
f )对于Node[] table的每一个元素而言,或为null,或为由若干个Node<K,V>组成的链表。HashMap中Node<K,V>的数目被称为HashMap的大小(size);
g )Entry[] table中的某一个元素及其对应的Entry<Key,Value>又被称为桶(bucket);
h )根据Key的hashCode,可以直接定位到存储这个Entry<Key,Value>的桶所在的位置,这个时间的复杂度为O(1);数组是连续的存储单元,空间代价是很大,效率高。
i )在桶中查找对应的Entry<Key,Value>对象节点,需要遍历这个桶的Entry<Key,Value>链表,时间复杂度为O(n);
j )加大数组,而减少链表的长度,来提高从HashMap中读取数据的速度。这是典型的拿空间换时间的策略。
其结构如下图所示:
扩容机制(resize)
a )阀值=容量*加载因子(0.75),可以构造方法给默认值。
b )HashMap的大小> HashMap的容量(即Node[] table的大小)*加载因子(经验值0.75),HashMap中的Entry[] table 的容量扩充为当前的一倍;然后重新将以前桶中的Entry<Key,Value>链表重新分配到各个桶中.
c )由于重现建立HashMap需要很大的时间,所以初始化HashMap给默认的容量和加载因子十分必要。
d )容量的大小应当是 2的N次幂;
e )当容量大小超过阀值时,容量扩充为当前的一倍;
f )这里容量扩充的操作可以分为以下几个步骤:
申请一个新的、大小为当前容量两倍的数组;
将旧数组的Entry[] table中的链表重新计算hash值,然后重新均匀地放置到新的扩充数组中;
释放旧的数组;
g )为了提高HashMap的性能:
在使用HashMap的过程中,你比较明确它要容纳多少Entry<Key,Value>,你应该在创建HashMap的时候直接指定它的容量;
如果你确定HashMap的使用的过程中,大小会非常大,那么你应该控制好 加载因子的大小,尽量将它设置得大些。避免Entry[] table过大,而利用率觉很低。
/*** Rehashes the contents of this map into a new array with a
* larger capacity. This method is called automatically when the
* number of keys in this map reaches its threshold.
*
* If current capacity is MAXIMUM_CAPACITY, this method does not
* resize the map, but sets threshold to Integer.MAX_VALUE.
* This has the effect of preventing future calls.
*
* @param newCapacity the new capacity, MUST be a power of two;
* must be greater than current capacity unless current
* capacity is MAXIMUM_CAPACITY (in which case value
* is irrelevant).
*/
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable);
table = newTable;
threshold = (int)(newCapacity * loadFactor);
}
/**
* Transfers all entries from current table to newTable.
*/
void transfer(Entry[] newTable) {
Entry[] src = table;
int newCapacity = newTable.length;
for (int j = 0; j < src.length; j++) {
Entry<K,V> e = src[j];
if (e != null) {
src[j] = null;
do {
Entry<K,V> next = e.next;
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
newTable[i] = e;
e = next;
} while (e != null);
}
}
}
put与get
HashMap的算法实现最重要的两个是put() 和get() 两个方法,下面我将分析这两个方法
public V put(K key, V value);public V get(Object key);
另外,HashMap支持Key值为null 的情况,我也将详细地讨论这个问题。
a )获取这个Key的hashcode值对容量取模%,根据此值确定应该将这一对键值对存放在Node<K,V>,即确定要存放桶的索引;
b )遍历所在桶中Node<K,V>[Index]链表,查找其中是否已经有了以hashcode值为Key存储的Node<K,V>对象.
c )若已存在,定位到对应的Node<K,V>,其中的Value值更新为新的Value值;返回旧值;
d )若不存在,则根据键值对Node<K,V> 创建一个新的Node<K,V>对象,然后添加到这个桶的Entry<Key,Value>链表的头部。
e )当前的HashMap的大小(即当前的HashMap的大小(即Node<K,V>节点的数目)是否超过了阀值,若超过了阀值(threshold),则增大HashMap的容量(即Node[] table 的大小),并且重新组织内部各个排列。节点的数目)是否超过了阀值,若超过了阀值(threshold),则增大HashMap的容量(即Node<K,V>[] table 的大小),并且重新组织内部各个Node<K,V>排列。
f )请读者注意这个判定条件,非常重要!!! 判断是否存在值,比较了equals方法与hashcode方法
g )为了提高性能,HashMap对Key的hashcode再加工,取Key的hashcode的高字节参与运算
/*** 将<Key,Value>键值对存到HashMap中,如果Key在HashMap中已经存在,那么最终返回被替换掉的Value值。
* Key 和Value允许为空
*/
public V put(K key, V value) {
//1.如果key为null,那么将此value放置到table[0],即第一个桶中
if (key == null)
return putForNullKey(value);
//2.重新计算hashcode值,
int hash = hash(key.hashCode());
//3.计算当前hashcode值应当被分配到哪一个桶中,获取桶的索引
int i = indexFor(hash, table.length);
//4.循环遍历该桶中的Entry列表
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//5. 查找Entry<Key,Value>链表中是否已经有了以Key值为Key存储的Entry<Key,Value>对象,
//已经存在,则将Value值覆盖到对应的Entry<Key,Value>对象节点上
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {//请读者注意这个判定条件,非常重要!!!
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//6不存在,则根据键值对<Key,Value> 创建一个新的Entry<Key,Value>对象,然后添加到这个桶的Entry<Key,Value>链表的头部。
addEntry(hash, key, value, i);
return null;
}
/**
* Key 为null,则将Entry<null,Value>放置到第一桶table[0]中
*/
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
/*** 根据特定的hashcode 重新计算hash值,
* 由于JVM生成的的hashcode的低字节(lower bits)冲突概率大,(JDK只是这么一说,至于为什么我也不清楚)
* 为了提高性能,HashMap对Key的hashcode再加工,取Key的hashcode的高字节参与运算
*/
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
/**
* 返回此hashcode应当分配到的桶的索引
*/
static int indexFor(int h, int length) {
return h & (length-1);
}
与HashTable
HashTable源代码分析
public synchronized V put(K key, V value) { //###### 注意这里1 // Make sure the value is not null
if (value == null) { //###### 注意这里 2
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry tab[] = table;
int hash = key.hashCode(); //###### 注意这里 3
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry e = tab[index]; e != null; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
V old = e.value;
e.value = value;
return old;
}
}
modCount++;
if (count >= threshold) {
// Rehash the table if the threshold is exceeded
rehash();
tab = table;
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
Entry e = tab[index];
tab[index] = new Entry(hash, key, value, e);
count++;
return null;
}
a) HashTable是线程安全的原因:public synchronized V put(K key, V value) {}
b) HashTable 的key值不能为空:if (value == null) { throw new NullPointerException(); }
c) HashTable 计算hash值比较简单:int hash = key.hashCode();
d) Hashtable和HashMap采用的hash/rehash算法都大概一样,所以性能不会有很大的差异。
与ConcurrentHashMap
a) ConcurrentHashMap采用了分段锁的设计,只有在同一个分段内才存在竞态关系,不同的分段锁之间没有锁竞争。
b) 在ConcurrentHashMap中,就是把Map分成了N个Segment,put和get的时候,都是现根据key.hashCode()算出放到哪个Segment中:Segment相当于HashTable
c) ConcurrentHashMap中默认是把segments初始化为长度为16的数组
与HashSet
hashset 源代码分析
public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable{
... private transient HashMap<E,Object> map;
private static final Object PRESENT = new Object();
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
public Iterator<E> iterator() {
return map.keySet().iterator();
}
public int size() {
return map.size();
}
...
}
a )对于 HashSet 而言,它是基于 HashMap 实现的,HashSet 底层采用 HashMap 来保存所有元素。
b )使用 HashMap的key 保存 HashSet 中所有元素 HashMap<E,Object> map。
c )在它里面放置的元素都应到map里面的key部分,而在map中与key对应的value用一个Object()对象保存。
d )因为内部是大量借用HashMap的实现,它本身不过是调用HashMap的一个代理
key值为null的存储
a )如果key为null,那么将此value放置到table[0],即第一个桶中
/*** Key 为null,则将Entry<null,Value>放置到第一桶table[0]中
*/
private V putForNullKey(V value) {
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
equal和hashcode方法
for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k;
//5. 查找Entry<Key,Value>链表中是否已经有了以Key值为Key存储的Entry<Key,Value>对象,
//已经存在,则将Value值覆盖到对应的Entry<Key,Value>对象节点上
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
a) 对于给定的Key,Value,判断该Key是否与Entry链表中有某一个Entry对象的Key值相等使用的是(k==e.key)==key) || key.equals(k),另外还有一个判断条件:即Key经过hash函数转换后的hash值和当前Entry对象的hash属性值相等(该hash属性值和Entry内的Key经过hash方法转换后的hash值相等)。
b) 上述的情况我们可以总结为;HashMap在确定Key是否在HashMap中存在的要求有两个:
1) Key值是否相等;
2) hashcode是否相等;
c) 我们在定义类时,如果重写了equals()方法,但是hashcode却没有保证相等,就会导致当使用该类实例作为Key值放入HashMap中,会出现HashMap“工作异常”的问题,会出现你不希望的情况。下面让我们通过一个例子来看看这个“工作异常”情况:
线程不安全
a) HashMap是线程不安全的,如果想使用线程安全的,可以使用Hashtable;它提供的功能和Hashmap基本一致。HashMap实际上是一个Hashtable的轻量级实现;
总结
1. HashMap是线程不安全的,如果想使用线程安全的,可以使用Hashtable;它提供的功能和Hashmap基本一致。HashMap实际上是一个Hashtable的轻量级实现;
2. 允许以Key为null的形式存储<null,Value>键值对;
3. HashMap的查找效率非常高,因为它使用Hash表对进行查找,可直接定位到Key值所在的桶中;
4. 使用HashMap时,要注意HashMap容量和加载因子的关系,这将直接影响到HashMap的性能问题。加载因子过小,会提高HashMap的查找效率,但同时也消耗了大量的内存空间,加载因子过大,节省了空间,但是会导致HashMap的查找效率降低。
参考:
http://blog.csdn.net/luanlouis/article/details/41576373
http://blog.csdn.net/shohokuf/article/details/3932967
以上是 Java集合--HashMap分析 的全部内容, 来源链接: utcz.com/z/394637.html