java中json解析,xml解析

抓取网页内容,会返回json或者xml(html)格式的数据。
为了方便的对上述两种格式的数据进行解析,可采用解析工具。
JsonPath
https://github.com/jayway/JsonPath
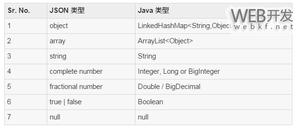
JsonPath表达式可以使用类似XPath表达式的方式,去描述JSON数据格式,XPath表达式,经常在XML格式文档中使用。在JsonPath中的根元素,不论他是对象还是数组,都用“$”表示。
Operators
| Operator | Description |
|---|---|
$ | The root element to query. This starts all path expressions. |
@ | The current node being processed by a filter predicate. |
* | Wildcard. Available anywhere a name or numeric are required. |
.. | Deep scan. Available anywhere a name is required. |
.<name> | Dot-notated child |
['<name>' (, '<name>')] | Bracket-notated child or children |
[<number> (, <number>)] | Array index or indexes |
[start:end] | Array slice operator |
[?(<expression>)] | Filter expression. Expression must evaluate to a boolean value. |
Path Examples
Given the json
{ "store": {
"book": [
{
"category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{
"category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{
"category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{
"category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
},
"expensive": 10
}
| JsonPath (click link to try) | Result |
|---|---|
| $.store.book[*].author | The authors of all books |
| $..author | All authors |
| $.store.* | All things, both books and bicycles |
| $.store..price | The price of everything |
| $..book[2] | The third book |
| $..book[0,1] | The first two books |
| $..book[:2] | All books from index 0 (inclusive) until index 2 (exclusive) |
| $..book[1:2] | All books from index 1 (inclusive) until index 2 (exclusive) |
| $..book[-2:] | Last two books |
| $..book[2:] | Book number two from tail |
| $..book[?(@.isbn)] | All books with an ISBN number |
| $.store.book[?(@.price < 10)] | All books in store cheaper than 10 |
| $..book[?(@.price <= $['expensive'])] | All books in store that are not "expensive" |
| $..book[?(@.author =~ /.*REES/i)] | All books matching regex (ignore case) |
| $..* | Give me every thing |
| $..book.length() | The number of books |
Jsoup、XPath
https://jsoup.org/
在使用Jsoup时,可使用类似jquery选择器表达式的方式,描述html,非常方便。如果要用jsoup解析xml,需要在读取时,增加parser
Document doc = Jsoup.parse(xmlString, "", Parser.xmlParser());
具体的选择器语法,可参考 https://jsoup.org/apidocs/org/jsoup/select/Selector.html
如果依然想使用XPath去解析xml文件,XPath(javax中有)。http://baike.baidu.com/link?url=OHzj7ei5c8hVMl1dLjkTg8gWlCGhNh1ZAiYinu7Nx17lUwlsAK5duK3dL741nft_Qevjhpfz0MZzfryKr0tLO_
下面列出了最有用的路径表达式:
表达式 | 描述 |
|---|---|
nodename | 选取此节点的所有子节点。 |
/ | 从根节点选取。 |
// | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
. | 选取当前节点。 |
.. | 选取当前节点的父节点。 |
@ | 选取属性。 |
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:
路径表达式 | 结果 |
|---|---|
bookstore | 选取 bookstore 元素的所有子节点。 |
/bookstore | 选取根元素 bookstore。 注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
//book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
//@lang | 选取名为 lang 的所有属性。 |
以上是 java中json解析,xml解析 的全部内容, 来源链接: utcz.com/z/393855.html