Java数据结构和算法 - 链表

Q: 为什么要引入链表的概念?它是解决什么问题的?
A: 数组作为数据存储结构有一定的缺陷,在无序数组中,搜索是低效的;而在有序数组中,插入效率又很低;不管在哪一个数组中删除效率都很低;况且一个数组创建后,它的大小是不可改变的。
A: 在本篇中,我们将学习一种新的数据结构 —— 链表,它可以解决上面的一些问题,链表可能是继数组之后第二种使用最广泛的通用存储结构了。
Q: 结点?
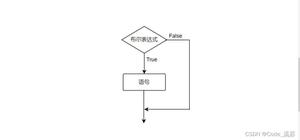
A: 在链表中,每个数据项都被包含在“结点”中,可以使用Node, 或者Entry等名词来表示结点,本篇使用Entry来表示。每个Entry对象中包含一个对下一个结点引用的字段(通常叫做next),单链表中每个结点的结构图如下:
定义单链表结点的类定义如下:
class Entry<E> { E mElement;
Entry<E> mNext;
public Entry(E element, Entry<E> next) {
mElement = element;
mNext = next;
}
}
Q: 单链表?
A: 构成链表的结点只有一个指向后继结点的指针域。
Q: 单链表的Java实现?
A: 示例:SingleLinkedList.java
A: LinkedList类只包含一个数据项mHeader,叫做表头:即对链表中第一个节点的引用。它是唯一的链表需要维护的永久信息,用以定位所有其他的链接点。从mHeader出发,沿着链表通过每个结点的mNext字段,就可以找到其他的结点。
A: addFirst()方法 —— 作用是在表头插入一个新结点。
A: removeFirst()方法 —— 是addFirst()方法的逆操作,它通过把mHeader重新指向第二个结点,断开了和第一个结点的连接。
在C++中,从链表取下一个结点后,需要考虑如何释放这个结点。它仍然在内存中的某个地方,但是现在没有任何指针指向它,将如何处理它呢?在Java中,垃圾回收(GC)将在未来的某个时刻销毁它,现在这不是程序员操心的工作。
注意,removeFirst()方法假定链表不是空的,因此调用它之前,应该首先调用empty()方法核实这一点。
Q: 如何查找和删除指定的结点?
A: indexOf(Object)方法 —— 返回此列表中首次出现的指定元素的索引,如果此列表中不包含该元素,则返回 -1。
get(int)方法 —— 返回此列表中指定位置处的元素。
A: remove(Object) —— 从此列表中移除首次出现的指定元素(如果存在)。
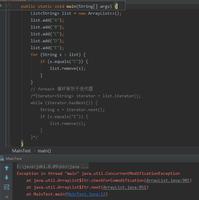
先搜索要删除的结点,如果找到了,必须把前一个结点和后一个结点连起来,知道前一个结点的唯一方法就是拥有一个对它的引用previous(每当current变量赋值为current.next之前,先把previous变量赋值为current)。
A: 示例: SingleLinkedList.java
Q: 双端链表?
A: 双端链表(double-ended list )是在上边的单链表基础上加了一个表尾,即对最后一个结点的引用。如下图:
A: 对最后一个结点的引用允许像表头一样,在表尾直接插入一个结点。当然,仍然可以在普通的单链表的表尾插入一个结点,方法是遍历整个链表直到到达表尾,但是这种方法效率很低。
Q: 双端链表的Java实现?
A: 示例: DoubleEndedList.java
A: DoubleEndedList有两个项,header和tailer,一个指向链表中的第一个结点,另一个指向最后一个结点。
A: 如果链表中只有一个结点,header和last都指向它。如果没有结点,两个都为null值。
A: 如果链表只有一个结点,删除时tailer必须被赋值为null。
A: addLast()方法 —— 在表尾插入一个新结点。
Q: 链表的效率?
A: 在表头插入和删除速度很快,仅需要改变一两个引用值,所以花费O(1)的时间。
A: 查找、删除和在指定结点的前面插入都需要搜索链表中一半的结点,需要O(N)次比较,在数组中执行这些操作也需要O(N)次比较。但是链表仍然要快一些,因为插入和删除结点时,链表不需要移动任何东西。
A: 链表比数组还有一个优点是,链表需要多少内存就可以用多少内存,不像数组在创建时大小就固定了。
A: 向量是一种可扩展的数组,它可以通过可变长度解决这个问题,但是它经常只允许以固定的增量扩展(比如快要溢出的时候,就增加1倍的数组容量)。这个解决方案在内存使用效率上来说还是要比链表低。
Q: 用链表实现的栈?
A: 示例:Stack.java
A: 栈的使用者不需要知道栈用的是链表还是数组实现。 因此Stack类的测试用例在这两个上是没有分别的。
Q: 用链表实现的队列?
A: 示例:Queue.java
A: 展示了一个用双端链表实现的队列。
Q: 什么时候应该使用链表而不是数组来实现栈和队列呢?
A: 这一点要取决于是否能精准地预测栈或队列需要容纳的数据量。如果这一点不是很清楚的话,链表就比数组表现出更好的适用性。两者都很快,所以速度可能不是考虑的重点。
Q: 什么是抽象数据类型(ADT)?
A: 简单来说,它是一种考虑数据结构的方式:着重于它做了什么,而忽略它是怎么做的。
A: 栈和队列都是ADT的例子,前面已经看到栈和队列既可以用数组实现,也可以使用链表实现,而对于使用它们的用户完全不知道具体的实现细节(用户不仅不知道方法是怎样运行,也不知道数据是如何存储的)。
A: ADT的概念在软件设计过程中很重要,如果需要存储数据,那么就要从它的实际操作上开始考虑,比如,是存取最后一个插入的数据项?还是第一个?是特定值的项?还是在特定位置上的项?回答这些问题会引出ADT的定义。
A: 只有在完整定义ADT后,才应该考虑细节问题。
A: 通过从ADT规范中剔除实现的细节,可以简化设计过程,在未来的某个时刻,易于修改实现。如果用户只接触ADT接口,应该可以在不“干扰”用户代码的情况下修改接口的实现。
A: 当然,一旦设计好ADT,必须仔细选择内部的数据结构,以使规定的操作的效率尽可能高。例如随机存取元素a,那么用链表表示就不够好,因为对链表来说,随机访问不是一个高效的操作,选择数据会得到更好的效果。
Q: 有序链表?
A: 在有序链表中,数据是按照关键值有序排列的,有序链表的删除常常是只限于删除在表头的最小(或最大)的节点。
A: 一般,在大多数需要使用有序数组的场合也可以使用有序链表。有序链表的优势在于插入的速度,因为元素不需要移动,而且链表可以随时扩展所需内存,数组只能局限于一个固定大小的内存。
A: 示例:SortedLinkedList.java
A: 当算法找到要插入的位置,用通常的方式插入数据项:把新节点的next字段指向下一个节点,然后把前一个结点的next字段指向新节点。然而,需要考虑一些特殊情况:节点有可能插在表头,或者表尾。
Q: 有序链表的效率?
A: 在有序链表插入或删除某一项最多需要O(N)次比较(平均N/2),因为必须沿着链表一步一步走才能找到正确的位置。然而,可以在O(1)的时间内找到或删除最小值,因为它总在表头。
A: 如果一个应用频繁地存取最小项,且不需要快速地插入,那么有序链表是一个有效的方案选择,例如,优先级队列可以用有序链表来实现。
Q: 链表插入排序(List Insertion Sort)?
A: 有序链表可以用于一种高效的排序机制。假设有一个无序数组,如果从这个数组中取出数据,然后一个一个地插入有序链表,它们自动地按照顺序排列。然后把它们从有序链表删除,重新放入数组,那么数组就排好序了。
A: 本质上与基于数组的插入排序是一样的,都是O(N2)的比较次数,只是说对于数组会有一半已存在的数据会涉及移动,相当于N2/4次移动,相比之下,链表只需2 * N次移动:一次是从数组到链表,一次是从链表到数组。
A: 不过链表插入有一个缺点:就是它要开辟差不多两倍的空间。
A: 示例: LinkedListSort.java
Q: 双向链表?
A: 双向链表提供了这样的能力,即允许向前遍历,也允许向后遍历整个链表,其中秘密在于它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。
A: 双向链表不必是双端链表(保持一个对链表最后一个元素的引用),但这种方式是很有用的。所以下面的示例将包含双端的性质。
Q: 基于双向链表的双端链表的Java实现?
A: 示例:DoublyLinkedList.java
A: addFirst(E)方法:将指定元素插入此列表的开头。
A: addLast(E)方法:将指定元素添加到此列表的结尾。
A: add(index, E)方法: 在此列表中指定的位置插入指定的元素。
A: remove(Object o)方法: 从此列表中移除首次出现的指定元素(如果存在)。
Q: 基于双向链表的双端队列?
A: 双向链表可以用来作为双端队列的基础。在双端队列中,可以从任何一头插入和删除,双向链表提供了这个能力。
Q: 为什么要引入迭代器的概念?
A: ArrayList底层维护的是一个数组;LinkedList是链表结构的;HashSet依赖的是哈希表,每种容器都有自己特有的数据结构。因为容器的内部结构不同,很多时候可能不知道该怎样去遍历一个容器中的元素。所以为了使对容器内元素的操作更为简单,Java引入了迭代器。
A: 把访问逻辑从不同类型的集合类中抽取出来,从而避免向外部暴露集合的内部结构。
对于数组我们使用的是下标来进行处理的:
for (int i = 0; i < array.length; i++) { System.out.println(array[i]);
}
对于链表,我们从表头开始遍历:
public void displayForward() { System.out.print("List (first-->last): [");
Entry<E> current = mHeader;
while(current != null) {
E e = current.mElement;
System.out.print(e);
if (current.mNext != null) {
System.out.print(" ");
}
current = current.mNext;
}
System.out.print("]\n");
}
A: 不同的集合会对应不同的遍历方法,客户端代码无法复用。在实际应用中如何将上面两个集合整合是相当麻烦的。所以才有Iterator,它总是用同一种逻辑来遍历集合。使得客户端自身不需要来维护集合的内部结构,所有的内部状态都由Iterator来维护。客户端不用直接和集合进行打交道,而是控制Iterator向它发送向前向后的指令,就可以遍历集合。
A: 迭代器模式就是提供一种方法对一个容器对象中的各个元素进行访问,而又不暴露该对象容器的内部细节。
Q: 迭代器定义的接口?
A: 迭代器包含对数据结构中数据项的引用,并且用来遍历这些结构的对象。下面是迭代器的接口定义:
public interface Iterator<E> { boolean hasNext();
E next();
void remove();
}
public interface ListIterator<E> extends Iterator<E> { boolean hasPrevious();
E previous();
int nextIndex();
int previousIndex();
void set(E e);
}
A: 每个容器的iterator()方法返回一个标准的Iterator实现。一般而言,Java中迭代器和链表之前的连接是通过把迭代器设为链表的内部类来实现,而C++是"友元"来实现。
A: 如下图显示了指向链表的某个结点的两个迭代器:
Q: JDK1.6的LinkedList的迭代器?
A: 迭代器类ListItr实现ListIterator接口,定义如下:
private class ListItr implements ListIterator<E> {}
A: 示例:ListIteratorTestCase.java
Q: 迭代器指向哪里?
A: 迭代器类的一个设计问题是决定在不同的操作后,迭代器应该指向哪里。而JDK1.6中LinkedList.ListItr中的add()实现,next指针一直指向表头,这里假设调用的是iterator(),不指定下标。
Q: 本篇小结
- 链表包含一个LinkedList对象和许多Entry对象。
- next字段为null意味着链表的结尾。
- 在表头插入结点需要把新结点的next字段指向原来的第一个结点,然后把header指向新结点。
- 在表头删除结点要把header指向header.next。
- 为了遍历链表,从header开始,然后从一个结点到下一个结点,方法是用每个结点的next字段找到下一个结点。
- 通过遍历链表可以找到拥有特定值的结点,一旦找到,可以显示、删除或用其他方式操纵该结点。
- 新结点可以插在某个特定值的结点的前面或后面,首先要遍历找到这个结点。
- 双端链表在链表中维护一个指向最后一个结点的引用,它通常和header一样,叫做tailer。
- 双端链表允许在表尾插入数据项。
- 抽象数据类型是一种数据存储类,不涉及它的实现。
- 栈和队列是ADT,它们既可以用数组实现,也可以用链表实现。
- 有序链表中,结点按照关键字升序或降序排列。
- 在有序链表中插入需要O(N) 的时间,因为必须要找到正确的插入点,最小值结点的删除需要O(1)时间。
- 双向链表中,每个结点包含对前一个结点的引用,同时有对后一个结点的引用。
- 双向链表允许反向遍历,并可以从表尾删除。
- 迭代器是一个引用,它被封装在类对象中,这个引用指向相关联的链表中的结点。
- 迭代器方法允许使用者沿链表移动迭代器,并访问当前所指的结点。
- 能用迭代器遍历链表,在选定的结点上执行某些操作。
以上是 Java数据结构和算法 - 链表 的全部内容, 来源链接: utcz.com/z/393827.html