转(排序算法总结) Java常用的八种排序算法与代码实现

排序问题一直是程序员工作与面试的重点,今天特意整理研究下与大家共勉!这里列出8种常见的经典排序,基本涵盖了所有的排序算法。
1.直接插入排序
我们经常会到这样一类排序问题:把新的数据插入到已经排好的数据列中。将第一个数和第二个数排序,然后构成一个有序序列将第三个数插入进去,构成一个新的有序序列。对第四个数、第五个数……直到最后一个数,重复第二步。如题所示:
直接插入排序(Straight Insertion Sorting)的基本思想:在要排序的一组数中,假设前面(n-1) [n>=2] 个数已经是排好顺序的,现在要把第n个数插到前面的有序数中,使得这n个数也是排好顺序的。如此反复循环,直到全部排好顺序。
代码实现:
首先设定插入次数,即循环次数,for(int i=1;i<length;i++),1个数的那次不用插入。
设定插入数和得到已经排好序列的最后一个数的位数。insertNum和j=i-1。
从最后一个数开始向前循环,如果插入数小于当前数,就将当前数向后移动一位。
将当前数放置到空着的位置,即j+1。
代码如下:
1 public void insertSort(int [] a){ 2 int len=a.length;//单独把数组长度拿出来,提高效率
3 int insertNum;//要插入的数
4 for(int i=1;i<len;i++){//因为第一次不用,所以从1开始
5 insertNum=a[i];
6 int j=i-1;//序列元素个数
7 while(j>=0&&a[j]>insertNum){//从后往前循环,将大于insertNum的数向后移动
8 a[j+1]=a[j];//元素向后移动
9 j--;
10 }
11 a[j+1]=insertNum;//找到位置,插入当前元素
12 }
13 }
2.希尔排序
针对直接插入排序的下效率问题,有人对次进行了改进与升级,这就是现在的希尔排序。希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。希尔排序是非稳定排序算法。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
- 插入排序在对几乎已经排好序的数据操作时, 效率高, 即可以达到线性排序的效率
- 但插入排序一般来说是低效的, 因为插入排序每次只能将数据移动一位
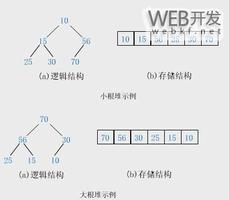
如图所示:
对于直接插入排序问题,数据量巨大时。
将数的个数设为n,取奇数k=n/2,将下标差值为k的数分为一组,构成有序序列。
再取k=k/2 ,将下标差值为k的书分为一组,构成有序序列。
重复第二步,直到k=1执行简单插入排序。
代码实现:
首先确定分的组数。
然后对组中元素进行插入排序。
然后将length/2,重复1,2步,直到length=0为止。
1 public void sheelSort(int [] a){ 2 int len=a.length;//单独把数组长度拿出来,提高效率
3 while(len!=0){
4 len=len/2;
5 for(int i=0;i<len;i++){//分组
6 for(int j=i+len;j<a.length;j+=len){//元素从第二个开始
7 int k=j-len;//k为有序序列最后一位的位数
8 int temp=a[j];//要插入的元素
9 /*for(;k>=0&&temp<a[k];k-=len){
10 a[k+len]=a[k];
11 }*/
12 while(k>=0&&temp<a[k]){//从后往前遍历
13 a[k+len]=a[k];
14 k-=len;//向后移动len位
15 }
16 a[k+len]=temp;
17 }
18 }
19 }
20 }
3.简单选择排序
常用于取序列中最大最小的几个数时。
(如果每次比较都交换,那么就是交换排序;如果每次比较完一个循环再交换,就是简单选择排序。)
遍历整个序列,将最小的数放在最前面。
遍历剩下的序列,将最小的数放在最前面。
重复第二步,直到只剩下一个数。
代码实现:
首先确定循环次数,并且记住当前数字和当前位置。
将当前位置后面所有的数与当前数字进行对比,小数赋值给key,并记住小数的位置。
比对完成后,将最小的值与第一个数的值交换。
重复2、3步。
1 public void selectSort(int[]a){ 2 int len=a.length;
3 for(int i=0;i<len;i++){//循环次数
4 int value=a[i];
5 int position=i;
6 for(int j=i+1;j<len;j++){//找到最小的值和位置
7 if(a[j]<value){
8 value=a[j];
9 position=j;
10 }
11 }
12 a[position]=a[i];//进行交换
13 a[i]=value;
14 }
15 }
4.堆排序
对简单选择排序的优化。
将序列构建成大顶堆。
将根节点与最后一个节点交换,然后断开最后一个节点。
重复第一、二步,直到所有节点断开。
代码如下:
public class headSortSolution {
/**
* 堆排序
*/
public static void heapSort(int[] list) {
//构造初始堆,从第一个非叶子节点开始调整,左右孩子节点中较大的交换到父节点中
for (int i = (list.length) / 2 - 1; i >= 0; i--) {
headAdjust(list, list.length, i);
}
//排序,将最大的节点放在堆尾,然后从根节点重新调整
for (int i = list.length - 1; i >= 1; i--) {
int temp = list[0];
list[0] = list[i];
list[i] = temp;
headAdjust(list, i, 0);
}
}
private static void headAdjust(int[] list, int len, int i) {
int k = i, index = 2 * k + 1;
int temp = list[i] ;
while (index < len) {
// 取较大孩子
if (index + 1 < len) {
if (list[index] < list[index + 1]) {
index = index + 1;
}
}
if (list[index] > temp) {
list[k] = list[index];
k = index;
index = 2 * k + 1;
} else {
break;
}
}
list[k] = temp;
}
public static void main(String[] args) {
int[] nums = {16,7,3,20,17,8};
heapSort(nums);
for (int num : nums) {
System.out.print(num + " ");
}
}
}5.冒泡排序
很简单,用到的很少,据了解,面试的时候问的比较多!
将序列中所有元素两两比较,将最大的放在最后面。
将剩余序列中所有元素两两比较,将最大的放在最后面。
重复第二步,直到只剩下一个数。
代码实现:
设置循环次数。
设置开始比较的位数,和结束的位数。
两两比较,将最小的放到前面去。
重复2、3步,直到循环次数完毕。
//第一个for循环 : 减少长度为len-1,len-2,len-3....1 的数组的逆序对
//第二个for循环 : 不断减少逆序对
1 public void bubbleSort(int []a){ 2 int len=a.length;
3 for(int i=0;i<len;i++){
4 for(int j=0;j<len-i-1;j++){//注意第二重循环的条件
5 if(a[j]>a[j+1]){
6 int temp=a[j];
7 a[j]=a[j+1];
8 a[j+1]=temp;
9 }
10 }
11 }
12 }
6.快速排序
要求时间最快时。
选择第一个数为p,小于p的数放在左边,大于p的数放在右边。
递归的将p左边和右边的数都按照第一步进行,直到不能递归。
//与冒泡排序本质相同,也是减少逆序对
1 public void quickSort(int[]a,int start,int end){ 2 if(start<end){
3 int baseNum=a[start];//选基准值
4 int midNum;//记录中间值
5 int i=start;
6 int j=end;
7 do{
8 while((a[i]<baseNum)&&i<end){
9 i++;
10 }
11 while((a[j]>baseNum)&&j>start){
12 j--;
13 }
14 if(i<=j){
15 midNum=a[i];
16 a[i]=a[j];
17 a[j]=midNum;
18 i++;
19 j--;
20 }
21 }while(i<=j);
22 if(start<j){
23 quickSort(a,start,j);
24 }
25 if(end>i){
26 quickSort(a,i,end);
27 }
28 }
29 }
7.归并排序
速度仅次于快速排序,内存少的时候使用,可以进行并行计算的时候使用。
选择相邻两个数组成一个有序序列。
选择相邻的两个有序序列组成一个有序序列。
重复第二步,直到全部组成一个有序序列。
1 public void mergeSort(int[] a, int left, int right) { 2 int t = 1;// 每组元素个数
3 int size = right - left + 1;
4 while (t < size) {
5 int s = t;// 本次循环每组元素个数
6 t = 2 * s;
7 int i = left;
8 while (i + (t - 1) < size) {
9 merge(a, i, i + (s - 1), i + (t - 1));
10 i += t;
11 }
12 if (i + (s - 1) < right)
13 merge(a, i, i + (s - 1), right);
14 }
15 }
16
17 private static void merge(int[] data, int p, int q, int r) {
18 int[] B = new int[data.length];
19 int s = p;
20 int t = q + 1;
21 int k = p;
22 while (s <= q && t <= r) {
23 if (data[s] <= data[t]) {
24 B[k] = data[s];
25 s++;
26 } else {
27 B[k] = data[t];
28 t++;
29 }
30 k++;
31 }
32 if (s == q + 1)
33 B[k++] = data[t++];
34 else
35 B[k++] = data[s++];
36 for (int i = p; i <= r; i++)
37 data[i] = B[i];
38 }
#include<iostream>#include<cstdio>
using namespace std;
const int N=100000+5;
int n;
int a[N];//需要排序的数组
int r[N];//用来辅助排序的数组
void msort(int s,int t)
{
if(s==t) return;//如果只有一个数就返回
int mid=(s+t)/2;
//递归分解
msort(s,mid);//分解左边
msort(mid+1,t);//分解右边
int i=s,j=mid+1,k=s;
//合并左右序列
while(i<=mid && j<=t) //正常排序合并
{
if(a[i]<=a[j]) {r[k]=a[i];k++;i++;}
else {r[k]=a[j];k++;j++;}
}
while(i<=mid){r[k]=a[i];k++;i++;}//复制排序后左边子序列剩余
while(j<=t){r[k]=a[j];k++;j++;}//复制排序后右边子序列剩余
for(int i=s;i<=t;i++)
a[i]=r[i];//更新a数组
}
int main()
{
scanf("%d",&n);
for(int i=1;i<=n;i++)
scanf("%d",&a[i]);
msort(1,n);
for(int i=1;i<=n;i++)
printf("%d ",a[i]);
return 0;
}
关于归并排序求逆序对模板题
关于逆序的定义:大的数排在小的数前面
当然你也可以用冒泡排序
实现方法:
每次合并的时候,记录有多少次交换
假定我们要将一串无序数字排成升序(从小到大)
根据归并排序的原理,每次我们进行合并操作的时候,左边子序列中小的数都会被合并进辅助数组。
这时如果左边子序列有数剩余,则说明这些数都比右边子序列的数要大,那么我们可以根据这一点来计算逆序对的个数
核心Code:
while(i<=mid && j<=t)
{
if(a[i]<=a[j]) {r[k]=a[i];k++;i++;}
else {r[k]=a[j];k++;j++;ans+=mid-i+1;}//核心操作
//mid-i+1即左边子序列剩余元素的个数
}
//其余部分没有什么差别
//模板题Code:
#include<iostream>
#include<cstdio>
using namespace std;
const int N=5e5+5;
long long n,ans;
int a[N];
int r[N];
void msort(int s,int t)
{
if(s==t) return;
int mid=(s+t)/2;
msort(s,mid);
msort(mid+1,t);
int i=s,j=mid+1,k=s;
while(i<=mid && j<=t)
{
if(a[i]<=a[j]) {r[k]=a[i];k++;i++;}
else {r[k]=a[j];k++;j++;ans+=mid-i+1;}//核心操作
//mid-i+1即左边子序列剩余元素的个数
}
while(i<=mid){r[k]=a[i];k++;i++;}
while(j<=t){r[k]=a[j];k++;j++;}
for(int i=s;i<=t;i++)
a[i]=r[i];
}
int main()
{
scanf("%d",&n);
for(int i=1;i<=n;i++)
scanf("%d",&a[i]);
msort(1,n);
printf("%lld",ans);
return 0;
}
8.基数排序
用于大量数,很长的数进行排序时。
将所有的数的个位数取出,按照个位数进行排序,构成一个序列。
将新构成的所有的数的十位数取出,按照十位数进行排序,构成一个序列。
代码实现:
1 public void baseSort(int[] a) { 2 //首先确定排序的趟数;
3 int max = a[0];
4 for (int i = 1; i < a.length; i++) {
5 if (a[i] > max) {
6 max = a[i];
7 }
8 }
9 int time = 0;
10 //判断位数;
11 while (max > 0) {
12 max /= 10;
13 time++;
14 }
15 //建立10个队列;
16 List<ArrayList<Integer>> queue = new ArrayList<ArrayList<Integer>>();
17 for (int i = 0; i < 10; i++) {
18 ArrayList<Integer> queue1 = new ArrayList<Integer>();
19 queue.add(queue1);
20 }
21 //进行time次分配和收集;
22 for (int i = 0; i < time; i++) {
23 //分配数组元素;
24 for (int j = 0; j < a.length; j++) {
25 //得到数字的第time+1位数;
26 int x = a[j] % (int) Math.pow(10, i + 1) / (int) Math.pow(10, i);
27 ArrayList<Integer> queue2 = queue.get(x);
28 queue2.add(a[j]);
29 queue.set(x, queue2);
30 }
31 int count = 0;//元素计数器;
32 //收集队列元素;
33 for (int k = 0; k < 10; k++) {
34 while (queue.get(k).size() > 0) {
35 ArrayList<Integer> queue3 = queue.get(k);
36 a[count] = queue3.get(0);
37 queue3.remove(0);
38 count++;
39 }
40 }
41 }
42 }
新建测试类进行测试
1 public class TestSort { 2 public static void main(String[] args) {
3 int []a=new int[10];
4 for(int i=1;i<a.length;i++){
5 //a[i]=(int)(new Random().nextInt(100));
6 a[i]=(int)(Math.random()*100);
7 }
8 System.out.println("排序前的数组为:"+Arrays.toString(a));
9 Sort s=new Sort();
10 //排序方法测试
11 //s.insertSort(a);
12 //s.sheelSort(a);
13 //s.selectSort(a);
14 //s.heapSort(a);
15 //s.bubbleSort(a);
16 //s.quickSort(a, 1, 9);
17 //s.mergeSort(a, 3, 7);
18 s.baseSort(a);
19 System.out.println("排序后的数组为:"+Arrays.toString(a));
20 }
21
22 }
部分结果如下:
如果要进行比较可已加入时间,输出排序时间,从而比较各个排序算法的优缺点,这里不再做介绍。
8.总结:
一、稳定性:
稳定:冒泡排序、插入排序、归并排序和基数排序
不稳定:选择排序、快速排序、希尔排序、堆排序
二、平均时间复杂度
O(n^2):直接插入排序,简单选择排序,冒泡排序。
在数据规模较小时(9W内),直接插入排序,简单选择排序差不多。当数据较大时,冒泡排序算法的时间代价最高。性能为O(n^2)的算法基本上是相邻元素进行比较,基本上都是稳定的。
O(nlogn):快速排序,归并排序,希尔排序,堆排序。
其中,快排是最好的, 其次是归并和希尔,堆排序在数据量很大时效果明显。
三、排序算法的选择
1.数据规模较小
(1)待排序列基本序的情况下,可以选择直接插入排序;
(2)对稳定性不作要求宜用简单选择排序,对稳定性有要求宜用插入或冒泡
2.数据规模不是很大
(1)完全可以用内存空间,序列杂乱无序,对稳定性没有要求,快速排序,此时要付出log(N)的额外空间。
(2)序列本身可能有序,对稳定性有要求,空间允许下,宜用归并排序
3.数据规模很大
(1)对稳定性有求,则可考虑归并排序。
(2)对稳定性没要求,宜用堆排序
4.序列初始基本有序(正序),宜用直接插入,冒泡
各算法复杂度如下:
基数排序、桶排序和计数排序的区别
1.桶排序(Bucket Sort)
基本思路是:
- 将待排序元素划分到不同的痛。先扫描一遍序列求出最大值 maxV 和最小值 minV ,设桶的个数为 k ,则把区间 [minV, maxV] 均匀划分成 k 个区间,每个区间就是一个桶。将序列中的元素分配到各自的桶。
- 对每个桶内的元素进行排序。可以选择任意一种排序算法。
- 将各个桶中的元素合并成一个大的有序序列。
- 假设数据是均匀分布的,则每个桶的元素平均个数为 n/k 。假设选择用快速排序对每个桶内的元素进行排序,那么每次排序的时间复杂度为 O(n/klog(n/k)) 。总的时间复杂度为 O(n)+O(m)O(n/klog(n/k)) = O(n+nlog(n/k)) = O(n+nlogn-nlogk 。当 k 接近于 n 时,桶排序的时间复杂度就可以金斯认为是 O(n) 的。即桶越多,时间效率就越高,而桶越多,空间就越大。
2.计数排序(Counting Sort)
是一种O(n)的排序算法,其思路是开一个长度为 maxValue-minValue+1 的数组,然后
- 分配。扫描一遍原始数组,以当前值- minValue 作为下标,将该下标的计数器增1。
- 收集。扫描一遍计数器数组,按顺序把值收集起来。
举个例子, nums=[2, 1, 3, 1, 5] , 首先扫描一遍获取最小值和最大值, maxValue=5 , minValue=1 ,于是开一个长度为5的计数器数组 counter ,
1. 分配。统计每个元素出现的频率,得到 counter=[2, 1, 1, 0, 1] ,例如 counter[0] 表示值 0+minValue=1 出现了2次。
2. 收集。 counter[0]=2 表示 1 出现了两次,那就向原始数组写入两个1, counter[1]=1 表示 2 出现了1次,那就向原始数组写入一个2,依次类推,最终原始数组变为 [1,1,2,3,5] ,排序好了。
计数排序本质上是一种特殊的桶排序,当桶的个数最大的时候,就是计数排序。
3.基数排序
是一种非比较排序算法,时间复杂度是 O(n) 。它的主要思路是,
1. 将所有待排序整数(注意,必须是非负整数)统一为位数相同的整数,位数较少的前面补零。一般用10进制,也可以用16进制甚至2进制。所以前提是能够找到最大值,得到最长的位数,设 k 进制下最长为位数为 d 。
2. 从最低位开始,依次进行一次稳定排序。这样从最低位一直到最高位排序完成以后,整个序列就变成了一个有序序列。
举个例子,有一个整数序列,0, 123, 45, 386, 106,下面是排序过程:
- 第一次排序,个位,000 123 045 386 106,无任何变化
- 第二次排序,十位,000 106 123 045 386
- 第三次排序,百位,000 045 106 123 386
- 最终结果,0, 45, 106, 123, 386, 排序完成。
- 为什么同一数位的排序子程序要用稳定排序?因为稳定排序能将上一次排序的成果保留下来。例如十位数的排序过程能保留个位数的排序成果,百位数的排序过程能保留十位数的排序成果。能不能用2进制?能,可以把待排序序列中的每个整数都看成是01组成的二进制数值。那这样的话,岂不是任意一个非负整数序列都可以用基数排序算法?理论上是的,假设待排序序列中最大整数为2 4 . 1,则最大位数 d=64 ,时间复杂度为 O(64n) 。可见任意一个非负整数序列都可以在线性时间内完成排序。
- 既然任意一个非负整数序列都可以在线性时间内完成排序,那么基于比较排序的算法有什么意义呢?基于比较的排序算法,时间复杂度是 O(nlogn) ,看起来比 O(64n) 慢,仔细一想,其实不是, O(nlogn) 只有当序列非常长,达到2 个元素的时候,才会与 O(64n) 相等,因此,64这个常数系数太大了,大部分时候, n 远远小于2 ,基于比较的排序算法还是比 O(64n) 快的。
- 当使用2进制时, k=2 最小,位数 d 最大,时间复杂度 O(nd) 会变大,空间复杂度 O(n+k) 会变小。当用最大值作为基数时, k=maxV 最大, d=1 最小,此时时间复杂度 O(nd) 变小,但是空间复杂度 O(n+k) 会急剧增大,此时基数排序退化成了计数排序。
先比较时间复杂度和空间复杂度。
其中, d 表示位数, k 在基数排序中表示 k 进制,在桶排序中表示桶的个数, maxV 和 minV 表示元
素最大值和最小值。
- 首先,基数排序和计数排序都可以看作是桶排序。
- 计数排序本质上是一种特殊的桶排序,当桶的个数取最大( maxV-minV+1 )的时候,就变成了计数排序。
- 基数排序也是一种桶排序。桶排序是按值区间划分桶,基数排序是按数位来划分;基数排序可以看做是多轮桶排序,每个数位上都进行一轮桶排序。
- 当用最大值作为基数时,基数排序就退化成了计数排序。
- 当使用2进制时, k=2 最小,位数 d 最大,时间复杂度 O(nd) 会变大,空间复杂度 O(n+k) 会变小。当用最大值作为基数时, k=maxV 最大, d=1 最小,此时时间复杂度 O(nd) 变小,但是空间复杂度 O(n+k) 会急剧增大,此时基数排序退化成了计数排序。
参考文献:
https://www.cnblogs.com/10158wsj/p/6782124.html?utm_source=tuicool&utm_medium=referral
https://blog.csdn.net/qq_19446965/article/details/81517552
排序问题一直是程序员工作与面试的重点,今天特意整理研究下与大家共勉!这里列出8种常见的经典排序,基本涵盖了所有的排序算法。
1.直接插入排序
我们经常会到这样一类排序问题:把新的数据插入到已经排好的数据列中。将第一个数和第二个数排序,然后构成一个有序序列将第三个数插入进去,构成一个新的有序序列。对第四个数、第五个数……直到最后一个数,重复第二步。如题所示:
直接插入排序(Straight Insertion Sorting)的基本思想:在要排序的一组数中,假设前面(n-1) [n>=2] 个数已经是排好顺序的,现在要把第n个数插到前面的有序数中,使得这n个数也是排好顺序的。如此反复循环,直到全部排好顺序。
代码实现:
首先设定插入次数,即循环次数,for(int i=1;i<length;i++),1个数的那次不用插入。
设定插入数和得到已经排好序列的最后一个数的位数。insertNum和j=i-1。
从最后一个数开始向前循环,如果插入数小于当前数,就将当前数向后移动一位。
将当前数放置到空着的位置,即j+1。
代码如下:
1 public void insertSort(int [] a){ 2 int len=a.length;//单独把数组长度拿出来,提高效率
3 int insertNum;//要插入的数
4 for(int i=1;i<len;i++){//因为第一次不用,所以从1开始
5 insertNum=a[i];
6 int j=i-1;//序列元素个数
7 while(j>=0&&a[j]>insertNum){//从后往前循环,将大于insertNum的数向后移动
8 a[j+1]=a[j];//元素向后移动
9 j--;
10 }
11 a[j+1]=insertNum;//找到位置,插入当前元素
12 }
13 }
2.希尔排序
针对直接插入排序的下效率问题,有人对次进行了改进与升级,这就是现在的希尔排序。希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。希尔排序是非稳定排序算法。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
- 插入排序在对几乎已经排好序的数据操作时, 效率高, 即可以达到线性排序的效率
- 但插入排序一般来说是低效的, 因为插入排序每次只能将数据移动一位
如图所示:
对于直接插入排序问题,数据量巨大时。
将数的个数设为n,取奇数k=n/2,将下标差值为k的数分为一组,构成有序序列。
再取k=k/2 ,将下标差值为k的书分为一组,构成有序序列。
重复第二步,直到k=1执行简单插入排序。
代码实现:
首先确定分的组数。
然后对组中元素进行插入排序。
然后将length/2,重复1,2步,直到length=0为止。
1 public void sheelSort(int [] a){ 2 int len=a.length;//单独把数组长度拿出来,提高效率
3 while(len!=0){
4 len=len/2;
5 for(int i=0;i<len;i++){//分组
6 for(int j=i+len;j<a.length;j+=len){//元素从第二个开始
7 int k=j-len;//k为有序序列最后一位的位数
8 int temp=a[j];//要插入的元素
9 /*for(;k>=0&&temp<a[k];k-=len){
10 a[k+len]=a[k];
11 }*/
12 while(k>=0&&temp<a[k]){//从后往前遍历
13 a[k+len]=a[k];
14 k-=len;//向后移动len位
15 }
16 a[k+len]=temp;
17 }
18 }
19 }
20 }
3.简单选择排序
常用于取序列中最大最小的几个数时。
(如果每次比较都交换,那么就是交换排序;如果每次比较完一个循环再交换,就是简单选择排序。)
遍历整个序列,将最小的数放在最前面。
遍历剩下的序列,将最小的数放在最前面。
重复第二步,直到只剩下一个数。
代码实现:
首先确定循环次数,并且记住当前数字和当前位置。
将当前位置后面所有的数与当前数字进行对比,小数赋值给key,并记住小数的位置。
比对完成后,将最小的值与第一个数的值交换。
重复2、3步。
1 public void selectSort(int[]a){ 2 int len=a.length;
3 for(int i=0;i<len;i++){//循环次数
4 int value=a[i];
5 int position=i;
6 for(int j=i+1;j<len;j++){//找到最小的值和位置
7 if(a[j]<value){
8 value=a[j];
9 position=j;
10 }
11 }
12 a[position]=a[i];//进行交换
13 a[i]=value;
14 }
15 }
4.堆排序
对简单选择排序的优化。
将序列构建成大顶堆。
将根节点与最后一个节点交换,然后断开最后一个节点。
重复第一、二步,直到所有节点断开。
代码如下:
public class headSortSolution {
/**
* 堆排序
*/
public static void heapSort(int[] list) {
//构造初始堆,从第一个非叶子节点开始调整,左右孩子节点中较大的交换到父节点中
for (int i = (list.length) / 2 - 1; i >= 0; i--) {
headAdjust(list, list.length, i);
}
//排序,将最大的节点放在堆尾,然后从根节点重新调整
for (int i = list.length - 1; i >= 1; i--) {
int temp = list[0];
list[0] = list[i];
list[i] = temp;
headAdjust(list, i, 0);
}
}
private static void headAdjust(int[] list, int len, int i) {
int k = i, index = 2 * k + 1;
int temp = list[i] ;
while (index < len) {
// 取较大孩子
if (index + 1 < len) {
if (list[index] < list[index + 1]) {
index = index + 1;
}
}
if (list[index] > temp) {
list[k] = list[index];
k = index;
index = 2 * k + 1;
} else {
break;
}
}
list[k] = temp;
}
public static void main(String[] args) {
int[] nums = {16,7,3,20,17,8};
heapSort(nums);
for (int num : nums) {
System.out.print(num + " ");
}
}
}5.冒泡排序
很简单,用到的很少,据了解,面试的时候问的比较多!
将序列中所有元素两两比较,将最大的放在最后面。
将剩余序列中所有元素两两比较,将最大的放在最后面。
重复第二步,直到只剩下一个数。
代码实现:
设置循环次数。
设置开始比较的位数,和结束的位数。
两两比较,将最小的放到前面去。
重复2、3步,直到循环次数完毕。
//第一个for循环 : 减少长度为len-1,len-2,len-3....1 的数组的逆序对
//第二个for循环 : 不断减少逆序对
1 public void bubbleSort(int []a){ 2 int len=a.length;
3 for(int i=0;i<len;i++){
4 for(int j=0;j<len-i-1;j++){//注意第二重循环的条件
5 if(a[j]>a[j+1]){
6 int temp=a[j];
7 a[j]=a[j+1];
8 a[j+1]=temp;
9 }
10 }
11 }
12 }
6.快速排序
要求时间最快时。
选择第一个数为p,小于p的数放在左边,大于p的数放在右边。
递归的将p左边和右边的数都按照第一步进行,直到不能递归。
//与冒泡排序本质相同,也是减少逆序对
1 public void quickSort(int[]a,int start,int end){ 2 if(start<end){
3 int baseNum=a[start];//选基准值
4 int midNum;//记录中间值
5 int i=start;
6 int j=end;
7 do{
8 while((a[i]<baseNum)&&i<end){
9 i++;
10 }
11 while((a[j]>baseNum)&&j>start){
12 j--;
13 }
14 if(i<=j){
15 midNum=a[i];
16 a[i]=a[j];
17 a[j]=midNum;
18 i++;
19 j--;
20 }
21 }while(i<=j);
22 if(start<j){
23 quickSort(a,start,j);
24 }
25 if(end>i){
26 quickSort(a,i,end);
27 }
28 }
29 }
7.归并排序
速度仅次于快速排序,内存少的时候使用,可以进行并行计算的时候使用。
选择相邻两个数组成一个有序序列。
选择相邻的两个有序序列组成一个有序序列。
重复第二步,直到全部组成一个有序序列。
1 public void mergeSort(int[] a, int left, int right) { 2 int t = 1;// 每组元素个数
3 int size = right - left + 1;
4 while (t < size) {
5 int s = t;// 本次循环每组元素个数
6 t = 2 * s;
7 int i = left;
8 while (i + (t - 1) < size) {
9 merge(a, i, i + (s - 1), i + (t - 1));
10 i += t;
11 }
12 if (i + (s - 1) < right)
13 merge(a, i, i + (s - 1), right);
14 }
15 }
16
17 private static void merge(int[] data, int p, int q, int r) {
18 int[] B = new int[data.length];
19 int s = p;
20 int t = q + 1;
21 int k = p;
22 while (s <= q && t <= r) {
23 if (data[s] <= data[t]) {
24 B[k] = data[s];
25 s++;
26 } else {
27 B[k] = data[t];
28 t++;
29 }
30 k++;
31 }
32 if (s == q + 1)
33 B[k++] = data[t++];
34 else
35 B[k++] = data[s++];
36 for (int i = p; i <= r; i++)
37 data[i] = B[i];
38 }
#include<iostream>#include<cstdio>
using namespace std;
const int N=100000+5;
int n;
int a[N];//需要排序的数组
int r[N];//用来辅助排序的数组
void msort(int s,int t)
{
if(s==t) return;//如果只有一个数就返回
int mid=(s+t)/2;
//递归分解
msort(s,mid);//分解左边
msort(mid+1,t);//分解右边
int i=s,j=mid+1,k=s;
//合并左右序列
while(i<=mid && j<=t) //正常排序合并
{
if(a[i]<=a[j]) {r[k]=a[i];k++;i++;}
else {r[k]=a[j];k++;j++;}
}
while(i<=mid){r[k]=a[i];k++;i++;}//复制排序后左边子序列剩余
while(j<=t){r[k]=a[j];k++;j++;}//复制排序后右边子序列剩余
for(int i=s;i<=t;i++)
a[i]=r[i];//更新a数组
}
int main()
{
scanf("%d",&n);
for(int i=1;i<=n;i++)
scanf("%d",&a[i]);
msort(1,n);
for(int i=1;i<=n;i++)
printf("%d ",a[i]);
return 0;
}
关于归并排序求逆序对模板题
关于逆序的定义:大的数排在小的数前面
当然你也可以用冒泡排序
实现方法:
每次合并的时候,记录有多少次交换
假定我们要将一串无序数字排成升序(从小到大)
根据归并排序的原理,每次我们进行合并操作的时候,左边子序列中小的数都会被合并进辅助数组。
这时如果左边子序列有数剩余,则说明这些数都比右边子序列的数要大,那么我们可以根据这一点来计算逆序对的个数
核心Code:
while(i<=mid && j<=t)
{
if(a[i]<=a[j]) {r[k]=a[i];k++;i++;}
else {r[k]=a[j];k++;j++;ans+=mid-i+1;}//核心操作
//mid-i+1即左边子序列剩余元素的个数
}
//其余部分没有什么差别
//模板题Code:
#include<iostream>
#include<cstdio>
using namespace std;
const int N=5e5+5;
long long n,ans;
int a[N];
int r[N];
void msort(int s,int t)
{
if(s==t) return;
int mid=(s+t)/2;
msort(s,mid);
msort(mid+1,t);
int i=s,j=mid+1,k=s;
while(i<=mid && j<=t)
{
if(a[i]<=a[j]) {r[k]=a[i];k++;i++;}
else {r[k]=a[j];k++;j++;ans+=mid-i+1;}//核心操作
//mid-i+1即左边子序列剩余元素的个数
}
while(i<=mid){r[k]=a[i];k++;i++;}
while(j<=t){r[k]=a[j];k++;j++;}
for(int i=s;i<=t;i++)
a[i]=r[i];
}
int main()
{
scanf("%d",&n);
for(int i=1;i<=n;i++)
scanf("%d",&a[i]);
msort(1,n);
printf("%lld",ans);
return 0;
}
8.基数排序
用于大量数,很长的数进行排序时。
将所有的数的个位数取出,按照个位数进行排序,构成一个序列。
将新构成的所有的数的十位数取出,按照十位数进行排序,构成一个序列。
代码实现:
1 public void baseSort(int[] a) { 2 //首先确定排序的趟数;
3 int max = a[0];
4 for (int i = 1; i < a.length; i++) {
5 if (a[i] > max) {
6 max = a[i];
7 }
8 }
9 int time = 0;
10 //判断位数;
11 while (max > 0) {
12 max /= 10;
13 time++;
14 }
15 //建立10个队列;
16 List<ArrayList<Integer>> queue = new ArrayList<ArrayList<Integer>>();
17 for (int i = 0; i < 10; i++) {
18 ArrayList<Integer> queue1 = new ArrayList<Integer>();
19 queue.add(queue1);
20 }
21 //进行time次分配和收集;
22 for (int i = 0; i < time; i++) {
23 //分配数组元素;
24 for (int j = 0; j < a.length; j++) {
25 //得到数字的第time+1位数;
26 int x = a[j] % (int) Math.pow(10, i + 1) / (int) Math.pow(10, i);
27 ArrayList<Integer> queue2 = queue.get(x);
28 queue2.add(a[j]);
29 queue.set(x, queue2);
30 }
31 int count = 0;//元素计数器;
32 //收集队列元素;
33 for (int k = 0; k < 10; k++) {
34 while (queue.get(k).size() > 0) {
35 ArrayList<Integer> queue3 = queue.get(k);
36 a[count] = queue3.get(0);
37 queue3.remove(0);
38 count++;
39 }
40 }
41 }
42 }
新建测试类进行测试
1 public class TestSort { 2 public static void main(String[] args) {
3 int []a=new int[10];
4 for(int i=1;i<a.length;i++){
5 //a[i]=(int)(new Random().nextInt(100));
6 a[i]=(int)(Math.random()*100);
7 }
8 System.out.println("排序前的数组为:"+Arrays.toString(a));
9 Sort s=new Sort();
10 //排序方法测试
11 //s.insertSort(a);
12 //s.sheelSort(a);
13 //s.selectSort(a);
14 //s.heapSort(a);
15 //s.bubbleSort(a);
16 //s.quickSort(a, 1, 9);
17 //s.mergeSort(a, 3, 7);
18 s.baseSort(a);
19 System.out.println("排序后的数组为:"+Arrays.toString(a));
20 }
21
22 }
部分结果如下:
如果要进行比较可已加入时间,输出排序时间,从而比较各个排序算法的优缺点,这里不再做介绍。
8.总结:
一、稳定性:
稳定:冒泡排序、插入排序、归并排序和基数排序
不稳定:选择排序、快速排序、希尔排序、堆排序
二、平均时间复杂度
O(n^2):直接插入排序,简单选择排序,冒泡排序。
在数据规模较小时(9W内),直接插入排序,简单选择排序差不多。当数据较大时,冒泡排序算法的时间代价最高。性能为O(n^2)的算法基本上是相邻元素进行比较,基本上都是稳定的。
O(nlogn):快速排序,归并排序,希尔排序,堆排序。
其中,快排是最好的, 其次是归并和希尔,堆排序在数据量很大时效果明显。
三、排序算法的选择
1.数据规模较小
(1)待排序列基本序的情况下,可以选择直接插入排序;
(2)对稳定性不作要求宜用简单选择排序,对稳定性有要求宜用插入或冒泡
2.数据规模不是很大
(1)完全可以用内存空间,序列杂乱无序,对稳定性没有要求,快速排序,此时要付出log(N)的额外空间。
(2)序列本身可能有序,对稳定性有要求,空间允许下,宜用归并排序
3.数据规模很大
(1)对稳定性有求,则可考虑归并排序。
(2)对稳定性没要求,宜用堆排序
4.序列初始基本有序(正序),宜用直接插入,冒泡
各算法复杂度如下:
基数排序、桶排序和计数排序的区别
1.桶排序(Bucket Sort)
基本思路是:
- 将待排序元素划分到不同的痛。先扫描一遍序列求出最大值 maxV 和最小值 minV ,设桶的个数为 k ,则把区间 [minV, maxV] 均匀划分成 k 个区间,每个区间就是一个桶。将序列中的元素分配到各自的桶。
- 对每个桶内的元素进行排序。可以选择任意一种排序算法。
- 将各个桶中的元素合并成一个大的有序序列。
- 假设数据是均匀分布的,则每个桶的元素平均个数为 n/k 。假设选择用快速排序对每个桶内的元素进行排序,那么每次排序的时间复杂度为 O(n/klog(n/k)) 。总的时间复杂度为 O(n)+O(m)O(n/klog(n/k)) = O(n+nlog(n/k)) = O(n+nlogn-nlogk 。当 k 接近于 n 时,桶排序的时间复杂度就可以金斯认为是 O(n) 的。即桶越多,时间效率就越高,而桶越多,空间就越大。
2.计数排序(Counting Sort)
是一种O(n)的排序算法,其思路是开一个长度为 maxValue-minValue+1 的数组,然后
- 分配。扫描一遍原始数组,以当前值- minValue 作为下标,将该下标的计数器增1。
- 收集。扫描一遍计数器数组,按顺序把值收集起来。
举个例子, nums=[2, 1, 3, 1, 5] , 首先扫描一遍获取最小值和最大值, maxValue=5 , minValue=1 ,于是开一个长度为5的计数器数组 counter ,
1. 分配。统计每个元素出现的频率,得到 counter=[2, 1, 1, 0, 1] ,例如 counter[0] 表示值 0+minValue=1 出现了2次。
2. 收集。 counter[0]=2 表示 1 出现了两次,那就向原始数组写入两个1, counter[1]=1 表示 2 出现了1次,那就向原始数组写入一个2,依次类推,最终原始数组变为 [1,1,2,3,5] ,排序好了。
计数排序本质上是一种特殊的桶排序,当桶的个数最大的时候,就是计数排序。
3.基数排序
是一种非比较排序算法,时间复杂度是 O(n) 。它的主要思路是,
1. 将所有待排序整数(注意,必须是非负整数)统一为位数相同的整数,位数较少的前面补零。一般用10进制,也可以用16进制甚至2进制。所以前提是能够找到最大值,得到最长的位数,设 k 进制下最长为位数为 d 。
2. 从最低位开始,依次进行一次稳定排序。这样从最低位一直到最高位排序完成以后,整个序列就变成了一个有序序列。
举个例子,有一个整数序列,0, 123, 45, 386, 106,下面是排序过程:
- 第一次排序,个位,000 123 045 386 106,无任何变化
- 第二次排序,十位,000 106 123 045 386
- 第三次排序,百位,000 045 106 123 386
- 最终结果,0, 45, 106, 123, 386, 排序完成。
- 为什么同一数位的排序子程序要用稳定排序?因为稳定排序能将上一次排序的成果保留下来。例如十位数的排序过程能保留个位数的排序成果,百位数的排序过程能保留十位数的排序成果。能不能用2进制?能,可以把待排序序列中的每个整数都看成是01组成的二进制数值。那这样的话,岂不是任意一个非负整数序列都可以用基数排序算法?理论上是的,假设待排序序列中最大整数为2 4 . 1,则最大位数 d=64 ,时间复杂度为 O(64n) 。可见任意一个非负整数序列都可以在线性时间内完成排序。
- 既然任意一个非负整数序列都可以在线性时间内完成排序,那么基于比较排序的算法有什么意义呢?基于比较的排序算法,时间复杂度是 O(nlogn) ,看起来比 O(64n) 慢,仔细一想,其实不是, O(nlogn) 只有当序列非常长,达到2 个元素的时候,才会与 O(64n) 相等,因此,64这个常数系数太大了,大部分时候, n 远远小于2 ,基于比较的排序算法还是比 O(64n) 快的。
- 当使用2进制时, k=2 最小,位数 d 最大,时间复杂度 O(nd) 会变大,空间复杂度 O(n+k) 会变小。当用最大值作为基数时, k=maxV 最大, d=1 最小,此时时间复杂度 O(nd) 变小,但是空间复杂度 O(n+k) 会急剧增大,此时基数排序退化成了计数排序。
先比较时间复杂度和空间复杂度。
其中, d 表示位数, k 在基数排序中表示 k 进制,在桶排序中表示桶的个数, maxV 和 minV 表示元
素最大值和最小值。
- 首先,基数排序和计数排序都可以看作是桶排序。
- 计数排序本质上是一种特殊的桶排序,当桶的个数取最大( maxV-minV+1 )的时候,就变成了计数排序。
- 基数排序也是一种桶排序。桶排序是按值区间划分桶,基数排序是按数位来划分;基数排序可以看做是多轮桶排序,每个数位上都进行一轮桶排序。
- 当用最大值作为基数时,基数排序就退化成了计数排序。
- 当使用2进制时, k=2 最小,位数 d 最大,时间复杂度 O(nd) 会变大,空间复杂度 O(n+k) 会变小。当用最大值作为基数时, k=maxV 最大, d=1 最小,此时时间复杂度 O(nd) 变小,但是空间复杂度 O(n+k) 会急剧增大,此时基数排序退化成了计数排序。
以上是 转(排序算法总结) Java常用的八种排序算法与代码实现 的全部内容, 来源链接: utcz.com/z/393268.html