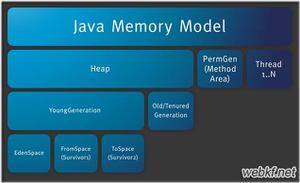
Java中heap(堆)和stack(栈)的区别

将从以下几个方面阐述堆(heap)和栈(stack)的区别。
1. 申请方式
stack:由系统自动分配。例如,声明在函数中一个局部变量 int b; 系统自动在栈中为b开辟空间
heap:需要程序员自己申请,并指明大小,在c中malloc函数,对于Java需要手动new Object()的形式开辟
2. 申请后系统的响应
stack:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
heap:首先应该知道操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,
会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序。另外,由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中。
3. 申请大小的限制
stack:栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在 WINDOWS下,栈的大小是2M(也有的说是1M,总之是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从栈获得的空间较小。
heap:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
4. 申请效率的比较
stack:由系统自动分配,速度较快。但程序员是无法控制的。
heap:由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便。
5. heap和stack中的存储内容
stack: 在函数调用时,第一个进栈的是主函数中后的下一条指令(函数调用语句的下一条可执行语句)的地址,然后是函数的各个参数,在大多数的 C 编译器中,参数是由右往左入栈的,然后是函数中的局部变量。注意静态变量是不入栈的。
当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续运行。
heap:一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容有程序员安排。
6. 数据结构层面的区别
还有就是数据结构方面的堆和栈,这些都是不同的概念。这里的堆实际上指的就是(满足堆性质的)优先队列的一种数据结构,第1个元素有最高的优先权;栈实际上就是满足先进后出的性质的数学或数据结构。
虽然堆栈,堆栈的说法是连起来叫,但是他们还是有很大区别的,连着叫只是由于历史的原因。
拓展知识(Java中堆栈的应用)
1). 栈(stack)与堆(heap)都是 Java 用来在 Ram 中存放数据的地方。与 C++不同,Java 自动管理栈和堆,程序员不能直接地设置栈或堆。
2). 栈的优势是,存取速度比堆要快,仅次于直接位于 CPU 中的寄存器。但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。另外,栈数据可以共享,详见第 3 点。堆的优势是可以动态地分配内存大小,生存期也不必事先告诉编译器,Java 的垃圾回收器会自动收走这些不再使用的数据。但缺点是,由于要在运行时动态分配内存,存取速度较慢。
3). Java中的数据类型有两种。
一种是基本类型(primitive types), 共有8种,即int, short, long, byte, float, double, boolean, char(注
意,并没有string的基本类型)。这种类型的定义是通过诸如int a = 3; long b = 255L;的形式来定义的,称为自动变量(自动变量:只在定义它们的时候才创建,在定义它们的函数返回时系统回收变量所占存储空间。对这些变量存储空间的分配和回收是由系统自动完成的。)。值得注意的是,自动变量存的是字面值,不是类的实例,即不是类的引用,这里并没有类的存在。如int a = 3; 这里的a是一个指向int类型的引用,指向3这个字面值。这些字面值的数据,由于大小可知,生存期可知(这些字面值固定定义在某个程序块里面,程序块退出后,字段值就消失了),出于追求速度的原因,就存在于栈中。
另外,栈有一个很重要的特殊性,就是存在栈中的数据可以共享。假设我们同时定义
int a = 3;
int b = 3;
编译器先处理int a = 3;首先它会在栈中创建一个变量为a的引用,然后查找有没有字面值为3的地址,没找到,就开辟一个存放3这个字面值的地址,然后将 a 指向 3的地址。接着处理int b = 3;在创建完b的引用变量后,由于在栈中已经有3这个字面值,便将b直接指向3的地址。这样,就出现了a与b同时均指向3的情况。
特别注意的是,这种字面值的引用与类对象的引用不同。假定两个类对象的引用同时指向一个对象,如果一个对象引用变量修改了这个对象的内部状态,那么另一个对象引用变量也即刻反映出这个变化。相反,通过字面值的引用来修改其值,不会导致另一个指向此字面值的引用的值也跟着改变的情况。如上例,我们定义完 a 与 b 的值后,再令 a=4;那么,b 不会等于 4,还是等于 3。在编译器内部,遇到 a=4;时,它就会重新搜索栈中是否有 4 的字面值,如果没有,重新开辟地址存放 4 的值;如果已经有了,则直接将 a 指向这个地址。因此 a 值的改变不会影响到b的值。
另一种是包装类数据,如Integer, String, Double等将相应的基本数据类型包装起来的类。这些类数据全部存在于堆中,Java 用 new()语句来显示地告诉编译器,在运行时才根据需要动态创建,因此比较灵活,但缺点是要占用更多的时间。
4).每个 JVM的线程都有自己的私有的栈空间,随线程创建而创建,java的stack存放的是frames,java的stack和c的不同,只是存放本地变量,返回值和调用方法,不允许直接push和pop frames ,因为frames 可能是有heap分配的,所以java的stack分配的内存不需要是连续的。java的heap是所有线程共享的,堆存放所有 runtime data ,里面是所有的对象实例和数组,heap是JVM启动时创建。
5). String 是一个特殊的包装类数据。即可以用 String str = new String("abc");的形式来创建,也可以用String str = "abc";的形式来创建(作为对比,在JDK 5.0之前,你从未见过Integer i = 3;的表达式,因为类与字面值是不能通用的,除了 String。而在 JDK 5.0 中,这种表达式是可以的!因为编译器在后台进行 Integer i = new nteger(3)的转换)。前者是规范的类的创建过程,即在Java中,一切都是对象,而对象是类的实例,全部通过new()的形式来创建。那为什么在String str = "abc";中,并没有通过new()来创建实例,是不是违反了上述原则?其实没有。
5.1). 关于String str = "abc"的内部工作。Java内部将此语句转化为以下几个步骤:
(1)先定义一个名为str的对 String类的对象引用变量:String str;
(2)在栈中查找有没有存放值为"abc"的地址,如果没有,则开辟一个存放字面值为"abc"的地址,接着创建一个新的String类的对象o,并将o 的字符串值指向这个地址,而且在栈中这个地址旁边记下这个引用的对象o。如果已经有了值为"abc"的地址,则查找对象o,并返回o的地址。
(3)将str指向对象o的地址。
值得注意的是,一般String类中字符串值都是直接存值的。但像String str = "abc";这种场合下,其字符串值却是保存了一个指向存在栈中数据的引用!
为了更好地说明这个问题,我们可以通过以下的几个代码进行验证。
String str1 = "abc";
String str2 = "abc";
System.out.println(str1==str2); //true
注意,我们这里并不用str1.equals(str2);的方式,因为这将比较两个字符串的值是否相等。==号,根据JDK的说明,只有在两个引用都指向了同一个对象时才返回真值。而我们在这里要看的是,str1与str2是否都指向了同一个对象。
结果说明,JVM创建了两个引用str1和str2,但只创建了一个对象,而且两个引用都指向了这个对象。
我们再来更进一步,将以上代码改成:
String str1 = "abc";
String str2 = "abc";
str1 = "bcd";
System.out.println(str1 + "," + str2); //bcd, abc
System.out.println(str1==str2); //false
这就是说,赋值的变化导致了类对象引用的变化,str1指向了另外一个新对象!而str2仍旧指向原来的对象。上例中,当我们将str1 的值改为"bcd"时,JVM发现在栈中没有存放该值的地址,便开辟了这个地址,并创建了一个新的对象,其字符串的值指向这个地址。
事实上,String类被设计成为不可改变(immutable)的类。如果你要改变其值,可以,但JVM在运行时根据新值悄悄创建了一个新对象,然后将这个对象的地址返回给原来类的引用。这个创建过程虽说是完全自动进行的,但它毕竟占用了更多的时间。在对时间要求比较敏感的环境中,会带有一定的不良影响。
再修改原来代码:
String str1 = "abc";
String str2 = "abc";
str1 = "bcd";
String str3 = str1;
System.out.println(str3); //bcd
String str4 = "bcd";
System.out.println(str1 == str4); //true
str3 这个对象的引用直接指向str1所指向的对象(注意,str3并没有创建新对象)。当 str1改完其值后,再创建一个 String 的引用 str4,并指向因 str1 修改值而创建的新的对象。可以发现,这回 str4 也没有创建新的对象,从而再次实现栈中数据的共享。
我们再接着看以下的代码。
String str1 = new String("abc");
String str2 = "abc";
System.out.println(str1==str2); //false
创建了两个引用。创建了两个对象。两个引用分别指向不同的两个对象。
以上两段代码说明,只要是用new()来新建对象的,都会在堆中创建,而且其字符串是单独存值的,即使与栈中的数据相同,也不会与栈中的数据共享。
6). 数据类型包装类的值不可修改。不仅仅是 String 类的值不可修改,所有的数据类型包装类都不能更改其内部的值。
7). 结论与建议:
(1)我们在使用诸如String str = "abc";的格式定义类时,总是想当然地认为,我们创建了String类的对象str。担心陷阱!对象可能并没有被创建!唯一可以肯定的是,指向 String类的引用被创建了。至于这个引用到底是否指向了一个新的对象,必须根据上下文来考虑,除非你通过new()方法来显要地创建一个新的对象。因此,更为准确的说法是,我们创建了一个指向 String类的对象的引用变量str,这个对象引用变量指向了某个值为"abc"的 String 类。清醒地认识到这一点对排除程序中难以发现的bug是很有帮助的。
(2)使用String str = "abc";的方式,可以在一定程度上提高程序的运行速度,因为JVM会自动根据栈中数据的实际情况来决定是否有必要创建新对象。而对于String str = new String("abc");的代码,则一概在堆中创建新对象,而不管其字符串值是否相等,是否有必要创建新对象,从而加重了程序的负担。这个思想应该是享元模式的思想,但JDK的内部在这里实现是否应用了这个模式,不得而知。
(3)当比较包装类里面的数值是否相等时,用equals()方法;当测试两个包装类的引用是否指向同一个对象时,用==。
(4)由于String类的immutable性质,当String变量需要经常变换其值时,应该考虑使用StringBuffer类,以提高程序效率。 如果java不能成功分配heap的空间,将抛出OutOfMemoryError。
以上是 Java中heap(堆)和stack(栈)的区别 的全部内容, 来源链接: utcz.com/z/393212.html