Java-泛型

在前面我们学习了最重要的类和对象,了解了面向对象编程的思想,注意,非常重要,面向对象是必须要深入理解和掌握的内容,不能草草结束。在本章节,我们会继续深入了解,从我们的泛型开始,再到我们的数据结构,最后再开始我们的集合类学习。
走进泛型
为了统计学生成绩,要求设计一个Score对象,包括课程名称、课程号、课程成绩,但是成绩分为两种,一种是以优秀、良好、合格 来作为结果,还有一种就是 60.0、75.5、92.5 这样的数字分数,那么现在该如何去设计这样的一个Score类呢?现在的问题就是,成绩可能是String类型,也可能是Integer类型,如何才能很好的去存可能出现的两种类型呢?
public class Score { String name;
String id;
Object score; //因为Object是所有类型的父类,因此既可以存放Integer也能存放String
public Score(String name, String id, Object score) {
this.name = name;
this.id = id;
this.score = score;
}
}
以上的方法虽然很好地解决了多种类型存储问题,但是Object类型在编译阶段并不具有良好的类型判断能力,很容易出现以下的情况:
public static void main(String[] args) { Score score = new Score("数据结构与算法基础", "EP074512", "优秀"); //是String类型的
//....
Integer number = (Integer) score.score; //获取成绩需要进行强制类型转换,虽然并不是一开始的类型,但是编译不会报错
}
//运行时出现异常!
Exception in thread "main" java.lang.ClassCastException: java.lang.String cannot be cast to java.lang.Integer
at com.test.Main.main(Main.java:14)
使用Object类型作为引用,取值只能进行强制类型转换,显然无法在编译期确定类型是否安全,项目中代码量非常之大,进行类型比较又会导致额外的开销和增加代码量,如果不经比较就很容易出现类型转换异常,代码的健壮性有所欠缺!(此方法虽然可行,但并不是最好的方法)
为了解决以上问题,JDK1.5新增了泛型,它能够在编译阶段就检查类型安全,大大提升开发效率。
public class Score<T> { //将Score转变为泛型类<T> String name;
String id;
T score; //T为泛型,根据用户提供的类型自动变成对应类型
public Score(String name, String id, T score) { //提供的score类型即为T代表的类型
this.name = name;
this.id = id;
this.score = score;
}
}
public static void main(String[] args) { //直接确定Score的类型是字符串类型的成绩
Score<String> score = new Score<String>("数据结构与算法基础", "EP074512", "优秀");
Integer i = score.score; //编译不通过,因为成员变量score类型被定为String!
}
泛型将数据类型的确定控制在了编译阶段,在编写代码的时候就能明确泛型的类型!如果类型不符合,将无法通过编译!
泛型本质上也是一个语法糖(并不是JVM所支持的语法,编译后会转成编译器支持的语法,比如之前的foreach就是),在编译后会被擦除,变回上面的Object类型调用,但是类型转换由编译器帮我们完成,而不是我们自己进行转换(安全)
//反编译后的代码public static void main(String[] args) {
Score score = new Score("数据结构与算法基础", "EP074512", "优秀");
String i = (String)score.score; //其实依然会变为强制类型转换,但是这是由编译器帮我们完成的
}
像这样在编译后泛型的内容消失转变为Object的情况称为类型擦除(重要,需要完全理解),所以泛型只是为了方便我们在编译阶段确定类型的一种语法而已,并不是JVM所支持的。
综上,泛型其实就是一种类型参数,用于指定类型。
泛型的使用
泛型类
上一节我们已经提到泛型类的定义,实际上就是普通的类多了一个类型参数,也就是在使用时需要指定具体的泛型类型。泛型的名称一般取单个大写字母,比如T代表Type,也就是类型的英文单词首字母,当然也可以添加数字和其他的字符。
public class Score<T> { //将Score转变为泛型类<T> String name;
String id;
T score; //T为泛型,根据用户提供的类型自动变成对应类型
public Score(String name, String id, T score) { //提供的score类型即为T代表的类型
this.name = name;
this.id = id;
this.score = score;
}
}
在一个普通类型中定义泛型,泛型T称为参数化类型,在定义泛型类的引用时,需要明确指出类型:
Score<String> score = new Score<String>("数据结构与算法基础", "EP074512", "优秀");此时类中的泛型T已经被替换为String了,在我们获取此对象的泛型属性时,编译器会直接告诉我们类型:
Integer i = score.score; //编译不通过,因为成员变量score明确为String类型注意,泛型只能用于对象属性,也就是非静态的成员变量才能使用:
static T score; //错误,不能在静态成员上定义由此可见,泛型是只有在创建对象后编译器才能明确泛型类型,而静态类型是类所具有的属性,不足以使得编译器完成类型推断。
泛型无法使用基本类型,如果需要基本类型,只能使用基本类型的包装类进行替换!
Score<double> score = new Score<double>("数据结构与算法基础", "EP074512", 90.5); //编译不通过那么为什么泛型无法使用基本类型呢?回想上一节提到的类型擦除,其实就很好理解了。由于JVM没有泛型概念,因此泛型最后还是会被编译器编译为Object,并采用强制类型转换的形式进行类型匹配,而我们的基本数据类型和引用类型之间无法进行类型转换,所以只能使用基本类型的包装类来处理。
类的泛型方法
泛型方法的使用也很简单,我们只需要把它当做一个未知的类型来使用即可:
public T getScore() { //若方法的返回值类型为泛型,那么编译器会自动进行推断 return score;
}
public void setScore(T score) { //若方法的形式参数为泛型,那么实参只能是定义时的类型
this.score = score;
}
Score<String> score = new Score<String>("数据结构与算法基础", "EP074512", "优秀");score.setScore(10); //编译不通过,因为只接受String类型
同样地,静态方法无法直接使用类定义的泛型(注意是无法直接使用,静态方法可以使用泛型)
自定义泛型方法
那么如果我想在静态方法中使用泛型呢?首先我们要明确之前为什么无法使用泛型,因为之前我们的泛型定义是在类上的,只有明确具体的类型才能开始使用,也就是创建对象时完成类型确定,但是静态方法不需要依附于对象,那么只能在使用时再来确定了,所以静态方法可以使用泛型,但是需要单独定义:
public static <E> void test(E e){ //在方法定义前声明泛型 System.out.println(e);
}
同理,成员方法也能自行定义泛型,在实际使用时再进行类型确定:
public <E> void test(E e){ System.out.println(e);
}
其实,无论是泛型类还是泛型方法,再使用时一定要能够进行类型推断,明确类型才行。
注意一定要区分类定义的泛型和方法前定义的泛型!
泛型引用
可以看到我们在定义一个泛型类的引用时,需要在后面指出此类型:
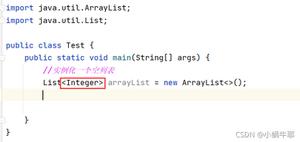
Score<Integer> score; //声明泛型为Integer类型如果不希望指定类型,或是希望此引用类型可以引用任意泛型的Score类对象,可以使用?通配符,来表示自动匹配任意的可用类型:
Score<?> score; //score可以引用任意的Score类型对象了!那么使用通配符之后,得到的泛型成员变量会是什么类型呢?
Object o = score.getScore(); //只能变为Object因为使用了通配符,编译器就无法进行类型推断,所以只能使用原始类型。
在学习了泛型的界限后,我们还会继续了解通配符的使用。
泛型的界限
现在有一个新的需求,现在没有String类型的成绩了,但是成绩依然可能是整数,也可能是小数,这时我们不希望用户将泛型指定为除数字类型外的其他类型,我们就需要使用到泛型的上界定义:
public class Score<T extends Number> { //设定泛型上界,必须是Number的子类 private final String name;
private final String id;
private T score;
public Score(String name, String id, T score) {
this.name = name;
this.id = id;
this.score = score;
}
public T getScore() {
return score;
}
}
通过extends关键字进行上界限定,只有指定类型或指定类型的子类才能作为类型参数。
同样的,泛型通配符也支持泛型的界限:
Score<? extends Number> score; //限定为匹配Number及其子类的类型同理,既然泛型有上限,那么也有下限:
Score<? super Integer> score; //限定为匹配Integer及其父类通过super关键字进行下界限定,只有指定类型或指定类型的父类才能作为类型参数。
图解如下:
那么限定了上界后,我们再来使用这个对象的泛型成员,会变成什么类型呢?
Score<? extends Number> score = new Score<>("数据结构与算法基础", "EP074512", 10);Number o = score.getScore(); //得到的结果为上界类型
也就是说,一旦我们指定了上界后,编译器就将范围从原始类型Object提升到我们指定的上界Number,但是依然无法明确具体类型。思考:那如果定义下限呢?
那么既然我们可以给泛型类限定上界,现在我们来看编译后结果呢:
//使用javap -l 进行反编译public class com.test.Score<T extends java.lang.Number> {
public com.test.Score(java.lang.String, java.lang.String, T);
LineNumberTable:
line 8: 0
line 9: 4
line 10: 9
line 11: 14
line 12: 19
LocalVariableTable:
Start Length Slot Name Signature
0 20 0 this Lcom/test/Score;
0 20 1 name Ljava/lang/String;
0 20 2 id Ljava/lang/String;
0 20 3 score Ljava/lang/Number; //可以看到score的类型直接被编译为Number类
public T getScore();
LineNumberTable:
line 15: 0
LocalVariableTable:
Start Length Slot Name Signature
0 5 0 this Lcom/test/Score;
}
因此,一旦确立上限后,编译器会自动将类型提升到上限类型。
钻石运算符
我们发现,每次创建泛型对象都需要在前后都标明类型,但是实际上后面的类型声明是可以去掉的,因为我们在传入参数时或定义泛型类的引用时,就已经明确了类型,因此JDK1.7提供了钻石运算符来简化代码:
Score<Integer> score = new Score<Integer>("数据结构与算法基础", "EP074512", 10); //1.7之前Score<Integer> score = new Score<>("数据结构与算法基础", "EP074512", 10); //1.7之后
泛型与多态
泛型不仅仅可以可以定义在类上,同时也能定义在接口上:
public interface ScoreInterface<T> { T getScore();
void setScore(T t);
}
当实现此接口时,我们可以选择在实现类明确泛型类型或是继续使用此泛型,让具体创建的对象来确定类型。
public class Score<T> implements ScoreInterface<T>{ //将Score转变为泛型类<T> private final String name;
private final String id;
private T score;
public Score(String name, String id, T score) {
this.name = name;
this.id = id;
this.score = score;
}
public T getScore() {
return score;
}
@Override
public void setScore(T score) {
this.score = score;
}
}
public class StringScore implements ScoreInterface<String>{ //在实现时明确类型 @Override
public String getScore() {
return null;
}
@Override
public void setScore(String s) {
}
}
抽象类同理,这里就不多做演示了。
多态类型擦除
思考一个问题,既然继承后明确了泛型类型,那么为什么@Override不会出现错误呢,重写的条件是需要和父类的返回值类型、形式参数一致,而泛型默认的原始类型是Object类型,子类明确后变为Number类型,这显然不满足重写的条件,但是为什么依然能编译通过呢?
class A<T>{ private T t;
public T get(){
return t;
}
public void set(T t){
this.t=t;
}
}
class B extends A<Number>{
private Number n;
@Override
public Number get(){ //这并不满足重写的要求,因为只能重写父类同样返回值和参数的方法,但是这样却能够通过编译!
return t;
}
@Override
public void set(Number t){
this.t=t;
}
}
通过反编译进行观察,实际上是编译器帮助我们生成了两个桥接方法用于支持重写:
@Overridepublic Object get(){
return this.get();//调用返回Number的那个方法
}
@Override
public void set(Object t ){
this.set((Number)t ); //调用参数是Number的那个方法
}
以上是 Java-泛型 的全部内容, 来源链接: utcz.com/z/393162.html