Java中HashTable和HashMap

转载:https://zhuanlan.zhihu.com/p/26817483
首先介绍一下HashTable和HashMap的区别:
1.HashMap是非线程安全的,HashTable是线程安全的;(线程安全就是线程同步的意思,就是当一个程序对一个线程安全的方法或者语句进行访问的时候,其他的不能再对他进行操作了,必须等到这次访问结束以后才能对这个线程安全的方法进行访问)
2.HashMap的键或值都允许有null,而HashTable则不行。
3.因为线程安全的问题, HashMap要比HashTable效率高一点。
一、HashMap的内部存储结构
下面介绍一下HashMap,转载自其他帖子:
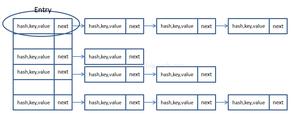
Java中数据存储方式最底层的两种结构,一种是数组,另一种就是链表,数组的特点:连续空间,寻址迅速,但是在删除或者添加元素的时候需要有较大幅度的移动,所以查询速度快,增删较慢。而链表正好相反,由于空间不连续,寻址困难,增删元素只需修改指针,所以查询慢、增删快。有没有一种数据结构来综合一下数组和链表,以便发挥他们各自的优势?答案是肯定的!就是:哈希表。哈希表具有较快(常量级)的查询速度,及相对较快的增删速度,所以很适合在海量数据的环境中使用。一般实现哈希表的方法采用“拉链法”,我们可以理解为“链表的数组”,如下图:
从上图中,我们可以发现哈希表是由数组+链表组成的,一个长度为16的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则存储到数组中呢。一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。比如上述哈希表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。它的内部其实是用一个Entity数组来实现的,属性有key、value、next。
1.初始化
默认就是开辟16个大小的空间。
2.put(key,value)操作
当调用put操作时,首先判断key是否为null.
如果key是null,获取Entry的第一个元素table[0],并基于第一个元素的next属性开始遍历,直到找到key为null的Entry,将其value设置为新的value值。如果没有找到key为null的元素,则调用如上述代码的addEntry(0, null, value, 0);增加一个新的entry
如果key不为null,首先会进行key.hashCode()操作,获取key的哈希值,hashCode()是Object类的一个方法,为本地方法,内部实现比较复杂,函数中int i = indexFor(hash, table.length);的意思,相当于int i = hash % Entry[].length;得到i后,就是在Entry数组中的位置。
上面我们提到过Entry类里面有一个next属性,作用是指向下一个Entry。如, 第一个键值对A进来,通过计算其key的hash得到的i=0,记做:Entry[0] = A。一会后又进来一个键值对B,通过计算其i也等于0,现在怎么办?HashMap会这样做:B.next = A,Entry[0] = B,如果又进来C,i也等于0,那么C.next = B,Entry[0] = C;这样我们发现i=0的地方其实存取了A,B,C三个键值对,他们通过next这个属性链接在一起,也就是说数组中存储的是最后插入的元素。
3.get(Object key)操作
get(Object key)操作时根据键来获取值,如果了解了put操作,get操作容易理解
1、当key为null时,调用getForNullKey()。
2、当key不为null时,先根据hash函数得到hash值,在更具indexFor()得到i的值,循环遍历链表,如果有:key值等于已存在的key值,则返回其value。
二、HashTable的内部储存结构
HashTable和HashMap采用相同的存储机制,二者的实现基本一致,不同的是:
1、HashMap是非线程安全的,HashTable是线程安全的,内部的方法基本都是synchronized。
2、HashTable不允许有null值的存在。
在HashTable中调用put方法时,如果key为null,直接抛出NullPointerException。其它细微的差别还有,比如初始化Entry数组的大小等等,但基本思想和HashMap一样。
三、HashTable和ConcurrentHashMap的比较
如果面试的时候能够答出HashMap和HashTable的上述3个区别,简单的面试算是过了。如果在问Java中的另一个线程安全的与HashMap及其类似的类是什么?同样是线程安全,它与HashTable在线程同步上有什么不同?能把第二个问题完整的答出来,说明你的基础算是不错的了。
这个类就是我们要讲的ConcurrentHashMap类:
ConcurrentHashMap是线程安全的HashMap的实现。是线程安全的类。
synchronized关键字加锁的原理,其实是对对象加锁,不论你是在方法前加synchronized还是语句块前加,锁住的都是对象整体,但是ConcurrentHashMap的同步机制和这个不同,它不是加synchronized关键字,而是基于lock操作的,这样的目的是保证同步的时候,锁住的不是整个对象。
1、构造方法
为了容易理解,我们先从构造函数说起。ConcurrentHashMap是基于一个叫Segment数组的,其实和Entry类似
2、put操作
与HashMap不同的是,如果key为null,直接抛出NullPointer异常,之后,同样先计算hashCode的值,再计算hash值,不过此处hash函数和HashMap中的不一样:
以上是 Java中HashTable和HashMap 的全部内容, 来源链接: utcz.com/z/393099.html