Hadoop日记Day9---HDFS的java访问接口

我们在工作中写完的各种代码是在服务器中运行的,HDFS 的操作代码也不例外。在开发阶段,我们使用windows 下的eclipse 作为开发环境,访问运行在虚拟机中的HDFS。也就是通过在本地的eclipse 中的java 代码访问远程linux 中的hdfs。
要使用宿主机中的java 代码访问客户机中的hdfs,需要保证以下几点:
(1)确保宿主机与客户机的网络是互通的
(2)确保宿主机和客户机的防火墙都关闭,因为很多端口需要通过,为了减少防火墙配置,直接关闭.
(3)确保宿主机与客户机使用的jdk 版本一致。如果客户机为jdk6,宿主机为jdk7,那么代码运行时会报不支持的版本的错误。
(4)宿主机的登录用户名必须与客户机的用户名一直。比如我们linux 使用的是root 用户,那么windows 也要使用root 用户,否则会报权限异常
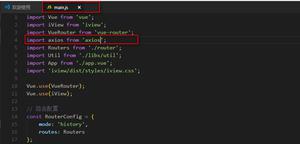
在eclipse 项目中覆盖hadoop 的org.apache.hadoop.fs.FileUtil 类的checkReturnValue 方法,如图1.1,目的是为了避免权限错误。
图1.1
如果读者在开发过程中出现权限等问题,请按照本节的提示检查自己的环境。
二、使用FileSystem api 读写数据
在hadoop 的HDFS 操作中,有个非常重要的api,是org.apache.hadoop.fs.FileSystem,这是我们用户代码操作HDFS 的直接入口,该类含有操作HDFS 的各种方法,类似于jdbc 中操作数据库的直接入口是Connection 类。
那我们怎么获得一个FileSystem 对象?
1 String uri = "hdfs://10.1.14.24:9000/";2 Configuration conf = new Configuration();
3 FileSystem fs = FileSystem.get(URI.create(uri), conf);
View Code
以上代码中,要注意调用的是FileSystem 的静态方法get,传递两个值给形式参数,第一个访问的HDFS 地址,该地址的协议是hdfs,ip 是10.1.14.24,端口是9000。这个地址的完整信息是在配置文件core-site.xml 中指定的,读者可以使用自己环境的配置文件中的设置。第二个参数是一个配置对象。
1. 创建文件夹
使用HDFS 的shell 命令查看一下根目录下的文件情况,如图2.1所示。
图2.1
我们在HDFS 的根目录下创建文件夹,代码如下
------------------------------------------------------------------------------------------------------
final String pathString = "/d1";
boolean exists = fs.exists(new Path(pathString));
if(!exists){
boolean result = fs.mkdirs(new Path(pathString));
System.out.println(result);
}
------------------------------------------------------------------------------------------------------
以上代码中要放在Main函数中,
- 第一行决定创建的文件夹完整路径是“/d1”。
- 第二行代码是使用方法exitst判断文件夹是否存在;如果不存在,执行创建操作。
- 第三行创建文件夹,调用的是mkdirs 方法,返回值是布尔值,如果是true,表示创建成功;如果是false,表示创建失败。
现在查看一下是否成功了,如图3.2,3.3可见创建成功了。
图3.2
图 3.3
2. 写文件
我们可以向HDFS 写入文件,代码如下:
-----------------------------------------------------------------------------------------------------
final String pathString = "/d1/f1";
final FSDataOutputStream fsDataOutputStream = fs.create(new Path(pathString));//写出去
IOUtils.copyBytes(new ByteArrayInputStream("my name is Sunddenly".getBytes()),
fsDataOutputStream, conf, true);
------------------------------------------------------------------------------------------------------
第一行代码表示创建的文件是在刚才创建的d1 文件夹下的文件f1;
第二行是调用create 方法创建一个通向HDFS 的输出流;
第三行是通过调用hadoop 的一个工具类IOUtils 的静态方法copyBytes 把一个字符串发送给输出流中。
该静态方法有四个参数:
- 第一个参数输入流。
- 第二个参数是输出流。
- 第三个参数是配置对象。
- 第四个参数是布尔值,如果是true 表示数据传输完毕后关闭流。
现在看一下是否创建成功了,如图3.4所示。
图3.4
3. 读文件
现在我们把刚才写入到HDFS 的文件“/d1/f1”读出来,代码如下:
------------------------------------------------------------------------------------------------------
final String pathString = "/d1/f1";
final FSDataInputStream fsDataInputStream = fs.open(new Path(pathString));//读进来
IOUtils.copyBytes(fsDataInputStream, System.out, conf, true);
-------------------------------------------------------------------------------------------------------
- 第一行指定所读文件的路径。
- 第二行表示调用方法open 打开一个指定的文件,返回值是一个通向该文件的输入流;
- 第三行还是调用IOUtils.copyBytes 方法,输出的目的地是控制台。
见图3.5
图3.5
4. 查看目录列表和文件详细信息
我们可以把根目录下的所有文件和目录显示出来,代码如下
--------------------------------------------------------------------------------------------------------
final String pathString = "/";
final FileStatus[] listStatus = fs.listStatus(new Path(pathString));
for (FileStatus fileStatus : listStatus) {
final String type = fileStatus.isDir()?"目录":"文件";
final short replication = fileStatus.getReplication();
final String permission = fileStatus.getPermission() .toString();
final long len = fileStatus.getLen();
final Path path = fileStatus.getPath();
System.out.println(type+"\t"+permission+"\t"+replication+"\t"+len+"\t"+path);
}
-----------------------------------------------------------------------------------------------------------
调用listStatus方法会得到一个指定路径下的所有文件和文件夹,每一个用FileStatus表示。我们使用for循环显示每一个FileStatus对象。FileStatus对象表示文件的详细信息,里面含有类型、副本数、权限、长度、路径等很多信息,我们只是显示了一部分。结果如图3.6所示。
图 3.6
5. 删除文件或目录
我们可以删除某个文件或者路径,代码如下
-----------------------------------------------------------------------------------------------------
final String pathString = "/d1/f1";
//fs.delete(new Path("/d1"), true);
fs.deleteOnExit(new Path(pathString));
-----------------------------------------------------------------------------------------------------
第三行代码表示删除文件“/d1/f1”,注释掉的第二行代码表示递归删除目录“/d1”及下面的所有内容。除了上面列出的fs 的方法外,还有很多方法,请读者自己查阅api。
以上是 Hadoop日记Day9---HDFS的java访问接口 的全部内容, 来源链接: utcz.com/z/392787.html